Frame Interpolation with Consecutive Brownian Bridge Diffusion
2405.05953
0
0
🤷
Abstract
Recent work in Video Frame Interpolation (VFI) tries to formulate VFI as a diffusion-based conditional image generation problem, synthesizing the intermediate frame given a random noise and neighboring frames. Due to the relatively high resolution of videos, Latent Diffusion Models (LDMs) are employed as the conditional generation model, where the autoencoder compresses images into latent representations for diffusion and then reconstructs images from these latent representations. Such a formulation poses a crucial challenge: VFI expects that the output is deterministically equal to the ground truth intermediate frame, but LDMs randomly generate a diverse set of different images when the model runs multiple times. The reason for the diverse generation is that the cumulative variance (variance accumulated at each step of generation) of generated latent representations in LDMs is large. This makes the sampling trajectory random, resulting in diverse rather than deterministic generations. To address this problem, we propose our unique solution: Frame Interpolation with Consecutive Brownian Bridge Diffusion. Specifically, we propose consecutive Brownian Bridge diffusion that takes a deterministic initial value as input, resulting in a much smaller cumulative variance of generated latent representations. Our experiments suggest that our method can improve together with the improvement of the autoencoder and achieve state-of-the-art performance in VFI, leaving strong potential for further enhancement.
Create account to get full access
Overview
- This research paper explores a new approach to Video Frame Interpolation (VFI) using diffusion-based conditional image generation models.
- VFI aims to synthesize intermediate frames between neighboring video frames, which is important for applications like high frame rate video playback.
- The paper proposes a solution called "Frame Interpolation with Consecutive Brownian Bridge Diffusion" to address challenges with using Latent Diffusion Models (LDMs) for VFI.
- LDMs can generate diverse images, but VFI requires deterministic output matching the ground truth intermediate frame.
- The proposed method uses a Brownian Bridge diffusion process to reduce the cumulative variance of the generated latent representations, leading to more deterministic and accurate interpolations.
Plain English Explanation
Video Frame Interpolation (VFI) is a technique used to generate intermediate frames between existing video frames. This can be helpful for creating smoother, higher frame rate videos, which is important for applications like video playback and visual effects. Recent work has tried to tackle VFI using a type of AI model called a Latent Diffusion Model (LDM).
LDMs work by first compressing video frames into a more compact "latent" representation, then using a diffusion process to generate new images from that latent space. The advantage of this approach is that it can create high-quality, diverse images. However, the downside is that the diffusion process also introduces a lot of randomness, meaning the output may not match the exact ground truth intermediate frame that is expected for VFI.
To address this, the researchers propose a new method called "Frame Interpolation with Consecutive Brownian Bridge Diffusion." The key idea is to use a special type of diffusion process, called a Brownian Bridge, that starts and ends at specific points. This results in a much smaller amount of randomness in the generated latent representations, leading to output that more closely matches the expected ground truth.
The researchers show that this approach can achieve state-of-the-art performance on VFI benchmarks, and they see potential for even further improvements by continuing to refine the underlying autoencoder that compresses the video frames. Overall, this work represents an important step forward in using powerful diffusion-based models for the specific task of video frame interpolation.
Technical Explanation
The paper formulates Video Frame Interpolation (VFI) as a diffusion-based conditional image generation problem. Latent Diffusion Models (LDMs) are employed as the conditional generation model, where an autoencoder compresses video frames into latent representations for diffusion and then reconstructs the frames from these latent representations.
However, this approach poses a crucial challenge: VFI expects the output to deterministically match the ground truth intermediate frame, but LDMs randomly generate a diverse set of different images when run multiple times. This is because the cumulative variance (the variance accumulated at each generation step) of the generated latent representations in LDMs is large, making the sampling trajectory random and leading to diverse rather than deterministic generations.
To address this problem, the paper proposes "Frame Interpolation with Consecutive Brownian Bridge Diffusion." Specifically, the method uses a consecutive Brownian Bridge diffusion process that takes a deterministic initial value as input, resulting in a much smaller cumulative variance of the generated latent representations. This allows the model to more accurately and deterministically generate the expected intermediate frame.
The experimental results suggest that this approach can improve performance on VFI benchmarks, particularly when combined with improvements to the underlying autoencoder. The authors see strong potential for further enhancements to this diffusion-based approach to VFI.
Critical Analysis
The paper presents a novel and interesting solution to the challenge of using diffusion-based models for the specific task of Video Frame Interpolation (VFI). By employing a Brownian Bridge diffusion process, the method is able to reduce the cumulative variance of the generated latent representations, leading to more deterministic and accurate interpolations.
One potential limitation mentioned in the paper is that the performance of the proposed approach is still dependent on the quality of the underlying autoencoder used to compress the video frames. Further improvements to the autoencoder could lead to even better VFI results. Additionally, the paper does not provide a detailed analysis of the computational complexity or inference time of the proposed method, which could be an important consideration for real-world applications.
It would also be interesting to see how this diffusion-based VFI approach compares to other recent techniques, such as semantically consistent video inpainting using conditional diffusion models. A more thorough comparison to the state-of-the-art in VFI could help to further contextualize the contributions of this work.
Overall, the research presented in this paper represents an important step forward in leveraging the power of diffusion-based models for the specific task of Video Frame Interpolation. The proposed solution addresses a key challenge in this domain and demonstrates the potential for further advancements in this area.
Conclusion
This research paper explores a novel approach to Video Frame Interpolation (VFI) using diffusion-based conditional image generation models. The key innovation is the use of a consecutive Brownian Bridge diffusion process to reduce the cumulative variance of the generated latent representations, allowing for more deterministic and accurate interpolations compared to standard Latent Diffusion Models.
The experimental results suggest that this approach can achieve state-of-the-art performance on VFI benchmarks, with further potential for improvement by continued refinement of the underlying autoencoder. This work represents an important advancement in the use of powerful diffusion-based models for the specific task of video frame interpolation, with promising implications for applications that require high-quality, smooth video playback.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
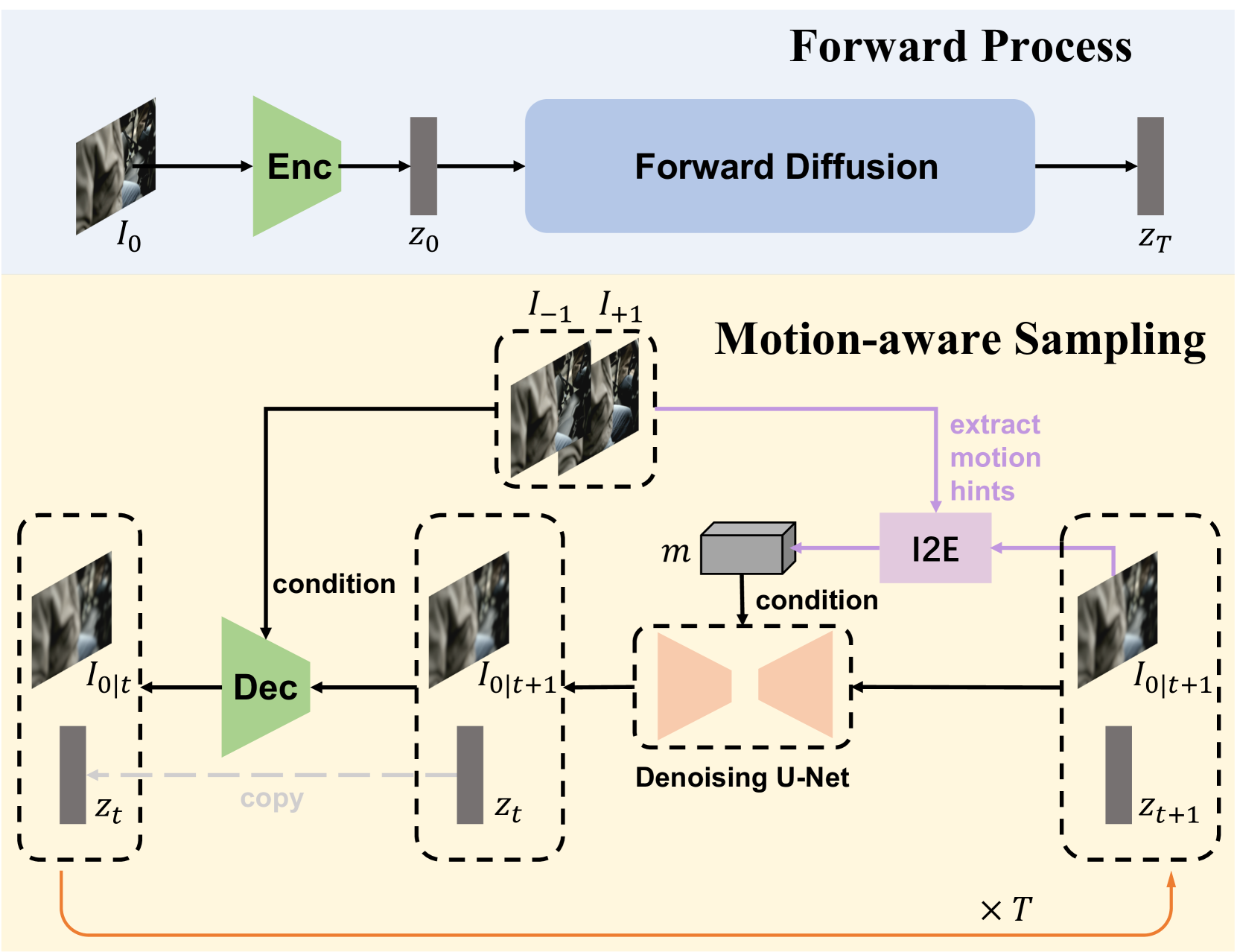
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Zhilin Huang, Yijie Yu, Ling Yang, Chujun Qin, Bing Zheng, Xiawu Zheng, Zikun Zhou, Yaowei Wang, Wenming Yang
0
0
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
6/5/2024

FIFO-Diffusion: Generating Infinite Videos from Text without Training
Jihwan Kim, Junoh Kang, Jinyoung Choi, Bohyung Han
0
0
We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without additional training. This is achieved by iteratively performing diagonal denoising, which concurrently processes a series of consecutive frames with increasing noise levels in a queue; our method dequeues a fully denoised frame at the head while enqueuing a new random noise frame at the tail. However, diagonal denoising is a double-edged sword as the frames near the tail can take advantage of cleaner ones by forward reference but such a strategy induces the discrepancy between training and inference. Hence, we introduce latent partitioning to reduce the training-inference gap and lookahead denoising to leverage the benefit of forward referencing. Practically, FIFO-Diffusion consumes a constant amount of memory regardless of the target video length given a baseline model, while well-suited for parallel inference on multiple GPUs. We have demonstrated the promising results and effectiveness of the proposed methods on existing text-to-video generation baselines. Generated video samples and source codes are available at our project page.
6/13/2024
🖼️
BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models
Fengyuan Shi, Jiaxi Gu, Hang Xu, Songcen Xu, Wei Zhang, Limin Wang
0
0
Diffusion models have made tremendous progress in text-driven image and video generation. Now text-to-image foundation models are widely applied to various downstream image synthesis tasks, such as controllable image generation and image editing, while downstream video synthesis tasks are less explored for several reasons. First, it requires huge memory and computation overhead to train a video generation foundation model. Even with video foundation models, additional costly training is still required for downstream video synthesis tasks. Second, although some works extend image diffusion models into videos in a training-free manner, temporal consistency cannot be well preserved. Finally, these adaption methods are specifically designed for one task and fail to generalize to different tasks. To mitigate these issues, we propose a training-free general-purpose video synthesis framework, coined as {bf BIVDiff}, via bridging specific image diffusion models and general text-to-video foundation diffusion models. Specifically, we first use a specific image diffusion model (e.g., ControlNet and Instruct Pix2Pix) for frame-wise video generation, then perform Mixed Inversion on the generated video, and finally input the inverted latents into the video diffusion models (e.g., VidRD and ZeroScope) for temporal smoothing. This decoupled framework enables flexible image model selection for different purposes with strong task generalization and high efficiency. To validate the effectiveness and general use of BIVDiff, we perform a wide range of video synthesis tasks, including controllable video generation, video editing, video inpainting, and outpainting.
4/10/2024
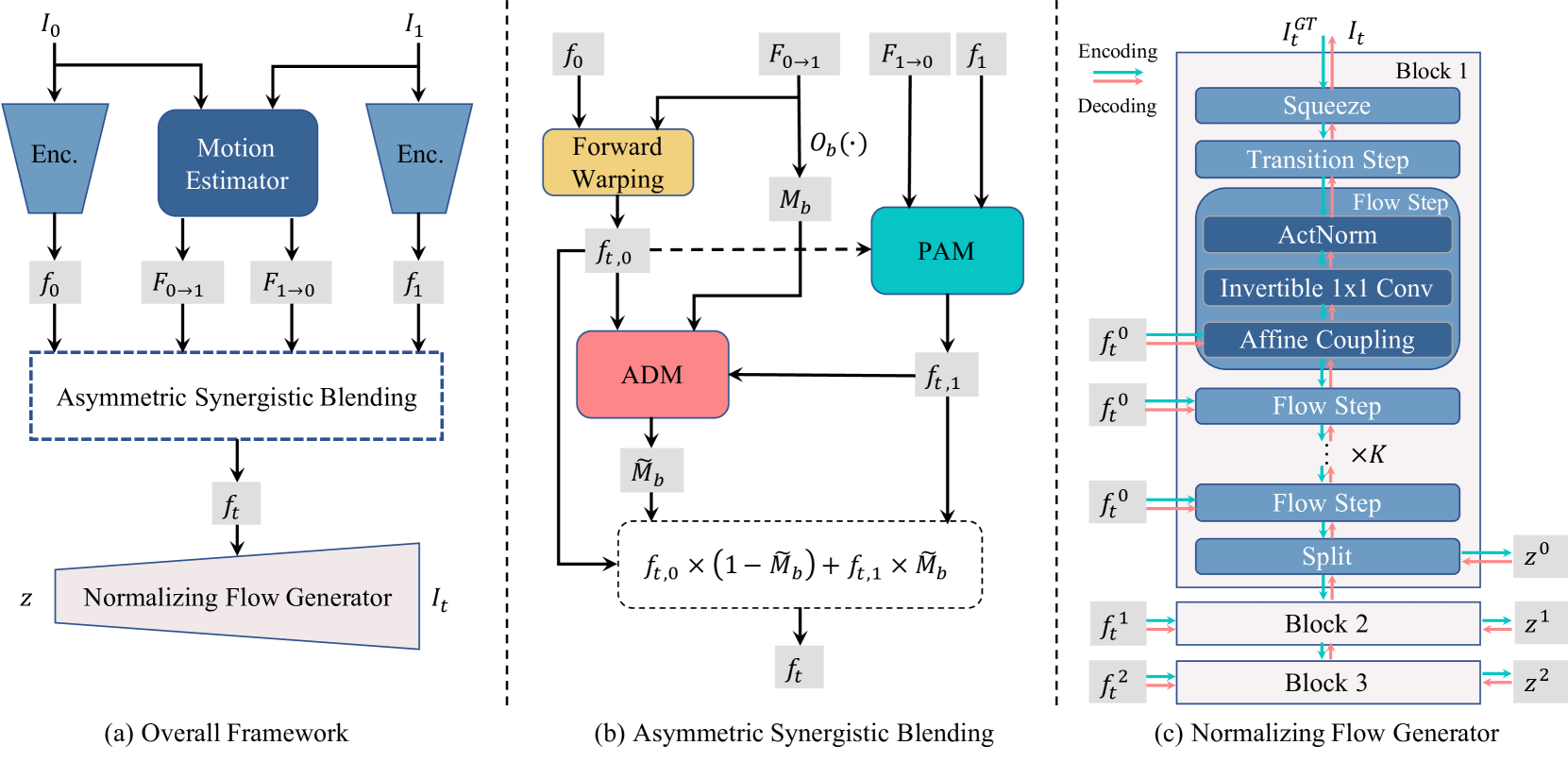
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Guangyang Wu, Xin Tao, Changlin Li, Wenyi Wang, Xiaohong Liu, Qingqing Zheng
0
0
Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at url{https://github.com/mulns/PerVFI}
4/11/2024