FreeMan: Towards Benchmarking 3D Human Pose Estimation under Real-World Conditions
2309.05073
0
0
👀
Abstract
Estimating the 3D structure of the human body from natural scenes is a fundamental aspect of visual perception. 3D human pose estimation is a vital step in advancing fields like AIGC and human-robot interaction, serving as a crucial technique for understanding and interacting with human actions in real-world settings. However, the current datasets, often collected under single laboratory conditions using complex motion capture equipment and unvarying backgrounds, are insufficient. The absence of datasets on variable conditions is stalling the progress of this crucial task. To facilitate the development of 3D pose estimation, we present FreeMan, the first large-scale, multi-view dataset collected under the real-world conditions. FreeMan was captured by synchronizing 8 smartphones across diverse scenarios. It comprises 11M frames from 8000 sequences, viewed from different perspectives. These sequences cover 40 subjects across 10 different scenarios, each with varying lighting conditions. We have also established an semi-automated pipeline containing error detection to reduce the workload of manual check and ensure precise annotation. We provide comprehensive evaluation baselines for a range of tasks, underlining the significant challenges posed by FreeMan. Further evaluations of standard indoor/outdoor human sensing datasets reveal that FreeMan offers robust representation transferability in real and complex scenes. Code and data are available at https://wangjiongw.github.io/freeman.
Create account to get full access
Overview
- Estimating the 3D structure of the human body from natural scenes is a fundamental aspect of visual perception.
- 3D human pose estimation is vital for fields like AIGC and human-robot interaction, helping understand and interact with human actions in real-world settings.
- Current datasets are limited, often collected in single lab conditions using complex equipment, hindering progress on this crucial task.
Plain English Explanation
Figuring out the 3D shape of the human body from ordinary scenes is an important part of how we see and understand the world around us. Being able to accurately estimate 3D human poses is crucial for advancing technologies like artificial intelligence-generated content (AIGC) and human-robot interaction, as it allows these systems to better understand and interact with people's movements and actions in real-world environments.
However, the datasets currently available for training and testing 3D human pose estimation models are limited. They are often collected in single laboratory settings using specialized motion capture equipment and unchanging backgrounds. This lack of diversity in the training data is slowing down progress on this vital capability.
To address this, the researchers created a new, large-scale dataset called FreeMan that captures human poses in a much wider range of real-world conditions. FreeMan includes over 11 million frames of video from 8,000 sequences, filmed by synchronized smartphones in 40 different scenarios with varying lighting. This diversity in the data is intended to help 3D human pose estimation models become more robust and effective in natural, complex environments.
Technical Explanation
The paper presents FreeMan, a large-scale, multi-view dataset collected in diverse real-world conditions to facilitate the development of 3D human pose estimation models. The dataset was captured by synchronizing 8 smartphone cameras across 40 subjects performing various actions in 10 different scenarios with varying lighting.
FreeMan comprises 11 million frames from 8,000 video sequences, providing a rich and varied set of data for training and evaluating 3D human pose estimation algorithms. The researchers established a semi-automated pipeline to efficiently annotate the data and ensure precise 3D pose labels, reducing the workload of manual checking.
The paper provides comprehensive evaluation baselines for a range of tasks, highlighting the significant challenges posed by the FreeMan dataset compared to existing indoor/outdoor human sensing datasets. The results demonstrate that FreeMan offers a robust representation that can transfer well to real and complex scenes, advancing the field of 3D human pose estimation.
Critical Analysis
The FreeMan dataset addresses an important limitation in the current landscape of 3D human pose estimation datasets, which have traditionally been collected in constrained laboratory settings. By capturing data in diverse real-world scenarios, the researchers have created a more realistic and challenging benchmark to drive progress in this crucial field.
However, the paper does not provide much detail on the specific challenges encountered during the data collection process or the limitations of the current version of the dataset. For example, it would be helpful to understand how the researchers handled occlusions, varying camera perspectives, and other complexities inherent to unconstrained real-world environments.
Additionally, the paper could have delved deeper into the implications and potential applications of robust 3D human pose estimation beyond the examples provided, such as its impact on fields like healthcare, sports analysis, or autonomous systems. Exploring these avenues could help readers better appreciate the broader significance of the research.
Overall, the FreeMan dataset represents an important step forward in advancing 3D human pose estimation, and the researchers' efforts to create a more realistic and representative benchmark are commendable. As the field continues to evolve, further refinements and expansions of the dataset may yield even more valuable insights.
Conclusion
The research paper presents FreeMan, a large-scale, multi-view dataset that aims to address the limitations of current 3D human pose estimation datasets by capturing diverse, real-world scenarios. By providing a more realistic and challenging benchmark, the FreeMan dataset has the potential to drive significant progress in this crucial field, with far-reaching implications for technologies like AIGC and human-robot interaction.
The dataset's comprehensive evaluation baselines and robust representation transferability demonstrate its value as a tool for advancing the state of the art in 3D human pose estimation. While the paper could have delved deeper into certain aspects, the researchers' work represents an important contribution to the field, paving the way for more effective and deployable 3D human sensing capabilities in complex, natural environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
FreeZe: Training-free zero-shot 6D pose estimation with geometric and vision foundation models
Andrea Caraffa, Davide Boscaini, Amir Hamza, Fabio Poiesi
0
0
Estimating the 6D pose of objects unseen during training is highly desirable yet challenging. Zero-shot object 6D pose estimation methods address this challenge by leveraging additional task-specific supervision provided by large-scale, photo-realistic synthetic datasets. However, their performance heavily depends on the quality and diversity of rendered data and they require extensive training. In this work, we show how to tackle the same task but without training on specific data. We propose FreeZe, a novel solution that harnesses the capabilities of pre-trained geometric and vision foundation models. FreeZe leverages 3D geometric descriptors learned from unrelated 3D point clouds and 2D visual features learned from web-scale 2D images to generate discriminative 3D point-level descriptors. We then estimate the 6D pose of unseen objects by 3D registration based on RANSAC. We also introduce a novel algorithm to solve ambiguous cases due to geometrically symmetric objects that is based on visual features. We comprehensively evaluate FreeZe across the seven core datasets of the BOP Benchmark, which include over a hundred 3D objects and 20,000 images captured in various scenarios. FreeZe consistently outperforms all state-of-the-art approaches, including competitors extensively trained on synthetic 6D pose estimation data. Code will be publicly available at https://andreacaraffa.github.io/freeze.
4/4/2024
🏷️
3D Human Pose Perception from Egocentric Stereo Videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, Christian Theobalt
0
0
While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
5/16/2024
📊
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
0
0
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
4/10/2024
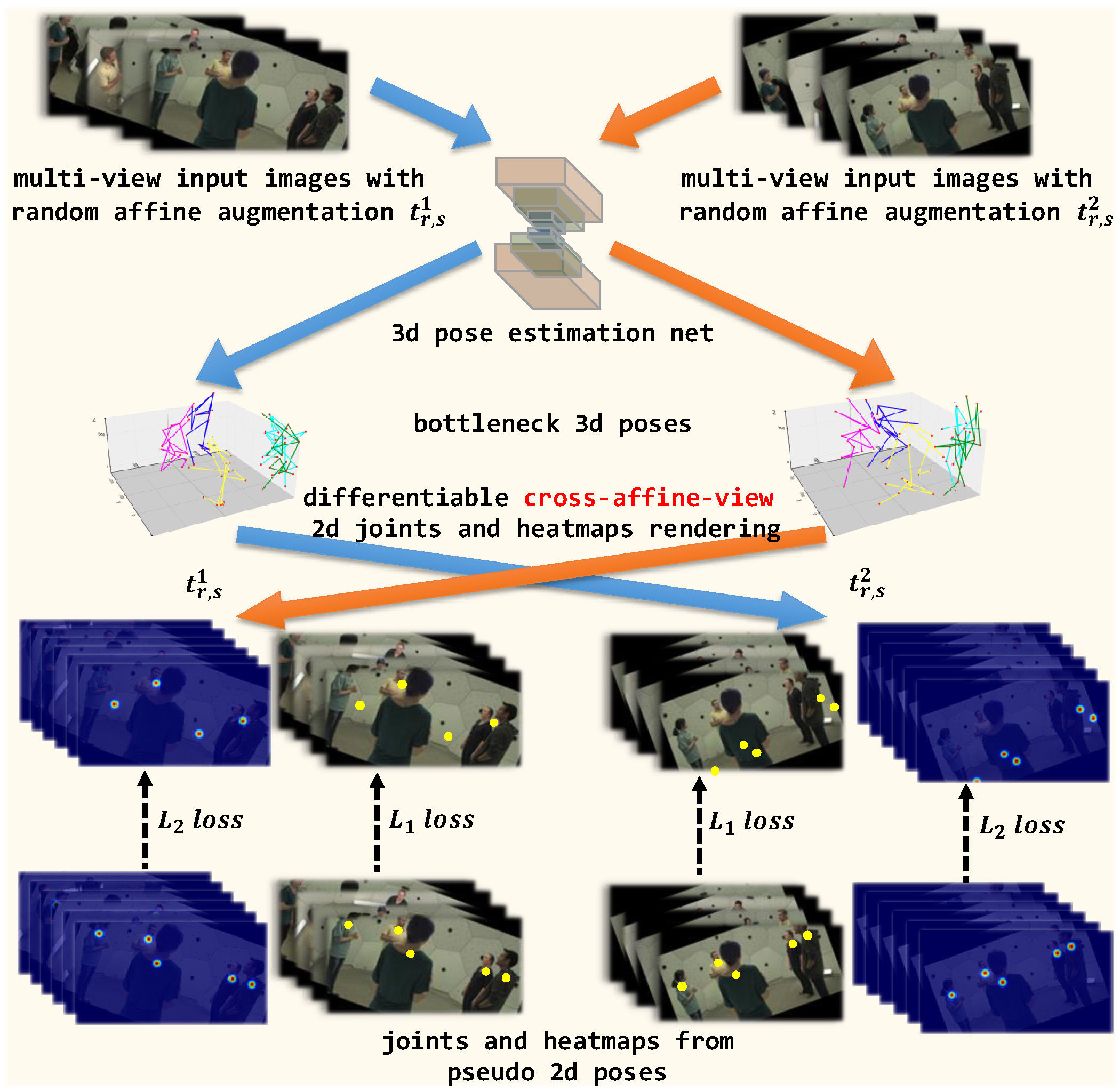
SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
Vinkle Srivastav, Keqi Chen, Nicolas Padoy
0
0
We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code: https://github.com/CAMMA-public/SelfPose3D. Video demo: https://youtu.be/GAqhmUIr2E8.
6/11/2024