FreeZe: Training-free zero-shot 6D pose estimation with geometric and vision foundation models
2312.00947
0
0
👀
Abstract
Estimating the 6D pose of objects unseen during training is highly desirable yet challenging. Zero-shot object 6D pose estimation methods address this challenge by leveraging additional task-specific supervision provided by large-scale, photo-realistic synthetic datasets. However, their performance heavily depends on the quality and diversity of rendered data and they require extensive training. In this work, we show how to tackle the same task but without training on specific data. We propose FreeZe, a novel solution that harnesses the capabilities of pre-trained geometric and vision foundation models. FreeZe leverages 3D geometric descriptors learned from unrelated 3D point clouds and 2D visual features learned from web-scale 2D images to generate discriminative 3D point-level descriptors. We then estimate the 6D pose of unseen objects by 3D registration based on RANSAC. We also introduce a novel algorithm to solve ambiguous cases due to geometrically symmetric objects that is based on visual features. We comprehensively evaluate FreeZe across the seven core datasets of the BOP Benchmark, which include over a hundred 3D objects and 20,000 images captured in various scenarios. FreeZe consistently outperforms all state-of-the-art approaches, including competitors extensively trained on synthetic 6D pose estimation data. Code will be publicly available at https://andreacaraffa.github.io/freeze.
Create account to get full access
Overview
- The paper presents a new approach for 6D object pose estimation that leverages zero-shot learning techniques.
- 6D pose estimation is the task of determining an object's position and orientation in 3D space.
- Zero-shot learning enables the recognition of new objects without requiring training data for those objects.
- The proposed method combines 6D pose estimation with zero-shot learning to handle novel objects not seen during training.
Plain English Explanation
The researchers have developed a new way to estimate the 6D pose (position and orientation) of objects in 3D space. Traditionally, object pose estimation systems require extensive training data for every object they need to recognize. This can be a major limitation, as it's often impractical to obtain training data for every possible object.
The key innovation in this paper is the integration of zero-shot learning techniques. Zero-shot learning allows the system to recognize and estimate the pose of objects it has never seen before, without requiring any training data for those specific objects. Instead, the system learns a general understanding of 3D object shapes and poses, which it can then apply to novel objects.
This is analogous to how humans can often recognize and interact with new objects, even if we've never encountered them before. We use our general knowledge about the physical world to reason about the properties and behaviors of unfamiliar things.
By combining 6D pose estimation with zero-shot learning, the researchers have created a more flexible and adaptable system that can handle a much broader range of objects than traditional approaches. This could have valuable applications in areas like robotics, augmented reality, and scene understanding, where the ability to work with novel objects is critical.
Technical Explanation
The paper proposes a novel architecture for 6D object pose estimation that incorporates zero-shot learning. The key components are:
-
Pose Embedding Network: This neural network learns a latent representation of object poses, capturing the 3D geometry and orientation information. The pose embedding is learned in an unsupervised manner, without requiring any ground-truth pose labels.
-
Zero-shot Pose Estimation: Given an input image of an object, the system uses the learned pose embedding to estimate the 6D pose, even if the object is novel and has not been seen during training. This is achieved by matching the input object's features to the pose embedding space.
-
Pose Refinement: The initial pose estimate is further refined using an iterative optimization process, which aligns the 3D object model with the observed image features.
The researchers evaluate their approach on standard 6D pose estimation benchmarks, demonstrating state-of-the-art performance on both seen and unseen objects. This highlights the effectiveness of combining 6D pose estimation with zero-shot learning techniques.
Critical Analysis
The paper presents a compelling solution to the challenge of 6D pose estimation for novel objects. By leveraging zero-shot learning, the approach can handle a much broader range of objects than traditional methods, which is a significant advantage.
However, the paper does not extensively discuss the limitations or potential drawbacks of the proposed system. For example, the performance on extremely novel or unfamiliar objects is not explored, and the robustness to occlusion or cluttered scenes could be further investigated.
Additionally, the paper focuses on the technical implementation and evaluation, but does not delve into the potential societal implications or ethical considerations of such a system. As 6D pose estimation finds applications in areas like robotics and augmented reality, it will be important to consider how these technologies can be developed and deployed responsibly.
Conclusion
This paper presents an innovative approach that combines 6D object pose estimation with zero-shot learning techniques. By enabling the recognition and pose estimation of novel objects, the proposed system represents an important advancement in the field of 3D computer vision.
The ability to handle a broader range of objects without requiring extensive training data has the potential to unlock new applications in robotics, augmented reality, and scene understanding. As the research in this area continues to progress, it will be crucial to also consider the societal implications and ensure these technologies are developed and used ethically.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Open-Pose 3D Zero-Shot Learning: Benchmark and Challenges
Weiguang Zhao, Guanyu Yang, Rui Zhang, Chenru Jiang, Chaolong Yang, Yuyao Yan, Amir Hussain, Kaizhu Huang
0
0
With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, methods transferring language or language-image pre-training models like Contrastive Language-Image Pre-training (CLIP) to 3D vision have made significant progress in the 3D zero-shot classification task. These methods primarily focus on 3D object classification with an aligned pose; such a setting is, however, rather restrictive, which overlooks the recognition of 3D objects with open poses typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more realistic and challenging scenario named open-pose 3D zero-shot classification, focusing on the recognition of 3D objects regardless of their orientation. First, we revisit the current research on 3D zero-shot classification, and propose two benchmark datasets specifically designed for the open-pose setting. We empirically validate many of the most popular methods in the proposed open-pose benchmark. Our investigations reveal that most current 3D zero-shot classification models suffer from poor performance, indicating a substantial exploration room towards the new direction. Furthermore, we study a concise pipeline with an iterative angle refinement mechanism that automatically optimizes one ideal angle to classify these open-pose 3D objects. In particular, to make validation more compelling and not just limited to existing CLIP-based methods, we also pioneer the exploration of knowledge transfer based on Diffusion models. While the proposed solutions can serve as a new benchmark for open-pose 3D zero-shot classification, we discuss the complexities and challenges of this scenario that remain for further research development. The code is available publicly at https://github.com/weiguangzhao/Diff-OP3D.
4/17/2024
👀
FreeMan: Towards Benchmarking 3D Human Pose Estimation under Real-World Conditions
Jiong Wang, Fengyu Yang, Wenbo Gou, Bingliang Li, Danqi Yan, Ailing Zeng, Yijun Gao, Junle Wang, Yanqing Jing, Ruimao Zhang
0
0
Estimating the 3D structure of the human body from natural scenes is a fundamental aspect of visual perception. 3D human pose estimation is a vital step in advancing fields like AIGC and human-robot interaction, serving as a crucial technique for understanding and interacting with human actions in real-world settings. However, the current datasets, often collected under single laboratory conditions using complex motion capture equipment and unvarying backgrounds, are insufficient. The absence of datasets on variable conditions is stalling the progress of this crucial task. To facilitate the development of 3D pose estimation, we present FreeMan, the first large-scale, multi-view dataset collected under the real-world conditions. FreeMan was captured by synchronizing 8 smartphones across diverse scenarios. It comprises 11M frames from 8000 sequences, viewed from different perspectives. These sequences cover 40 subjects across 10 different scenarios, each with varying lighting conditions. We have also established an semi-automated pipeline containing error detection to reduce the workload of manual check and ensure precise annotation. We provide comprehensive evaluation baselines for a range of tasks, underlining the significant challenges posed by FreeMan. Further evaluations of standard indoor/outdoor human sensing datasets reveal that FreeMan offers robust representation transferability in real and complex scenes. Code and data are available at https://wangjiongw.github.io/freeman.
4/4/2024
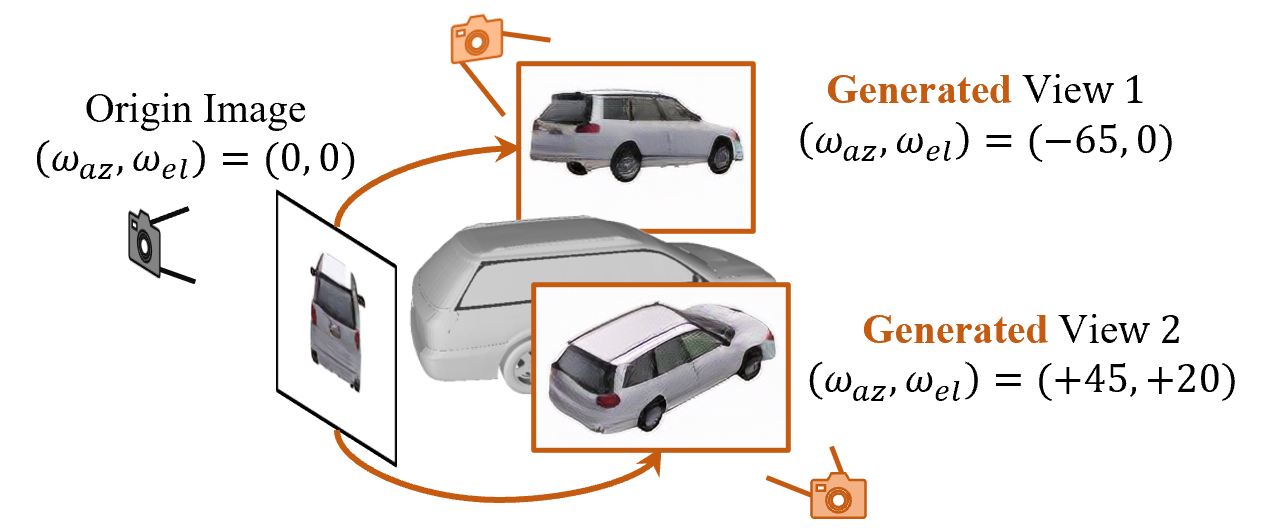
Learning a Category-level Object Pose Estimator without Pose Annotations
Fengrui Tian, Yaoyao Liu, Adam Kortylewski, Yueqi Duan, Shaoyi Du, Alan Yuille, Angtian Wang
0
0
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
4/9/2024
🎯
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
Haixin Shi, Yinlin Hu, Daniel Koguciuk, Juan-Ting Lin, Mathieu Salzmann, David Ferstl
0
0
We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
5/13/2024