Evaluating Large Language Models with Human Feedback: Establishing a Swedish Benchmark
2405.14006
0
0
💬
Abstract
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have demonstrated significant capabilities across numerous applications. However, the performance of these models in languages with fewer resources, such as Swedish, remains under-explored. This study introduces a comprehensive human benchmark to assess the efficacy of prominent LLMs in understanding and generating Swedish language texts using forced choice ranking. We employ a modified version of the ChatbotArena benchmark, incorporating human feedback to evaluate eleven different models, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin. These models were chosen based on their performance on LMSYS chatbot arena and the Scandeval benchmarks. We release the chatbotarena.se benchmark as a tool to improve our understanding of language model performance in Swedish with the hopes that it will be widely used. We aim to create a leaderboard once sufficient data has been collected and analysed.
Create account to get full access
Overview
- This study explores the performance of large language models (LLMs) in understanding and generating Swedish language texts.
- The researchers developed a comprehensive human benchmark called ChatbotArena to assess the efficacy of 11 different LLMs, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models.
- The benchmark was based on a modified version of the ChatbotArena benchmark, incorporating human feedback to evaluate the models' performance.
- The study aims to create a leaderboard for LLM performance in Swedish once sufficient data has been collected and analyzed.
Plain English Explanation
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have demonstrated impressive capabilities across many applications. However, their performance in languages with fewer resources, like Swedish, has not been extensively studied. This research introduces a comprehensive human benchmark to evaluate how well prominent LLMs can understand and generate Swedish language texts.
The researchers used a modified version of the ChatbotArena benchmark, which incorporates human feedback, to assess the performance of 11 different LLMs. These models include well-known ones like GPT-4 and GPT-3.5, as well as various Claude and Llama models, and some specialized models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin.
The goal of this study is to create a reliable way to measure how well LLMs can understand and generate Swedish text, which could help improve these models' performance in languages with fewer resources. The researchers hope that the ChatbotArena.se benchmark will be widely used to build a leaderboard for LLM performance in Swedish.
Technical Explanation
The researchers developed a modified version of the ChatbotArena benchmark to assess the performance of 11 different LLMs in understanding and generating Swedish language texts. The models were chosen based on their performance on the LMSYS chatbot arena and Scandeval benchmarks.
The ChatbotArena.se benchmark used a forced choice ranking approach, where human participants were asked to evaluate the models' responses to various prompts. This approach allowed for a comprehensive assessment of the models' abilities in areas like natural language understanding, dialogue generation, and task-completion.
The researchers chose a diverse set of 11 LLMs, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin. This selection allowed for a comprehensive evaluation of the models' performance in the Swedish language domain.
Critical Analysis
The study provides a valuable contribution to the field by exploring the performance of LLMs in a language with fewer resources, such as Swedish. However, the researchers acknowledge that the performance of these models may be limited by the availability of Swedish language data used in their training.
Additionally, the modified ChatbotArena benchmark, while comprehensive, may not capture all aspects of language understanding and generation. There is a need for further research to develop more robust and diverse benchmarks that can better assess the capabilities of LLMs in low-resource languages.
The researchers also note that their study focused on a limited set of LLMs, and there may be other models or approaches that could perform better in the Swedish language domain. Expanding the scope of models evaluated and exploring different benchmark designs could lead to a more nuanced understanding of LLM performance in Swedish.
Conclusion
This study introduces a comprehensive human benchmark to assess the performance of prominent LLMs in understanding and generating Swedish language texts. The researchers employed a modified version of the ChatbotArena benchmark, which incorporates human feedback, to evaluate 11 different models.
The development of the ChatbotArena.se benchmark is a valuable contribution to the field, as it provides a tool to improve our understanding of LLM performance in Swedish. The researchers aim to create a leaderboard for LLM performance in Swedish, which could help drive further advancements in language technology for low-resource languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
0
0
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
6/18/2024
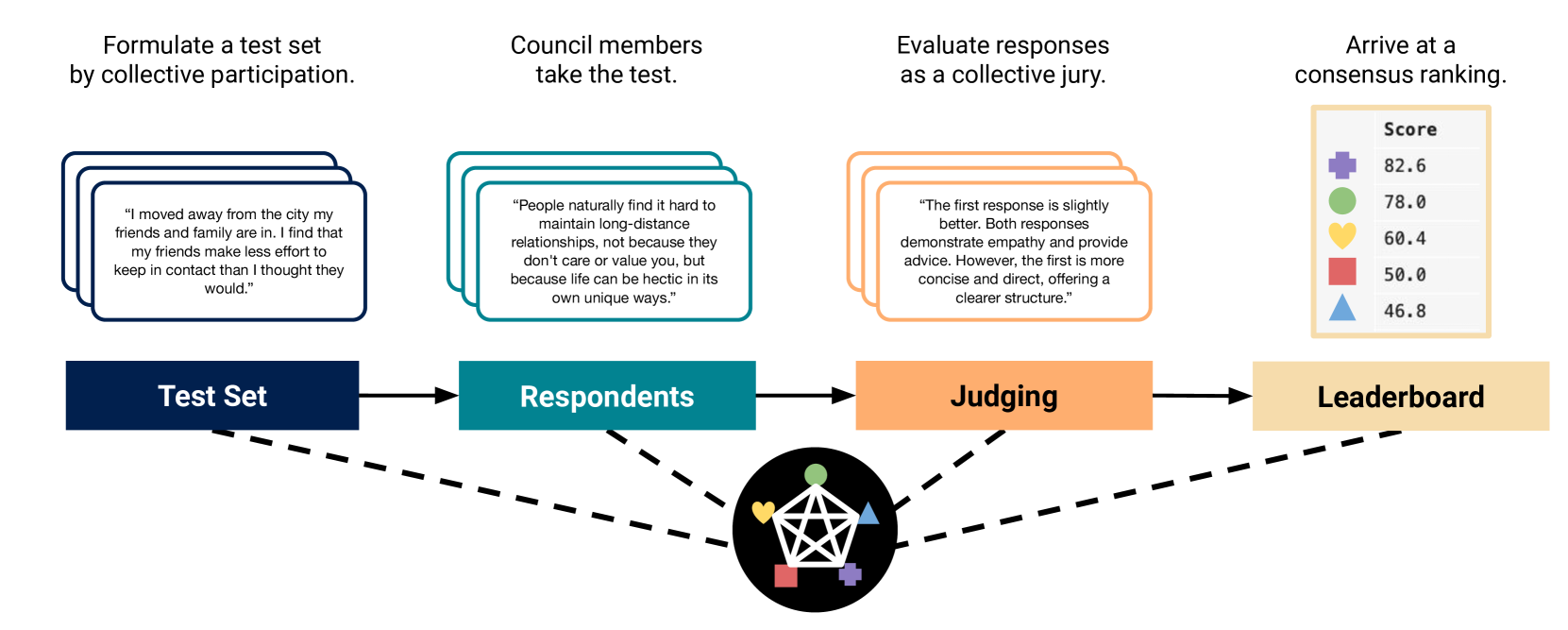
Language Model Council: Benchmarking Foundation Models on Highly Subjective Tasks by Consensus
Justin Zhao, Flor Miriam Plaza-del-Arco, Amanda Cercas Curry
0
0
The rapid advancement of Large Language Models (LLMs) necessitates robust and challenging benchmarks. Leaderboards like Chatbot Arena rank LLMs based on how well their responses align with human preferences. However, many tasks such as those related to emotional intelligence, creative writing, or persuasiveness, are highly subjective and often lack majoritarian human agreement. Judges may have irreconcilable disagreements about what constitutes a better response. To address the challenge of ranking LLMs on highly subjective tasks, we propose a novel benchmarking framework, the Language Model Council (LMC). The LMC operates through a democratic process to: 1) formulate a test set through equal participation, 2) administer the test among council members, and 3) evaluate responses as a collective jury. We deploy a council of 20 newest LLMs on an open-ended emotional intelligence task: responding to interpersonal dilemmas. Our results show that the LMC produces rankings that are more separable, robust, and less biased than those from any individual LLM judge, and is more consistent with a human-established leaderboard compared to other benchmarks.
6/14/2024
📉
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, Kun Gai
0
0
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
4/1/2024
Spanish and LLM Benchmarks: is MMLU Lost in Translation?
Irene Plaza, Nina Melero, Cristina del Pozo, Javier Conde, Pedro Reviriego, Marina Mayor-Rocher, Mar'ia Grandury
0
0
The evaluation of Large Language Models (LLMs) is a key element in their continuous improvement process and many benchmarks have been developed to assess the performance of LLMs in different tasks and topics. As LLMs become adopted worldwide, evaluating them in languages other than English is increasingly important. However, most LLM benchmarks are simply translated using an automated tool and then run in the target language. This means that the results depend not only on the LLM performance in that language but also on the quality of the translation. In this paper, we consider the case of the well-known Massive Multitask Language Understanding (MMLU) benchmark. Selected categories of the benchmark are translated into Spanish using Azure Translator and ChatGPT4 and run on ChatGPT4. Next, the results are processed to identify the test items that produce different answers in Spanish and English. Those are then analyzed manually to understand if the automatic translation caused the change. The results show that a significant fraction of the failing items can be attributed to mistakes in the translation of the benchmark. These results make a strong case for improving benchmarks in languages other than English by at least revising the translations of the items and preferably by adapting the tests to the target language by experts.
6/27/2024