WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
2406.04770
0
0

Abstract
We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs. For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo. WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments. WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation. Additionally, we propose a simple method to mitigate length bias, by converting outcomes of slightly better/worse'' to tie'' if the winner response exceeds the loser one by more than $K$ characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric. WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard's 0.91 and AlpacaEval2.0's 0.89 for length-controlled win rates, as well as the 0.87 for regular win rates.
Create account to get full access
Overview
• This paper introduces a new benchmark called WildBench for evaluating large language models (LLMs) on challenging real-world tasks submitted by actual users.
• The researchers curated a diverse dataset of tasks that go beyond standard benchmarks and test LLMs' abilities to handle open-ended, context-rich prompts from diverse users.
• The paper presents the methodology for constructing the WildBench dataset, analysis of model performance, and implications for improving LLM development and evaluation.
Plain English Explanation
The researchers behind this paper have created a new way to test the capabilities of large language models (LLMs) - advanced AI systems that can understand and generate human-like text. Rather than using standard benchmark tasks, they've gathered a diverse set of real-world challenges submitted by actual users.
These tasks are more open-ended and context-rich than what you'd typically find in a benchmark. They're designed to push LLMs beyond their comfort zone and see how well they can handle the kind of messy, ambiguous prompts that real people might give them.
By evaluating LLMs on this "WildBench" dataset, the researchers hope to get a better sense of the models' true abilities and limitations. The goal is to identify areas where LLMs excel or struggle, which can then inform efforts to improve them and make them more reliable and capable at handling the complexities of the real world.
Technical Explanation
The paper introduces the WildBench benchmark, which aims to evaluate large language models (LLMs) on a diverse set of challenging tasks sourced from real users in the "wild" rather than standard benchmark datasets.
The researchers curated the WildBench dataset by crowdsourcing task prompts from a wide range of users, covering topics like [link to NaturalCodeBench paper], [link to EvaluatingLLMsHumanFeedback paper], [link to CleMBench paper], [link to OlympiadBench paper], and [link to DialogBench paper]. These prompts are designed to be more open-ended, context-rich, and representative of real-world user needs compared to typical benchmark tasks.
The paper analyzes the performance of several prominent LLMs on the WildBench dataset, revealing strengths and weaknesses across different task types. The results suggest that while LLMs excel at certain tasks, they can struggle with the complexities and ambiguities present in many real-world user prompts.
Critical Analysis
The WildBench benchmark represents an important step forward in LLM evaluation, moving beyond standard benchmarks to more realistically assess model capabilities in the face of diverse, challenging user requests.
However, the paper acknowledges some potential limitations. The crowdsourced task prompts may still not fully capture the breadth and nuance of real-world user needs, and the evaluation methodology could be further refined. There are also open questions around how to best interpret and act on the performance insights from WildBench.
Additionally, while the paper focuses on evaluating current LLM capabilities, it does not delve deeply into the potential societal implications or ethical considerations of deploying these models at scale. Future research should explore these crucial aspects as well.
Conclusion
The WildBench benchmark represents an important advance in evaluating the capabilities of large language models. By assessing LLMs on a diverse set of challenging, real-world tasks, the researchers have uncovered valuable insights into the models' strengths and limitations.
These findings can help drive efforts to improve LLM robustness and reliability, ensuring they can better handle the complexities of the real world and meet the needs of diverse users. As LLMs become more prevalent, benchmarks like WildBench will be crucial for responsible development and deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica
0
0
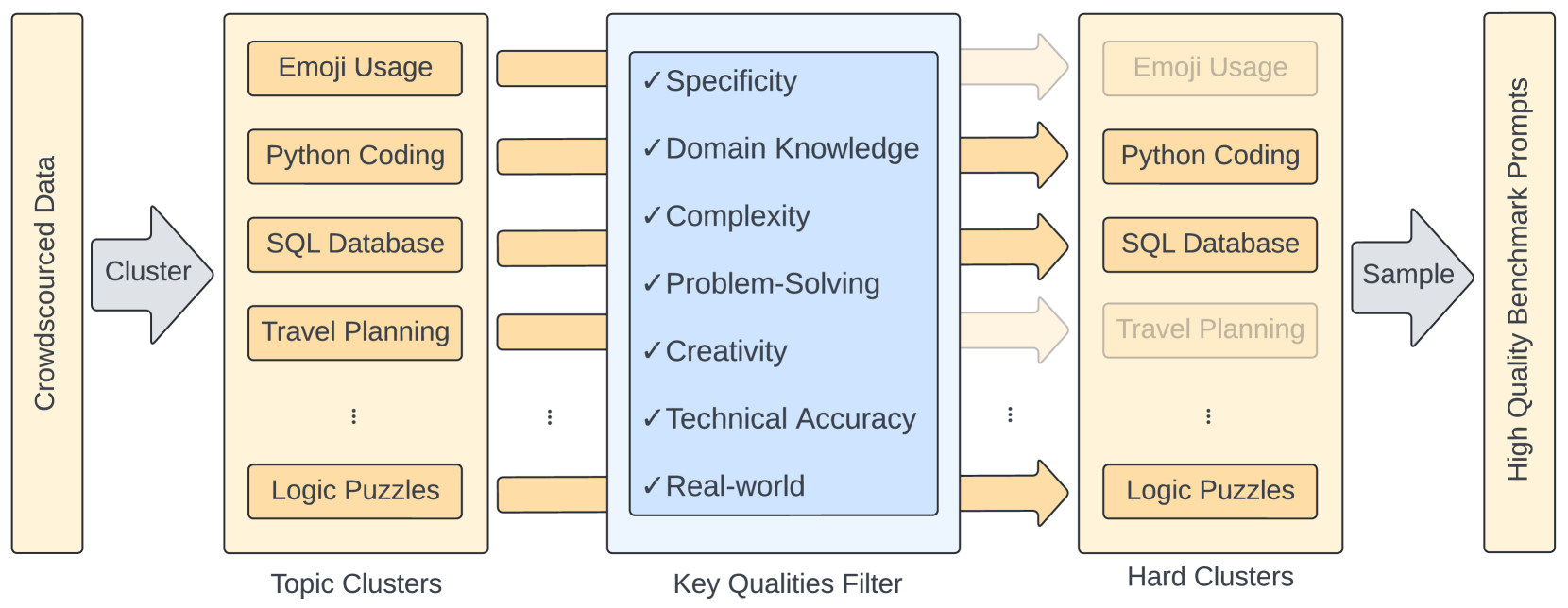
The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
6/19/2024
WildVision: Evaluating Vision-Language Models in the Wild with Human Preferences
Yujie Lu, Dongfu Jiang, Wenhu Chen, William Yang Wang, Yejin Choi, Bill Yuchen Lin
0
0
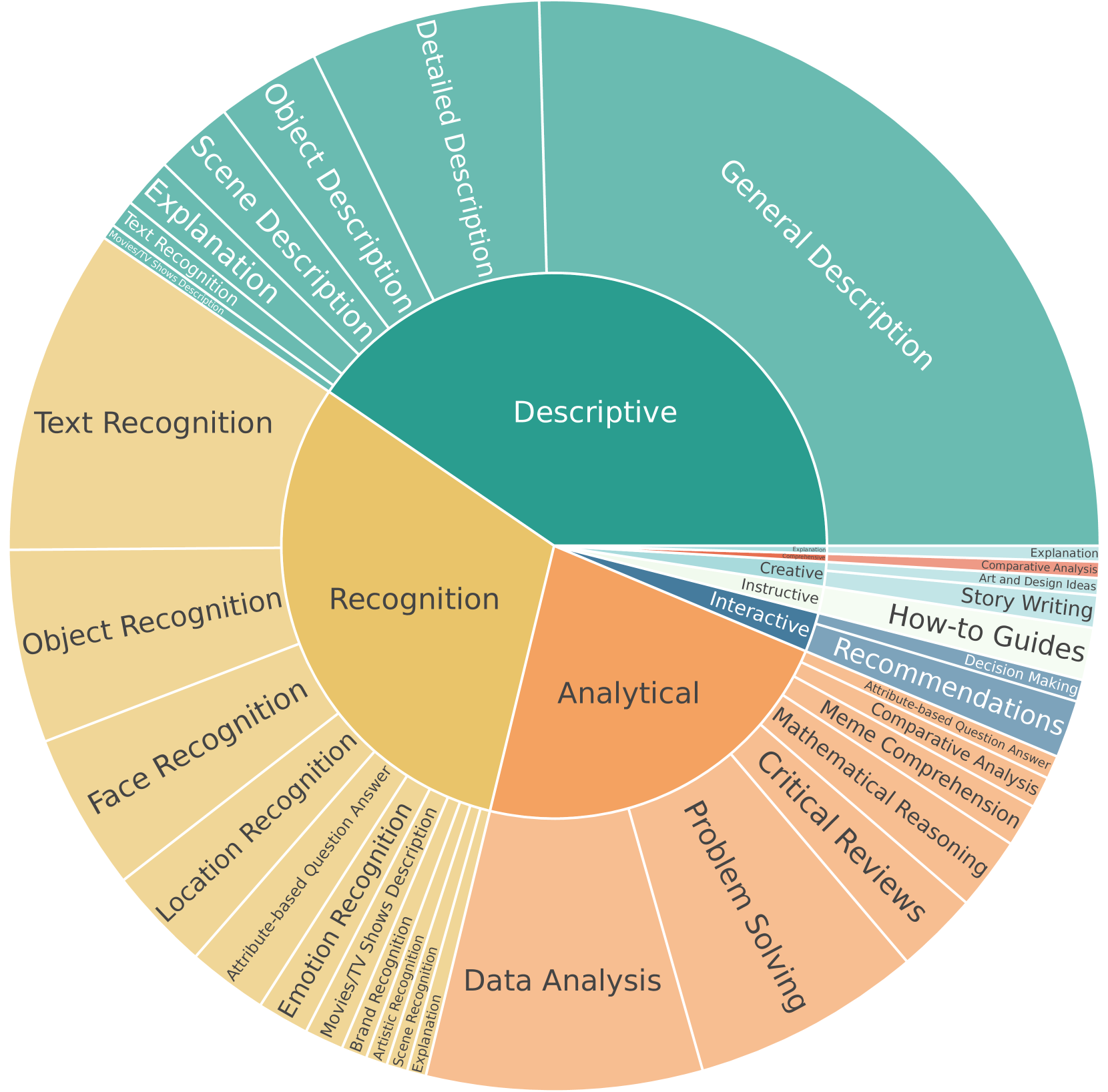
Recent breakthroughs in vision-language models (VLMs) emphasize the necessity of benchmarking human preferences in real-world multimodal interactions. To address this gap, we launched WildVision-Arena (WV-Arena), an online platform that collects human preferences to evaluate VLMs. We curated WV-Bench by selecting 500 high-quality samples from 8,000 user submissions in WV-Arena. WV-Bench uses GPT-4 as the judge to compare each VLM with Claude-3-Sonnet, achieving a Spearman correlation of 0.94 with the WV-Arena Elo. This significantly outperforms other benchmarks like MMVet, MMMU, and MMStar. Our comprehensive analysis of 20K real-world interactions reveals important insights into the failure cases of top-performing VLMs. For example, we find that although GPT-4V surpasses many other models like Reka-Flash, Opus, and Yi-VL-Plus in simple visual recognition and reasoning tasks, it still faces challenges with subtle contextual cues, spatial reasoning, visual imagination, and expert domain knowledge. Additionally, current VLMs exhibit issues with hallucinations and safety when intentionally provoked. We are releasing our chat and feedback data to further advance research in the field of VLMs.
6/18/2024
🌐
LiveBench: A Challenging, Contamination-Free LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, Micah Goldblum
0
0
Test set contamination, wherein test data from a benchmark ends up in a newer model's training set, is a well-documented obstacle for fair LLM evaluation and can quickly render benchmarks obsolete. To mitigate this, many recent benchmarks crowdsource new prompts and evaluations from human or LLM judges; however, these can introduce significant biases, and break down when scoring hard questions. In this work, we introduce a new benchmark for LLMs designed to be immune to both test set contamination and the pitfalls of LLM judging and human crowdsourcing. We release LiveBench, the first benchmark that (1) contains frequently-updated questions from recent information sources, (2) scores answers automatically according to objective ground-truth values, and (3) contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis. To achieve this, LiveBench contains questions that are based on recently-released math competitions, arXiv papers, news articles, and datasets, and it contains harder, contamination-free versions of tasks from previous benchmarks such as Big-Bench Hard, AMPS, and IFEval. We evaluate many prominent closed-source models, as well as dozens of open-source models ranging from 0.5B to 110B in size. LiveBench is difficult, with top models achieving below 65% accuracy. We release all questions, code, and model answers. Questions will be added and updated on a monthly basis, and we will release new tasks and harder versions of tasks over time so that LiveBench can distinguish between the capabilities of LLMs as they improve in the future. We welcome community engagement and collaboration for expanding the benchmark tasks and models.
6/28/2024
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
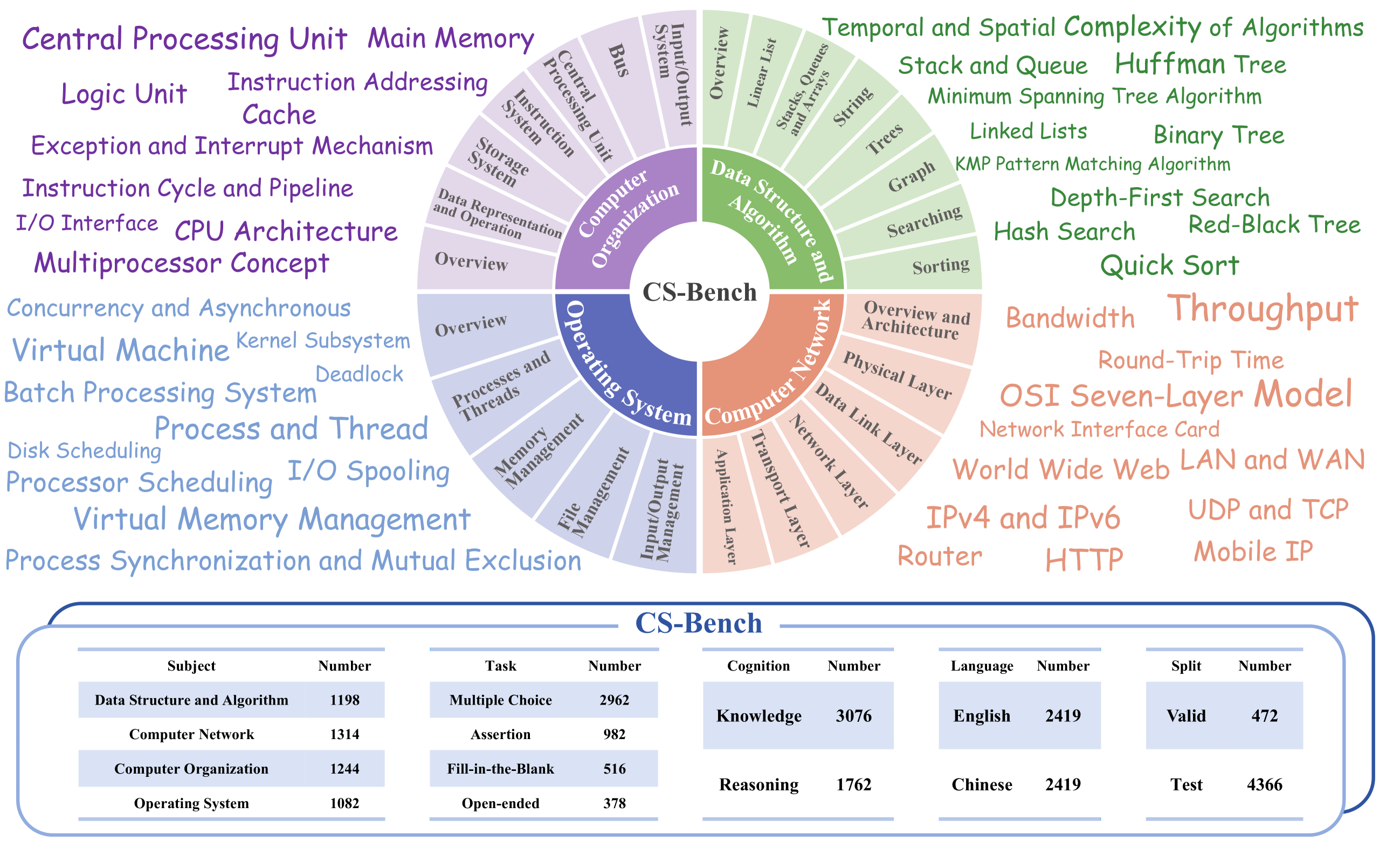
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024