LiveBench: A Challenging, Contamination-Free LLM Benchmark
2406.19314
0
0
🌐
Abstract
Test set contamination, wherein test data from a benchmark ends up in a newer model's training set, is a well-documented obstacle for fair LLM evaluation and can quickly render benchmarks obsolete. To mitigate this, many recent benchmarks crowdsource new prompts and evaluations from human or LLM judges; however, these can introduce significant biases, and break down when scoring hard questions. In this work, we introduce a new benchmark for LLMs designed to be immune to both test set contamination and the pitfalls of LLM judging and human crowdsourcing. We release LiveBench, the first benchmark that (1) contains frequently-updated questions from recent information sources, (2) scores answers automatically according to objective ground-truth values, and (3) contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis. To achieve this, LiveBench contains questions that are based on recently-released math competitions, arXiv papers, news articles, and datasets, and it contains harder, contamination-free versions of tasks from previous benchmarks such as Big-Bench Hard, AMPS, and IFEval. We evaluate many prominent closed-source models, as well as dozens of open-source models ranging from 0.5B to 110B in size. LiveBench is difficult, with top models achieving below 65% accuracy. We release all questions, code, and model answers. Questions will be added and updated on a monthly basis, and we will release new tasks and harder versions of tasks over time so that LiveBench can distinguish between the capabilities of LLMs as they improve in the future. We welcome community engagement and collaboration for expanding the benchmark tasks and models.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
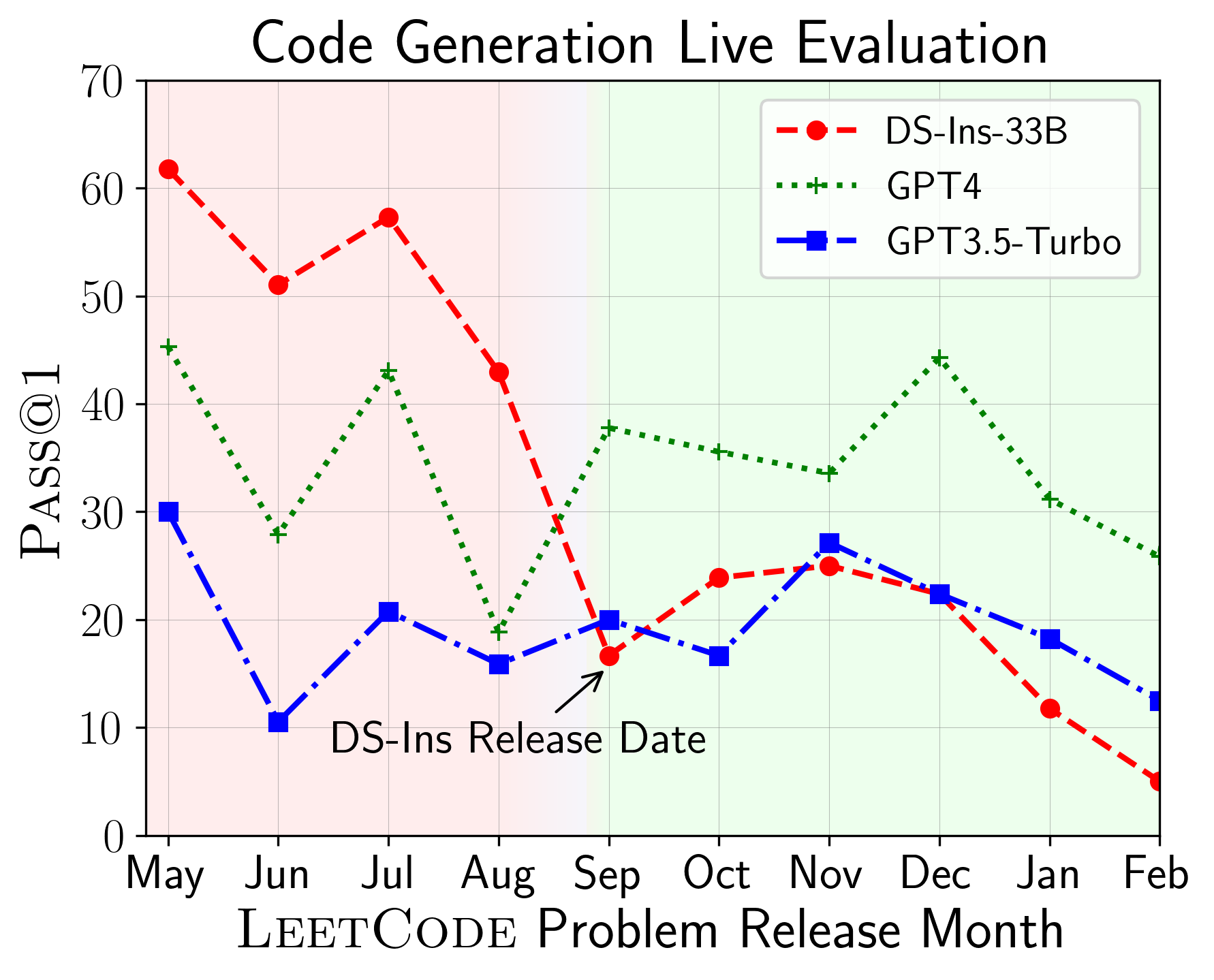
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica
0
0
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and May 2024. We have evaluated 18 base LLMs and 34 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
6/7/2024

WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, Yejin Choi
0
0
We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs. For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo. WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments. WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation. Additionally, we propose a simple method to mitigate length bias, by converting outcomes of ``slightly better/worse'' to ``tie'' if the winner response exceeds the loser one by more than $K$ characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric. WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard's 0.91 and AlpacaEval2.0's 0.89 for length-controlled win rates, as well as the 0.87 for regular win rates.
6/10/2024
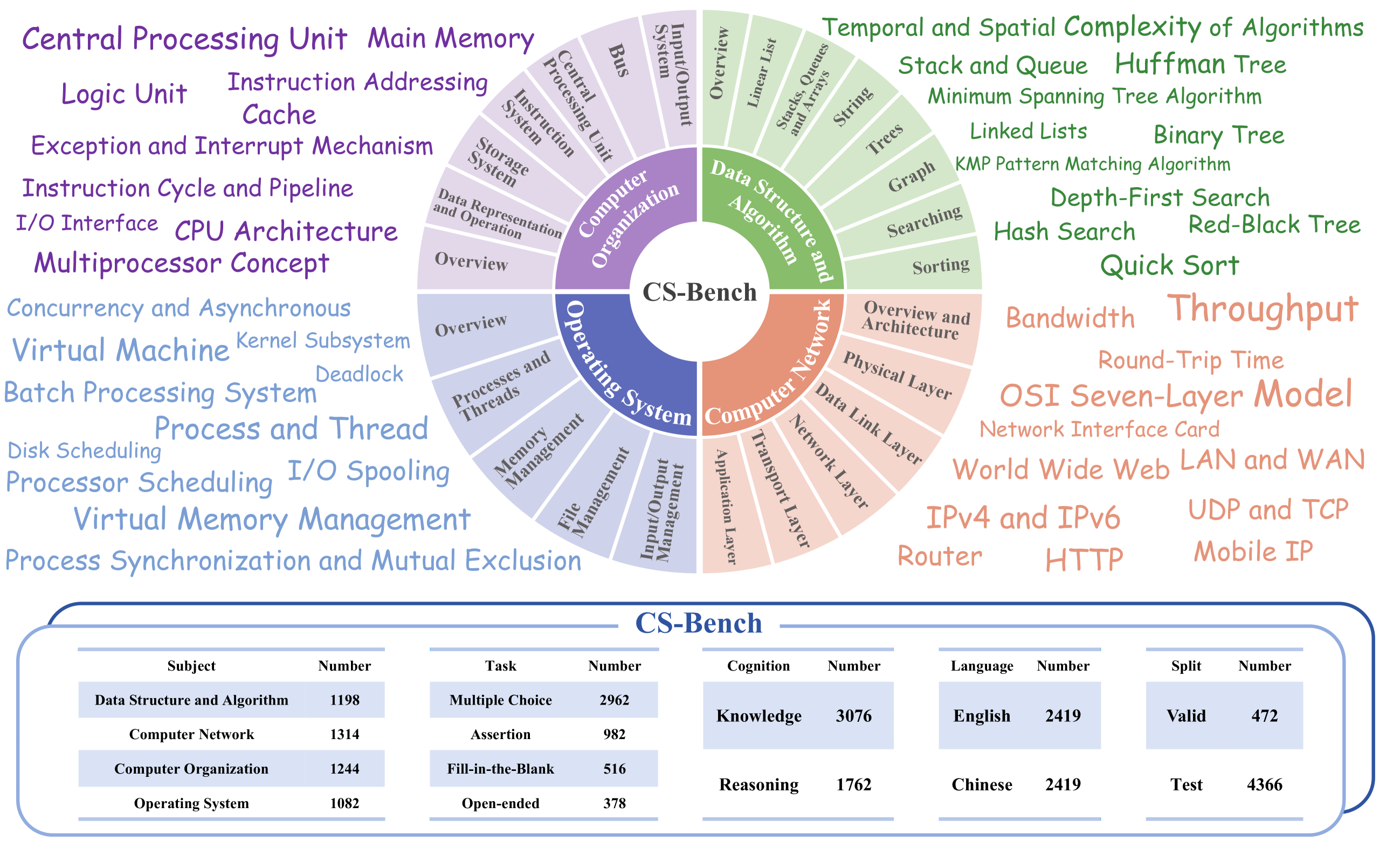
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
0
0
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
6/14/2024
📊
Investigating Data Contamination in Modern Benchmarks for Large Language Models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, Arman Cohan
0
0
Recent observations have underscored a disparity between the inflated benchmark scores and the actual performance of LLMs, raising concerns about potential contamination of evaluation benchmarks. This issue is especially critical for closed-source models and certain open-source models where training data transparency is lacking. In this paper we study data contamination by proposing two methods tailored for both open-source and proprietary LLMs. We first introduce a retrieval-based system to explore potential overlaps between evaluation benchmarks and pretraining corpora. We further present a novel investigation protocol named textbf{T}estset textbf{S}lot Guessing (textit{TS-Guessing}), applicable to both open and proprietary models. This approach entails masking a wrong answer in a multiple-choice question and prompting the model to fill in the gap. Additionally, it involves obscuring an unlikely word in an evaluation example and asking the model to produce it. We find that certain commercial LLMs could surprisingly guess the missing option in various test sets. Specifically, in the TruthfulQA benchmark, we find that LLMs exhibit notable performance improvement when provided with additional metadata in the benchmark. Further, in the MMLU benchmark, ChatGPT and GPT-4 demonstrated an exact match rate of 52% and 57%, respectively, in guessing the missing options in benchmark test data. We hope these results underscore the need for more robust evaluation methodologies and benchmarks in the field.
4/5/2024