From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models
2406.16838
2
0
💬
Abstract
One of the most striking findings in modern research on large language models (LLMs) is that scaling up compute during training leads to better results. However, less attention has been given to the benefits of scaling compute during inference. This survey focuses on these inference-time approaches. We explore three areas under a unified mathematical formalism: token-level generation algorithms, meta-generation algorithms, and efficient generation. Token-level generation algorithms, often called decoding algorithms, operate by sampling a single token at a time or constructing a token-level search space and then selecting an output. These methods typically assume access to a language model's logits, next-token distributions, or probability scores. Meta-generation algorithms work on partial or full sequences, incorporating domain knowledge, enabling backtracking, and integrating external information. Efficient generation methods aim to reduce token costs and improve the speed of generation. Our survey unifies perspectives from three research communities: traditional natural language processing, modern LLMs, and machine learning systems.
Create account to get full access
Overview
- The paper focuses on how scaling up compute during inference (the process of generating output from a trained language model) can lead to benefits, in contrast to the well-known benefits of scaling compute during training.
- It explores three main areas: token-level generation algorithms, meta-generation algorithms, and efficient generation methods.
- The survey unifies perspectives from traditional natural language processing, modern large language models (LLMs), and machine learning systems research.
Plain English Explanation
The paper discusses how increasing the computational power used during the inference or output generation stage of large language models can lead to improvements, in addition to the well-known benefits of increasing computational power during the training stage.
The researchers explore three main approaches to improving inference-time performance:
-
Token-level generation algorithms: These operate by generating one word at a time or constructing a search space of potential words and selecting the best one. These methods typically rely on the language model's logits (raw output scores), next-token distributions, or probability scores.
-
Meta-generation algorithms: These work on partial or full sequences of generated text, incorporating external knowledge, allowing for backtracking, and integrating additional information beyond just the language model.
-
Efficient generation methods: These aim to reduce the computational cost and improve the speed of the text generation process.
The paper brings together insights and perspectives from the traditional natural language processing field, the latest research on large language models, and the broader machine learning systems community.
Technical Explanation
The paper explores how scaling up computational resources during the inference or output generation stage of large language models can lead to performance improvements, in contrast to the well-established benefits of scaling up compute during the training stage.
The researchers examine three main areas under a unified mathematical framework:
-
Token-level generation algorithms: These algorithms operate by sampling a single token at a time or constructing a token-level search space and then selecting the most appropriate output token. These methods typically assume access to the language model's logits (raw output scores), next-token distributions, or probability scores.
-
Meta-generation algorithms: These algorithms work on partial or full sequences of generated text, incorporating domain knowledge, enabling backtracking, and integrating external information beyond just the language model's outputs.
-
Efficient generation methods: These approaches aim to reduce the computational costs and improve the speed of the text generation process, for example, by leveraging specialized hardware or optimizing the algorithms.
The survey unifies perspectives from three research communities: traditional natural language processing, the latest advancements in large language models, and the broader machine learning systems field.
Critical Analysis
The paper provides a comprehensive overview of the current research on inference-time approaches for large language models, highlighting the potential benefits of scaling up computational resources during this stage. However, the authors acknowledge that the field is still nascent, and there are several caveats and limitations to consider.
One potential issue is that the performance gains from scaling up inference-time compute may be subject to diminishing returns, similar to the challenges faced in scaling up training-time compute. Additionally, the efficient generation methods discussed in the paper may require specialized hardware or software optimizations that may not be widely available or accessible to all researchers and practitioners.
The paper also does not delve deeply into the potential ethical and societal implications of these advancements, such as the impact on the spread of misinformation or the potential for misuse by bad actors. Further research and discussion on these important considerations would be valuable.
Overall, the survey provides a solid foundation for understanding the current state of inference-time approaches for large language models, and encourages readers to think critically about the trade-offs and potential issues that may arise as this field continues to evolve.
Conclusion
This paper offers a comprehensive survey of the latest research on improving the inference or output generation stage of large language models by scaling up computational resources. The researchers explore three main areas: token-level generation algorithms, meta-generation algorithms, and efficient generation methods.
The findings suggest that, in addition to the well-known benefits of scaling up compute during training, there are also potential advantages to scaling up compute during the inference stage. This could lead to improvements in the speed, quality, and efficiency of text generation from large language models.
The survey unifies perspectives from the traditional natural language processing field, the latest advancements in large language models, and the broader machine learning systems research community. While the field is still nascent, this paper provides a valuable foundation for understanding the current state of the art and the potential future directions in this important area of language model research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
6/11/2024
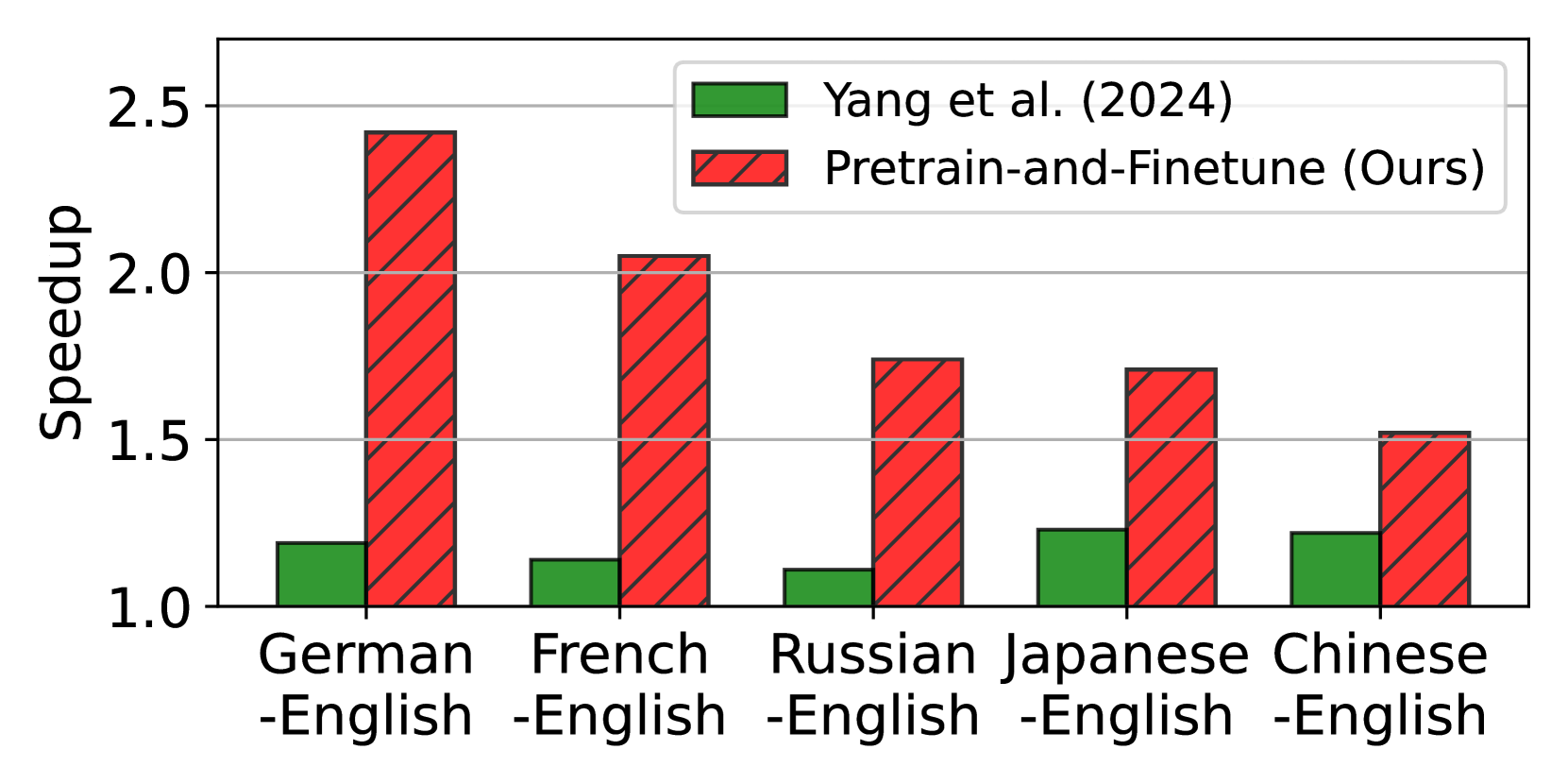
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Euiin Yi, Taehyeon Kim, Hongseok Jeung, Du-Seong Chang, Se-Young Yun
0
0
Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
6/26/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024

GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024