From LIMA to DeepLIMA: following a new path of interoperability

0
💬
Sign in to get full access
Overview
- The article describes the architecture of the LIMA (Libre Multilingual Analyzer) framework and its recent evolution.
- LIMA has been extended to support more languages while preserving its configurable architecture and previously developed analysis components.
- Universal Dependencies corpora were used to train models for over 60 languages, allowing for increased language support and integration into other platforms.
- The integration of Deep Learning Natural Language Processing models and the use of standard annotated collections can be seen as a new path of interoperability.
Plain English Explanation
The researchers have developed a framework called LIMA that can analyze text in multiple languages. They have recently expanded the capabilities of LIMA by adding new text analysis modules that use deep neural networks. This has allowed them to support more languages while still preserving the existing customizable architecture and previously developed analysis tools.
To achieve this, the researchers trained models on Universal Dependencies corpora, WikiNer corpora, and the CoNLL-03 dataset. This allowed them to generate models for over 60 languages that can be integrated into other platforms.
The integration of these deep learning-based natural language processing models, along with the use of standardized annotated data collections, represents a new approach to achieving interoperability. This complements the more traditional technical interoperability that LIMA provides through its Docker-based services.
Technical Explanation
The researchers have extended the functionality of the LIMA framework by adding new text analysis modules based on deep neural networks. This has allowed them to support more languages while preserving the existing configurable architecture and previously developed rule-based and statistical analysis components.
The models were trained on Universal Dependencies 2.5 corpora, WikiNer corpora, and the CoNLL-03 dataset. The use of the Universal Dependencies data allowed the researchers to increase the number of supported languages and generate models that could be integrated into other platforms.
This integration of ubiquitous Deep Learning Natural Language Processing models and the use of standard annotated collections can be viewed as a new path of interoperability, complementing the more standard technical interoperability implemented in LIMA through its Docker-based services available on Docker Hub.
Critical Analysis
The paper does not discuss any significant limitations or caveats of the research. It primarily focuses on the technical details of the LIMA framework and its recent evolution.
One potential area for further research could be an evaluation of the performance and accuracy of the deep learning models across the various languages supported by LIMA. It would be valuable to understand how the models perform in different languages and domains, and whether there are any notable differences in their effectiveness.
Additionally, the paper does not provide much insight into the specific challenges or trade-offs involved in integrating deep learning models into a larger, rule-based and statistical analysis framework like LIMA. Further exploration of these integration challenges could be a fruitful area of investigation.
Conclusion
The researchers have enhanced the LIMA framework by incorporating deep neural network-based text analysis modules, allowing for support of over 60 languages while preserving the existing configurable architecture and analysis components. This integration of deep learning models and the use of standardized data collections represents a new approach to achieving interoperability, complementing the technical interoperability provided by LIMA's Docker-based services.
The expanded language support and the ability to integrate the LIMA models into other platforms have the potential to make the framework more widely accessible and useful for a variety of natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
From LIMA to DeepLIMA: following a new path of interoperability
Victor Bocharov, Romaric Besanc{c}on, Gael de Chalendar, Olivier Ferret, Nasredine Semmar
In this article, we describe the architecture of the LIMA (Libre Multilingual Analyzer) framework and its recent evolution with the addition of new text analysis modules based on deep neural networks. We extended the functionality of LIMA in terms of the number of supported languages while preserving existing configurable architecture and the availability of previously developed rule-based and statistical analysis components. Models were trained for more than 60 languages on the Universal Dependencies 2.5 corpora, WikiNer corpora, and CoNLL-03 dataset. Universal Dependencies allowed us to increase the number of supported languages and to generate models that could be integrated into other platforms. This integration of ubiquitous Deep Learning Natural Language Processing models and the use of standard annotated collections using Universal Dependencies can be viewed as a new path of interoperability, through the normalization of models and data, that are complementary to a more standard technical interoperability, implemented in LIMA through services available in Docker containers on Docker Hub.
Read more9/11/2024
💬
0
Predictive Simultaneous Interpretation: Harnessing Large Language Models for Democratizing Real-Time Multilingual Communication
Kurando Iida, Kenjiro Mimura, Nobuo Ito
This study introduces a groundbreaking approach to simultaneous interpretation by directly leveraging the predictive capabilities of Large Language Models (LLMs). We present a novel algorithm that generates real-time translations by predicting speaker utterances and expanding multiple possibilities in a tree-like structure. This method demonstrates unprecedented flexibility and adaptability, potentially overcoming the structural differences between languages more effectively than existing systems. Our theoretical analysis, supported by illustrative examples, suggests that this approach could lead to more natural and fluent translations with minimal latency. The primary purpose of this paper is to share this innovative concept with the academic community, stimulating further research and development in this field. We discuss the theoretical foundations, potential advantages, and implementation challenges of this technique, positioning it as a significant step towards democratizing multilingual communication.
Read more7/22/2024
📉
0
Advanced Natural-based interaction for the ITAlian language: LLaMAntino-3-ANITA
Marco Polignano, Pierpaolo Basile, Giovanni Semeraro
In the pursuit of advancing natural language processing for the Italian language, we introduce a state-of-the-art Large Language Model (LLM) based on the novel Meta LLaMA-3 model: LLaMAntino-3-ANITA-8B-Inst-DPO-ITA. We fine-tuned the original 8B parameters instruction tuned model using the Supervised Fine-tuning (SFT) technique on the English and Italian language datasets in order to improve the original performance. Consequently, a Dynamic Preference Optimization (DPO) process has been used to align preferences, avoid dangerous and inappropriate answers, and limit biases and prejudices. Our model leverages the efficiency of QLoRA to fine-tune the model on a smaller portion of the original model weights and then adapt the model specifically for the Italian linguistic structure, achieving significant improvements in both performance and computational efficiency. Concurrently, DPO is employed to refine the model's output, ensuring that generated content aligns with quality answers. The synergy between SFT, QLoRA's parameter efficiency and DPO's user-centric optimization results in a robust LLM that excels in a variety of tasks, including but not limited to text completion, zero-shot classification, and contextual understanding. The model has been extensively evaluated over standard benchmarks for the Italian and English languages, showing outstanding results. The model is freely available over the HuggingFace hub and, examples of use can be found in our GitHub repository. https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
Read more5/14/2024
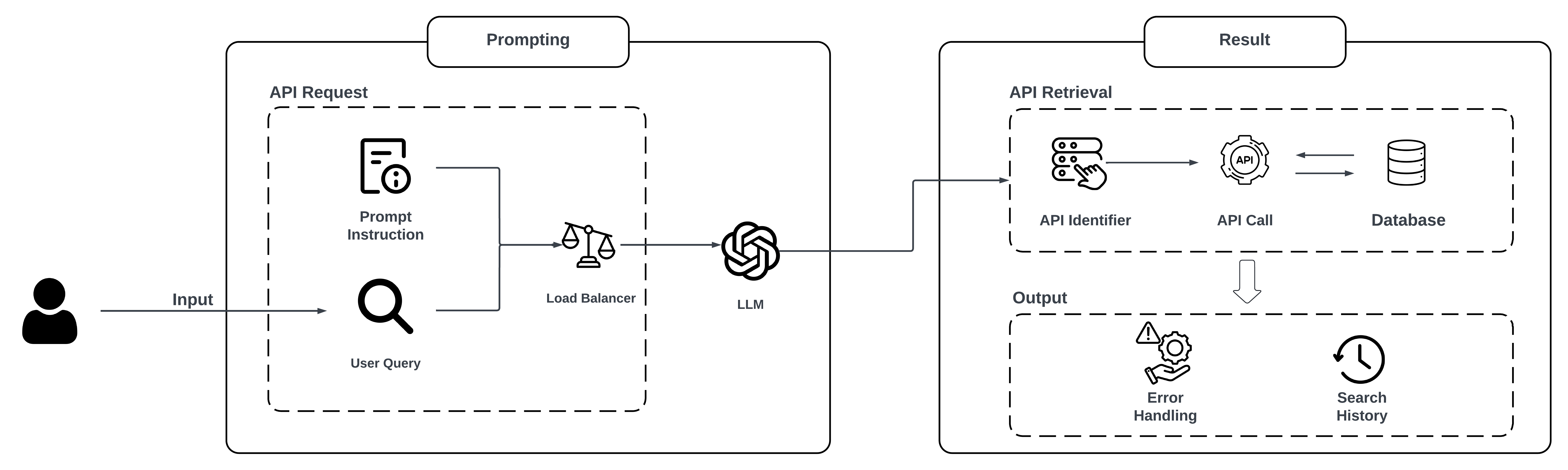
0
New!Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation
Chunliang Tao, Xiaojing Fan, Yahe Yang
As Large Language Models (LLMs) advance in natural language processing, there is growing interest in leveraging their capabilities to simplify software interactions. In this paper, we propose a novel system that integrates LLMs for both classifying natural language inputs into corresponding API calls and automating the creation of sample datasets tailored to specific API functions. By classifying natural language commands, our system allows users to invoke complex software functionalities through simple inputs, improving interaction efficiency and lowering the barrier to software utilization. Our dataset generation approach also enables the efficient and systematic evaluation of different LLMs in classifying API calls, offering a practical tool for developers or business owners to assess the suitability of LLMs for customized API management. We conduct experiments on several prominent LLMs using generated sample datasets for various API functions. The results show that GPT-4 achieves a high classification accuracy of 0.996, while LLaMA-3-8B performs much worse at 0.759. These findings highlight the potential of LLMs to transform API management and validate the effectiveness of our system in guiding model testing and selection across diverse applications.
Read more9/19/2024