From Neurons to Neutrons: A Case Study in Interpretability
2405.17425
0
0

Abstract
Mechanistic Interpretability (MI) promises a path toward fully understanding how neural networks make their predictions. Prior work demonstrates that even when trained to perform simple arithmetic, models can implement a variety of algorithms (sometimes concurrently) depending on initialization and hyperparameters. Does this mean neuron-level interpretability techniques have limited applicability? We argue that high-dimensional neural networks can learn low-dimensional representations of their training data that are useful beyond simply making good predictions. Such representations can be understood through the mechanistic interpretability lens and provide insights that are surprisingly faithful to human-derived domain knowledge. This indicates that such approaches to interpretability can be useful for deriving a new understanding of a problem from models trained to solve it. As a case study, we extract nuclear physics concepts by studying models trained to reproduce nuclear data.
Create account to get full access
Modular Arithmetic Primer
Before diving into the technical details of the paper, it's important to understand the concept of modular arithmetic, which is central to the research. Modular arithmetic is a way of performing arithmetic operations where the results are always within a fixed range, typically 0 to (n-1), where n is the modulus.
For example, in modulo 5 arithmetic, all numbers are represented as remainders when divided by 5. So, 7 becomes 2 (since 7 divided by 5 has a remainder of 2), and 15 becomes 0 (since 15 divided by 5 has no remainder). This type of arithmetic is useful in many areas of mathematics and computer science, including cryptography, coding theory, and the research presented in this paper.
Overview
- The paper explores the use of modular arithmetic in the context of neural networks, specifically in the field of mechanistic interpretability.
- The researchers developed a neural network architecture that can learn to perform modular arithmetic, and they used this as a case study to investigate the interpretability of the network's inner workings.
- The goal was to gain insights into the network's representations and decision-making processes, which could have broader implications for developing more transparent and trustworthy AI systems.
Plain English Explanation
The researchers in this paper were interested in understanding how neural networks work under the hood. They focused on a specific task: teaching a neural network to perform modular arithmetic, which is a type of math where you only deal with the remainders of numbers when divided by a fixed value (called the modulus).
By training the network to do this modular arithmetic task, the researchers could then look at the different "parts" or "modules" of the network and see how they were contributing to the final output. This provided a window into the inner workings of the network and how it was learning to solve the problem.
The key insight was that the network was able to learn representations that closely matched the mathematical structure of modular arithmetic, with different "neurons" or "units" in the network corresponding to different aspects of the modular arithmetic operation. This suggested that neural networks can develop interpretable, mechanistic representations, rather than just being black boxes.
The researchers believe that this type of interpretability, where we can understand how a neural network is making its decisions, could be very important for building safe and trustworthy AI systems, especially in sensitive domains like medical imaging.
Technical Explanation
The paper presents a case study of using modular arithmetic as a lens to investigate the mechanistic interpretability of neural networks. The researchers developed a neural network architecture that was trained to perform modular arithmetic operations, such as addition and multiplication, on input numbers.
By analyzing the activations and representations within the trained network, the researchers were able to identify distinct "modules" that corresponded to the different steps of the modular arithmetic computations. This suggested that the network had learned to develop interpretable, mechanistic representations that closely mirrored the underlying mathematical structure of the problem.
The researchers further explored the network's representations by probing its behavior on symbolic machine learning tasks, such as discovering the nuclear models that govern the network's responses. This provided additional insights into the network's decision-making process and highlighted the potential for using thermodynamics-inspired explanations to better understand the underlying mechanisms of neural networks.
Critical Analysis
The paper presents a compelling case study that demonstrates the potential for neural networks to develop interpretable, mechanistic representations. The researchers' approach of using modular arithmetic as a testbed is well-designed and provides a clear framework for analyzing the network's inner workings.
One potential limitation of the study is the relatively simple nature of the modular arithmetic task, which may not fully capture the complexity of real-world problems that neural networks are often applied to. However, the researchers acknowledge this and suggest that the insights gained from this case study could be extended to more complex domains, such as quantum neural networks.
Additionally, the paper raises interesting questions about the role of thermodynamics-inspired explanations in understanding the mechanisms of neural networks. While the researchers provide some preliminary insights, further exploration of this area could lead to new and more comprehensive frameworks for interpreting the behavior of complex AI systems.
Conclusion
The paper's exploration of modular arithmetic as a case study for mechanistic interpretability represents an important step towards developing more transparent and trustworthy AI systems. By demonstrating that neural networks can learn to develop interpretable representations that closely reflect the underlying mathematical structure of a problem, the researchers have opened up new avenues for understanding the inner workings of these powerful machine learning models.
The insights gained from this study could have far-reaching implications, particularly in sensitive domains like medical imaging, where the interpretability and explainability of AI-powered decision-making processes are crucial. As the field of AI continues to advance, research that sheds light on the mechanisms behind neural network behavior will be increasingly valuable for building safe and reliable AI systems that can be trusted to make important decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
On the Interpretability of Quantum Neural Networks
Lirande Pira, Chris Ferrie
0
0
Interpretability of artificial intelligence (AI) methods, particularly deep neural networks, is of great interest. This heightened focus stems from the widespread use of AI-backed systems. These systems, often relying on intricate neural architectures, can exhibit behavior that is challenging to explain and comprehend. The interpretability of such models is a crucial component of building trusted systems. Many methods exist to approach this problem, but they do not apply straightforwardly to the quantum setting. Here, we explore the interpretability of quantum neural networks using local model-agnostic interpretability measures commonly utilized for classical neural networks. Following this analysis, we generalize a classical technique called LIME, introducing Q-LIME, which produces explanations of quantum neural networks. A feature of our explanations is the delineation of the region in which data samples have been given a random label, likely subjects of inherently random quantum measurements. We view this as a step toward understanding how to build responsible and accountable quantum AI models.
4/22/2024
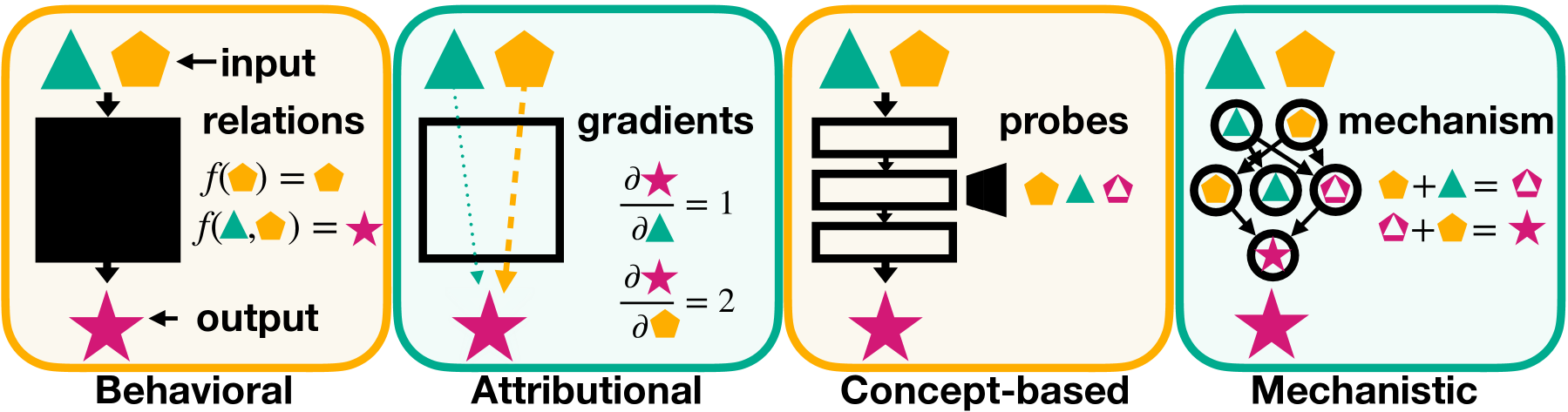
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska, Efstratios Gavves
0
0
Understanding AI systems' inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse-engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
4/23/2024
📈
Provable Guarantees for Model Performance via Mechanistic Interpretability
Jason Gross, Rajashree Agrawal, Thomas Kwa, Euan Ong, Chun Hei Yip, Alex Gibson, Soufiane Noubir, Lawrence Chan
0
0
In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
6/26/2024

A Framework for Interpretability in Machine Learning for Medical Imaging
Alan Q. Wang, Batuhan K. Karaman, Heejong Kim, Jacob Rosenthal, Rachit Saluja, Sean I. Young, Mert R. Sabuncu
0
0
Interpretability for machine learning models in medical imaging (MLMI) is an important direction of research. However, there is a general sense of murkiness in what interpretability means. Why does the need for interpretability in MLMI arise? What goals does one actually seek to address when interpretability is needed? To answer these questions, we identify a need to formalize the goals and elements of interpretability in MLMI. By reasoning about real-world tasks and goals common in both medical image analysis and its intersection with machine learning, we identify five core elements of interpretability: localization, visual recognizability, physical attribution, model transparency, and actionability. From this, we arrive at a framework for interpretability in MLMI, which serves as a step-by-step guide to approaching interpretability in this context. Overall, this paper formalizes interpretability needs in the context of medical imaging, and our applied perspective clarifies concrete MLMI-specific goals and considerations in order to guide method design and improve real-world usage. Our goal is to provide practical and didactic information for model designers and practitioners, inspire developers of models in the medical imaging field to reason more deeply about what interpretability is achieving, and suggest future directions of interpretability research.
4/17/2024