From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding

0
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) integrated with visual encoders have shown promising performance in visual understanding tasks.
- Multi-Modal Large Language Models (MM-LLMs) exhibit variations in model design and training for understanding different types of visual data, including images, short videos, and long videos.
- This paper focuses on the unique challenges of long video understanding compared to static image and short video understanding.
Plain English Explanation
The integration of Large Language Models (LLMs) with visual encoders has led to impressive results in visual understanding tasks. These Multi-Modal Large Language Models (MM-LLMs) can comprehend and generate human-like text to reason about visual information.
However, the nature of visual data varies widely, from static images to short videos to long videos. As a result, MM-LLMs have been designed and trained differently to handle these diverse types of visual information.
Compared to static images, short videos contain sequential frames with both spatial and temporal information within individual events. In contrast, long videos consist of multiple events, with both within-event and long-term temporal information.
This paper aims to summarize the advancements of MM-LLMs in understanding visual data, with a particular focus on the unique challenges posed by long video understanding. The researchers review the differences between various visual understanding tasks and highlight the difficulties in long video understanding, such as capturing more fine-grained spatiotemporal details, dynamic events, and long-term dependencies.
Technical Explanation
The paper provides a detailed review of the advancements in MM-LLMs for understanding long videos. It examines the model design and training methodologies used to address the specific challenges of long video understanding, which differ from those for static images and short videos.
The researchers compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for improving long video understanding using these models. The paper delves into the technical aspects of the research, including the unique architectural features and training approaches developed to handle the complexity of long videos.
Critical Analysis
The paper acknowledges the limitations of existing MM-LLMs in fully capturing the nuances of long video understanding. It highlights the need for further research to develop more robust and efficient models that can effectively handle the increased spatiotemporal complexity and long-term dependencies inherent in long video data.
While the paper provides a comprehensive review of the current state of the art, it does not extensively discuss potential biases or ethical considerations that may arise from the widespread use of these models in real-world applications. As MM-LLMs become more prevalent, it will be crucial to address these important aspects to ensure their responsible and equitable deployment.
Conclusion
This paper offers a valuable survey of the advancements in MM-LLMs for visual understanding, with a particular focus on the unique challenges of long video understanding. By summarizing the key differences between various visual understanding tasks and the specific model design and training approaches developed to address long video understanding, the paper provides a thorough overview of the current state of the art in this rapidly evolving field.
The insights and discussions presented in the paper can inform future research and development efforts, ultimately contributing to the advancement of multimodal AI systems that can effectively process and comprehend complex visual data, including long-form video content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Heqing Zou (Xiao Jie), Tianze Luo (Xiao Jie), Guiyang Xie (Xiao Jie), Victor (Xiao Jie), Zhang, Fengmao Lv, Guangcong Wang, Juanyang Chen, Zhuochen Wang, Hansheng Zhang, Huaijian Zhang
The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
Read more9/30/2024
0
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
Empowered by Large Language Models (LLMs), recent advancements in Video-based LLMs (VideoLLMs) have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a simple yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples show that our model produces more precise responses for long video understanding. Code is available at https://github.com/ziplab/LongVLM.
Read more7/23/2024

0
Video Understanding with Large Language Models: A Survey
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, Ali Vosoughi, Chao Huang, Zeliang Zhang, Pinxin Liu, Mingqian Feng, Feng Zheng, Jianguo Zhang, Ping Luo, Jiebo Luo, Chenliang Xu
With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of large language models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of recent advancements in video understanding that harness the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended multi-granularity (general, temporal, and spatiotemporal) reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into three main types: Video Analyzer x LLM, Video Embedder x LLM, and (Analyzer + Embedder) x LLM. Furthermore, we identify five sub-types based on the functions of LLMs in Vid-LLMs: LLM as Summarizer, LLM as Manager, LLM as Text Decoder, LLM as Regressor, and LLM as Hidden Layer. Furthermore, this survey presents a comprehensive study of the tasks, datasets, benchmarks, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding.
Read more7/25/2024
0
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
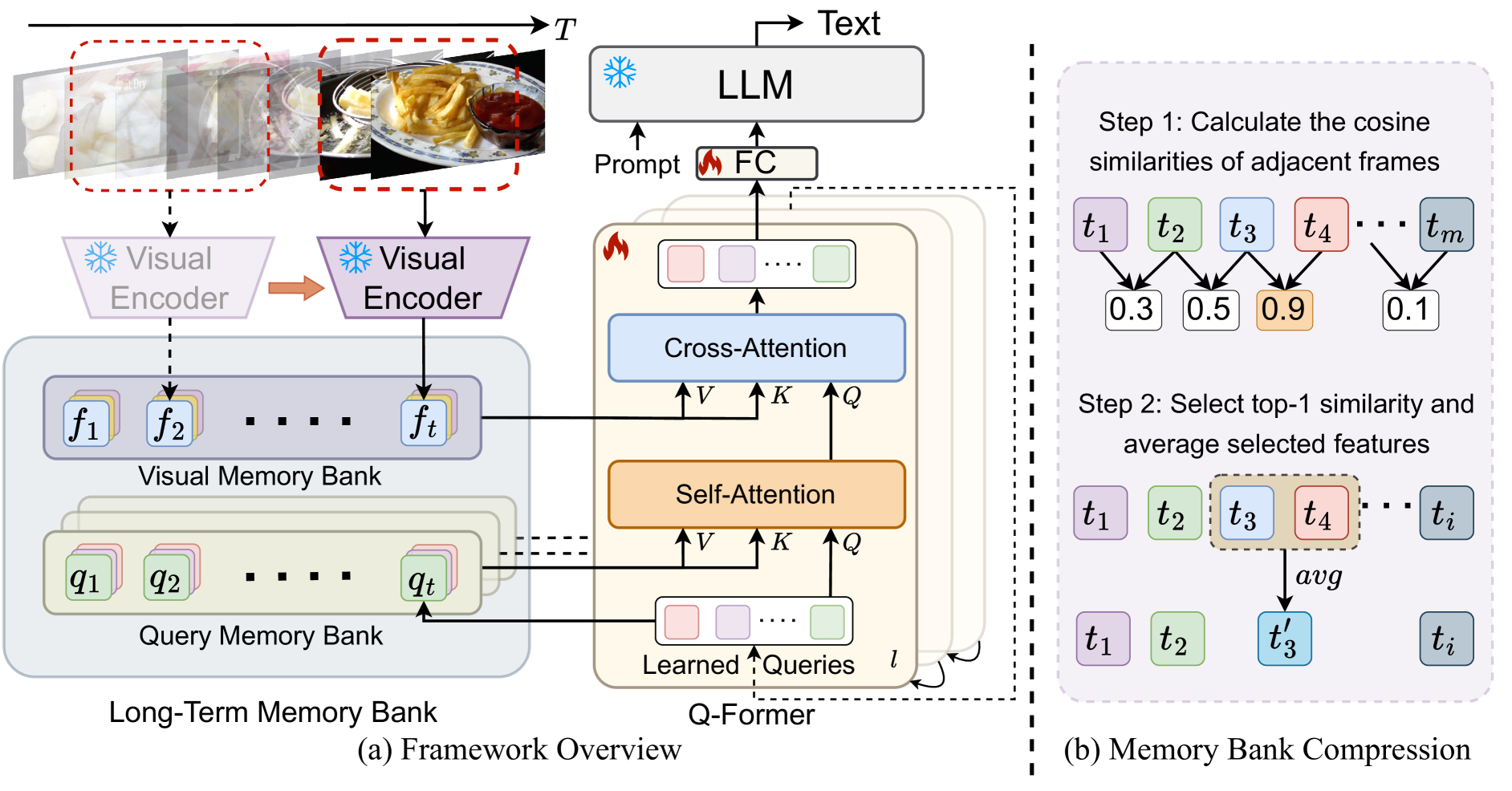
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Read more4/9/2024