From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
2405.19883
0
0
Abstract
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Create account to get full access
Overview
• This paper explores the theoretical foundations of using large language models (LLMs) to power autonomous systems that can translate natural language instructions into actions.
• The authors investigate the challenges and opportunities in bridging the gap between language understanding and task execution, drawing insights from reinforcement learning, multi-agent reinforcement learning, and context learning research.
• Key areas explored include using LLMs as policy teachers for autonomous agents, prompting techniques to enhance cross-modal understanding, and the implications for real-world applications like robotics and self-driving cars.
Plain English Explanation
This paper looks at how we can use powerful language models, known as large language models (LLMs), to control autonomous systems that can understand and act on natural language instructions. The authors explore the challenges and opportunities in bridging the gap between understanding language and actually carrying out tasks in the real world.
They draw insights from various AI research areas, like reinforcement learning (where agents learn by trial-and-error) and multi-agent systems (where multiple AI agents cooperate). The paper investigates how LLMs could be used as "teachers" to train autonomous agents, and how special prompting techniques can help these systems better understand the connections between words and physical actions, such as in robotics or self-driving cars.
The key idea is to leverage the impressive language understanding capabilities of LLMs to control autonomous systems that can follow complex natural language instructions and translate them into real-world actions. This could have significant implications for a wide range of applications where bridging the gap between language and task execution is crucial.
Technical Explanation
The paper begins by highlighting the potential of using LLMs to power autonomous systems that can translate natural language instructions into actions. The authors note that while LLMs have demonstrated remarkable language understanding capabilities, bridging the gap to physical task execution remains a significant challenge.
To address this, the paper draws on insights from several relevant research areas. It explores the use of reinforcement learning to train autonomous agents, where they learn by trial-and-error to map language to actions. The authors also investigate multi-agent reinforcement learning approaches, where multiple agents cooperate to accomplish complex tasks.
Additionally, the paper examines the role of context learning in autonomous systems, highlighting the importance of understanding the relevant context to translate language into appropriate actions.
A key focus of the paper is the idea of using LLMs as policy teachers for autonomous agents. The authors explore how the language understanding capabilities of LLMs can be leveraged to guide and accelerate the training of these agents, enabling them to more effectively map language to actions.
The paper also investigates prompting techniques to enhance the cross-modal understanding of LLM-driven autonomous systems, allowing them to better connect language to the relevant sensory inputs and physical actions.
Critical Analysis
The paper presents a thoughtful exploration of the theoretical foundations for leveraging LLMs to power autonomous systems. However, the authors acknowledge several caveats and limitations that warrant further research.
One key challenge is the complexity of translating natural language instructions into precise, executable actions. While LLMs excel at language understanding, they may still struggle with the nuances and context required to reliably map words to physical tasks. The authors suggest that continued advancements in areas like reinforcement learning and multi-agent coordination will be crucial to address this.
Additionally, the paper notes the potential for issues related to safety, robustness, and interpretability in LLM-driven autonomous systems. As these systems become more complex and capable, ensuring reliable and transparent decision-making will be critical, especially in high-stakes applications like robotics and self-driving cars.
Further research is also needed to better understand the limitations of current prompting techniques and explore more advanced approaches to enhance the cross-modal capabilities of LLM-based autonomous agents.
Conclusion
This paper provides a comprehensive exploration of the theoretical underpinnings for using large language models (LLMs) to power autonomous systems that can translate natural language instructions into actions. By drawing insights from related AI research areas, the authors shed light on the challenges and opportunities in bridging the gap between language understanding and physical task execution.
The key ideas presented, such as using LLMs as policy teachers, advancing prompting techniques for cross-modal understanding, and leveraging reinforcement learning and multi-agent approaches, have the potential to significantly impact the development of autonomous systems with robust language-to-action capabilities. As the field continues to evolve, addressing the remaining challenges around safety, robustness, and interpretability will be crucial for the successful deployment of these systems in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
💬
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
0
0
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
4/23/2024
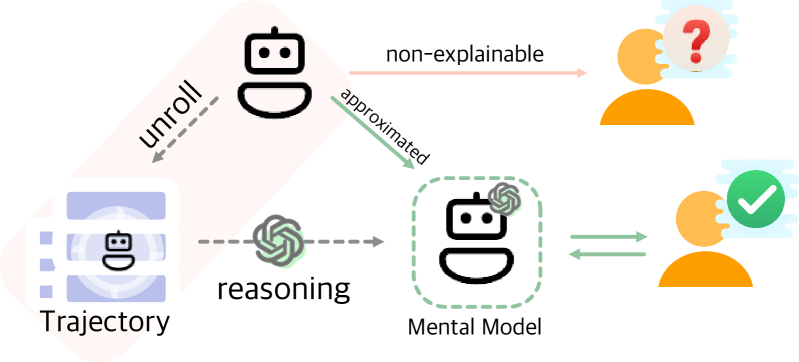
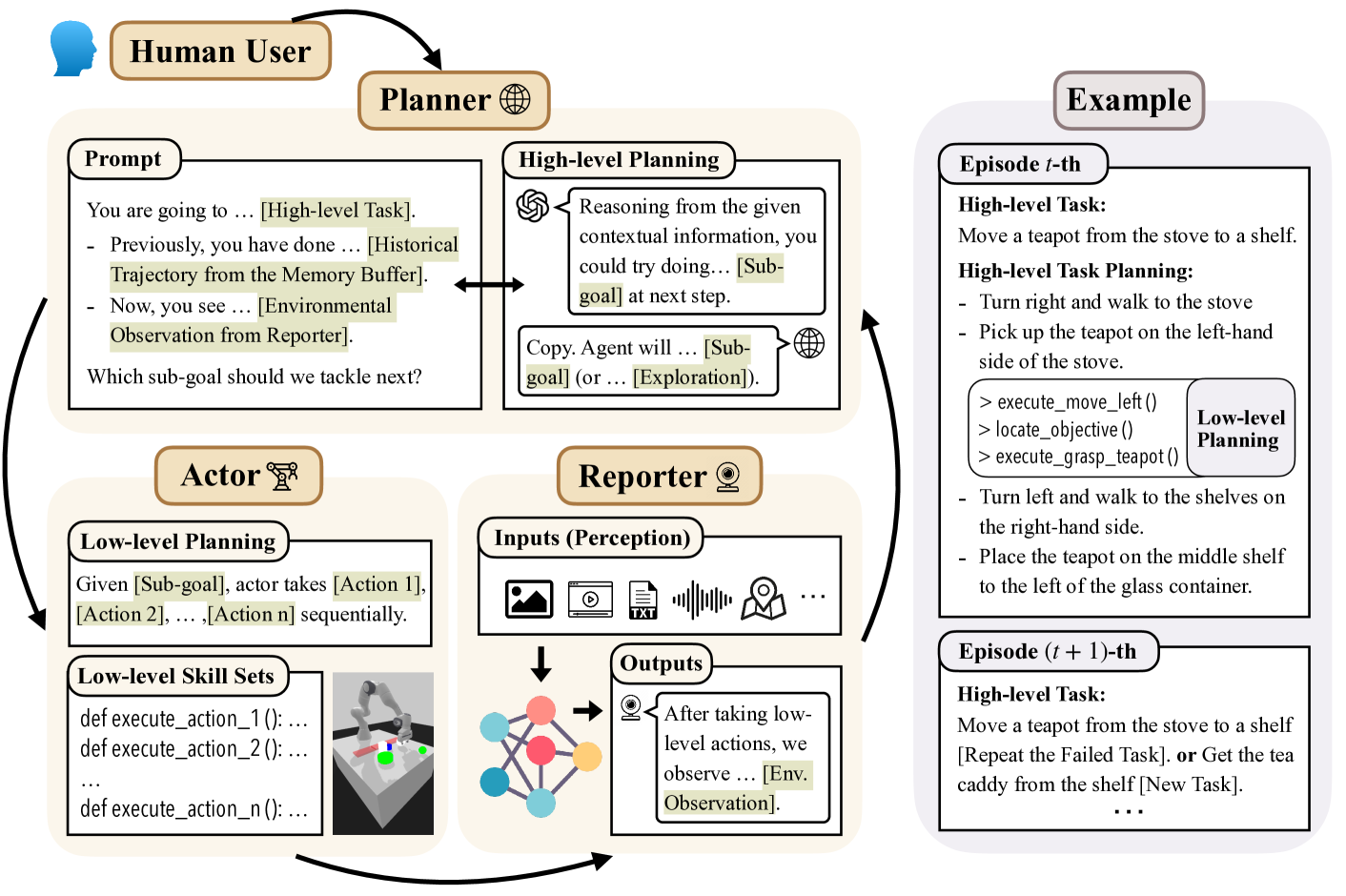
Mental Modeling of Reinforcement Learning Agents by Language Models
Wenhao Lu, Xufeng Zhao, Josua Spisak, Jae Hee Lee, Stefan Wermter
0
0
Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
6/27/2024
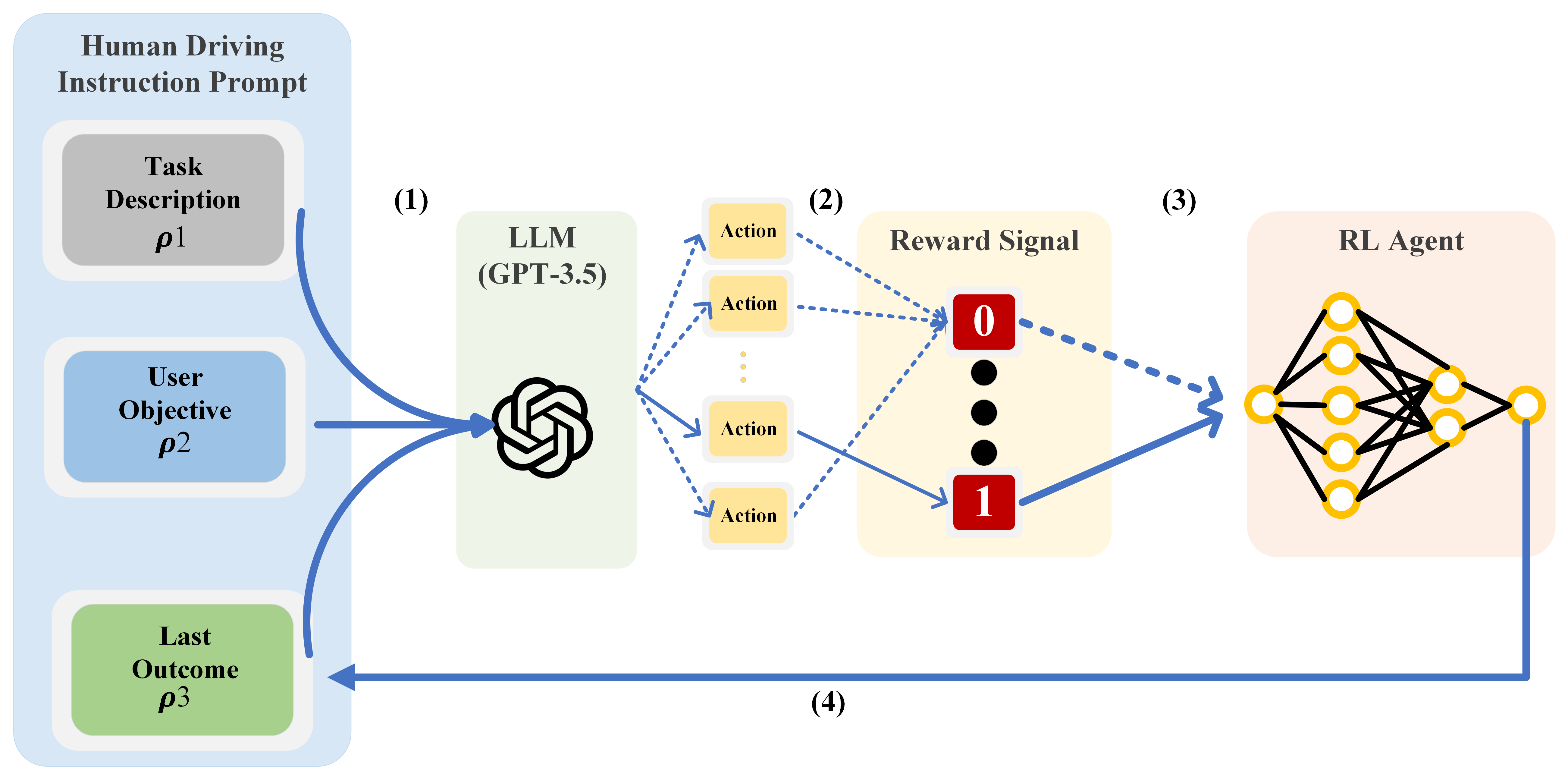
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
0
0
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
5/8/2024