FT2Ra: A Fine-Tuning-Inspired Approach to Retrieval-Augmented Code Completion

0
Sign in to get full access
Overview
- The paper proposes a novel approach called FT2Ra for retrieval-augmented code completion
- FT2Ra leverages fine-tuning techniques to improve the performance of retrieval-based language models for code completion tasks
- The authors demonstrate that FT2Ra outperforms existing code completion models on several benchmark datasets
Plain English Explanation
Code completion is a valuable tool for software developers, allowing them to quickly and easily complete partially written code. Existing code completion models use language models trained on large amounts of code data to predict the most likely next code tokens. However, these models can struggle with rare or complex code constructs.
The FT2Ra approach aims to address this by combining a language model with a retrieval system. The retrieval system finds similar code snippets from a database, which are then used to enhance the language model's predictions. This allows the model to draw upon a broader set of code knowledge, including rare or complex patterns, to provide more accurate completions.
The key innovation of FT2Ra is the way it integrates the retrieval system with the language model. Rather than treating them as separate components, FT2Ra uses a fine-tuning approach to tightly couple the two. This allows the language model to learn how to best utilize the retrieved code snippets, resulting in improved overall performance on code completion tasks.
Technical Explanation
The FT2Ra model consists of two main components: a retrieval module and a language model. The retrieval module uses a dense vector index to efficiently find relevant code snippets from a large database given a partial code input. The language model is a transformer-based model that has been pre-trained on a large corpus of code data.
During training, FT2Ra fine-tunes the language model to incorporate the retrieved code snippets. Specifically, the model learns to attend to the relevant snippets when predicting the next code token. This allows the language model to leverage the broader code knowledge captured by the retrieval system.
The authors evaluate FT2Ra on several code completion benchmarks, including CodeXGLUE and DeepSim. They show that FT2Ra outperforms previous state-of-the-art retrieval-augmented models as well as standalone language models. The improvements are especially pronounced for rare and complex code constructs, demonstrating the benefits of the retrieval-augmentation approach.
Critical Analysis
The paper provides a thorough evaluation of the FT2Ra model, including comparisons to several strong baselines. The results indicate that the fine-tuning-based integration of retrieval and language modeling is an effective approach for improving code completion performance.
One potential limitation is the reliance on a pre-defined database of code snippets. While the authors show that FT2Ra can leverage this database effectively, it may be challenging to maintain and update such a database in real-world software development scenarios. Exploring dynamic retrieval approaches that can adapt to changing codebases could be a fruitful area for future research.
Additionally, the paper does not provide much insight into the types of code constructs or contexts where FT2Ra performs best. Understanding these patterns could help guide the development of even more effective retrieval-augmented models for code completion.
Conclusion
The FT2Ra approach proposed in this paper represents an important step forward in the field of retrieval-augmented code completion. By tightly integrating retrieval and language modeling through fine-tuning, FT2Ra is able to leverage a broader set of code knowledge to generate more accurate completions, especially for rare and complex code patterns.
While there are some potential limitations to the current approach, the strong empirical results suggest that retrieval-augmentation is a promising direction for improving code completion tools. As software systems continue to grow in complexity, techniques like FT2Ra will become increasingly valuable for helping developers write code more efficiently and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FT2Ra: A Fine-Tuning-Inspired Approach to Retrieval-Augmented Code Completion
Qi Guo, Xiaohong Li, Xiaofei Xie, Shangqing Liu, Ze Tang, Ruitao Feng, Junjie Wang, Jidong Ge, Lei Bu
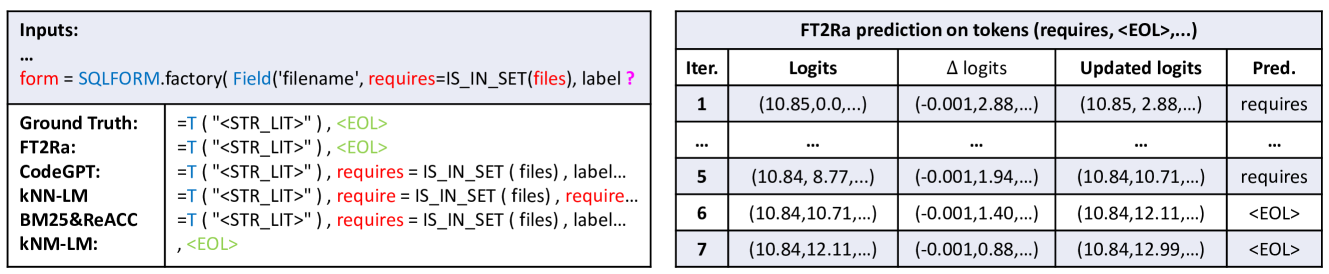
The rise of code pre-trained models has significantly enhanced various coding tasks, such as code completion, and tools like GitHub Copilot. However, the substantial size of these models, especially large models, poses a significant challenge when it comes to fine-tuning them for specific downstream tasks. As an alternative approach, retrieval-based methods have emerged as a promising solution, augmenting model predictions without the need for fine-tuning. Despite their potential, a significant challenge is that the designs of these methods often rely on heuristics, leaving critical questions about what information should be stored or retrieved and how to interpolate such information for augmenting predictions. To tackle this challenge, we first perform a theoretical analysis of the fine-tuning process, highlighting the importance of delta logits as a catalyst for improving model predictions. Building on this insight, we develop a novel retrieval-based method, FT2Ra, which aims to mimic genuine fine-tuning. While FT2Ra adopts a retrieval-based mechanism, it uniquely adopts a paradigm with a learning rate and multi-epoch retrievals, which is similar to fine-tuning.In token-level completion, which represents a relatively easier task, FT2Ra achieves a 4.29% improvement in accuracy compared to the best baseline method on UniXcoder. In the more challenging line-level completion task, we observe a substantial more than twice increase in Exact Match (EM) performance, indicating the significant advantages of our theoretical analysis. Notably, even when operating without actual fine-tuning, FT2Ra exhibits competitive performance compared to the models with real fine-tuning.
Read more4/3/2024
🏷️
0
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, Scott Yih
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
Read more5/7/2024
0
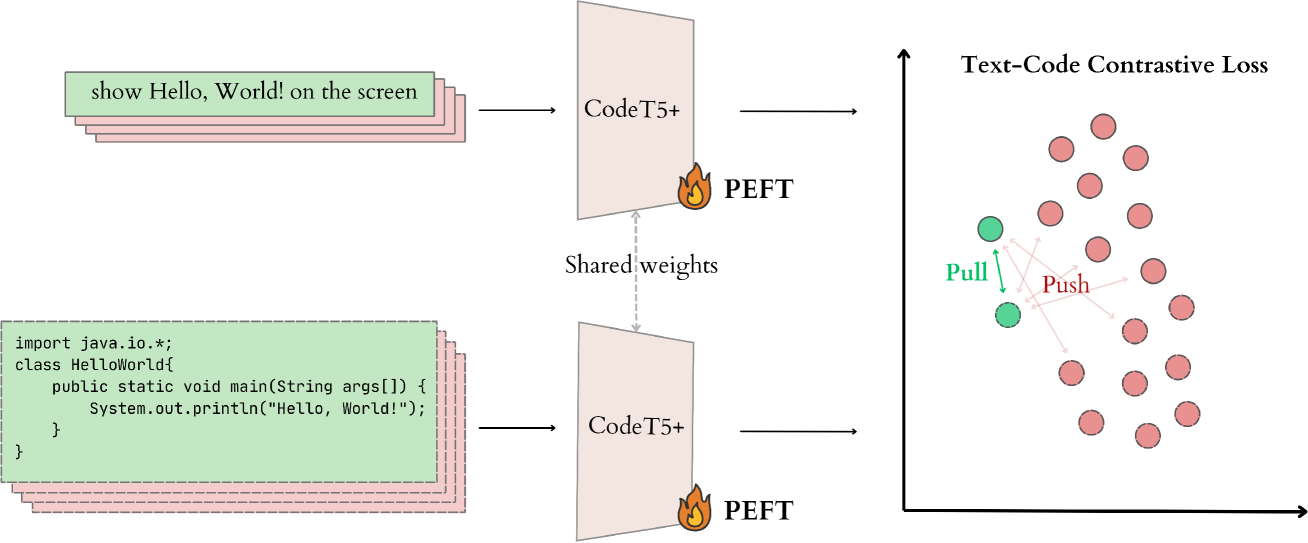
Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning
Karim Galliamov, Leila Khaertdinova, Karina Denisova
The latest developments in Natural Language Processing (NLP) have demonstrated remarkable progress in a code-text retrieval problem. As the Transformer-based models used in this task continue to increase in size, the computational costs and time required for end-to-end fine-tuning become substantial. This poses a significant challenge for adapting and utilizing these models when computational resources are limited. Motivated by these concerns, we propose a fine-tuning framework that leverages Parameter-Efficient Fine-Tuning (PEFT) techniques. Moreover, we adopt contrastive learning objectives to improve the quality of bimodal representations learned by transformer models. Additionally, for PEFT methods we provide extensive benchmarking, the lack of which has been highlighted as a crucial problem in the literature. Based on the thorough experimentation with the CodeT5+ model conducted on two datasets, we demonstrate that the proposed fine-tuning framework has the potential to improve code-text retrieval performance by tuning only 0.4% parameters at most.
Read more5/8/2024
0
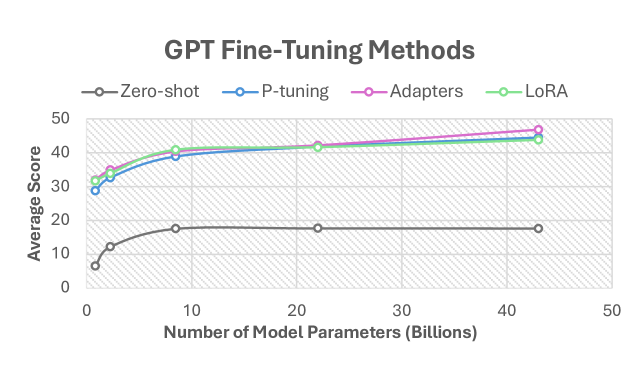
GPT vs RETRO: Exploring the Intersection of Retrieval and Parameter-Efficient Fine-Tuning
Aleksander Ficek, Jiaqi Zeng, Oleksii Kuchaiev
Parameter-Efficient Fine-Tuning (PEFT) and Retrieval-Augmented Generation (RAG) have become popular methods for adapting large language models while minimizing compute requirements. In this paper, we apply PEFT methods (P-tuning, Adapters, and LoRA) to a modified Retrieval-Enhanced Transformer (RETRO) and a baseline GPT model across several sizes, ranging from 823 million to 48 billion parameters. We show that RETRO models outperform GPT models in zero-shot settings due to their unique pre-training process but GPT models have higher performance potential with PEFT. Additionally, our study indicates that 8B parameter models strike an optimal balance between cost and performance and P-tuning lags behind other PEFT techniques. We further provide a comparative analysis of between applying PEFT to an Instruction-tuned RETRO model and base RETRO model. This work presents the first comprehensive comparison of various PEFT methods integrated with RAG, applied to both GPT and RETRO models, highlighting their relative performance.
Read more7/8/2024