GPT vs RETRO: Exploring the Intersection of Retrieval and Parameter-Efficient Fine-Tuning

0
Sign in to get full access
Overview
- The paper explores the intersection of retrieval and parameter-efficient fine-tuning techniques for large language models.
- It compares the performance of the GPT model with the RETRO model, which incorporates retrieval components.
- The research investigates how parameter-efficient fine-tuning methods can be applied to retrieval-enhanced models to improve their efficiency and effectiveness.
Plain English Explanation
The paper looks at two different approaches for using large language models like GPT for various tasks. One approach, called GPT, trains the model on a lot of text data to give it a broad understanding of language. The other approach, called RETRO, adds a retrieval component to the model, which allows it to look up and use relevant information from a database when making predictions.
The researchers wanted to see how well these two approaches perform, and whether they can be combined to get the best of both worlds. They used techniques called "parameter-efficient fine-tuning" to adjust the models for specific tasks without having to completely retrain them from scratch. This can make the models more efficient and effective for real-world applications.
The key idea is to find a way to leverage the broad language understanding of GPT-style models, while also taking advantage of the targeted knowledge and retrieval capabilities of RETRO-style models. By combining these approaches, the researchers hope to create language models that are both powerful and efficient.
Technical Explanation
The paper compares the performance of the GPT and RETRO models, which represent two distinct approaches to leveraging large language models. GPT models are trained on vast amounts of text data to develop broad language understanding, while RETRO models incorporate retrieval components to access relevant external information.
The researchers investigate how parameter-efficient fine-tuning techniques can be applied to these retrieval-enhanced models to improve their efficiency and effectiveness. This includes methods like representation learning and query-dependent fine-tuning.
By exploring the interplay between retrieval and parameter-efficient fine-tuning, the paper aims to shed light on how to create more powerful and efficient language models that can leverage the strengths of both approaches.
Critical Analysis
The paper provides a thoughtful exploration of the trade-offs and synergies between retrieval-based and parameter-efficient fine-tuning techniques for large language models. However, the authors acknowledge that their analysis is limited to a specific set of tasks and datasets, and further research is needed to fully understand the generalizability of their findings.
Additionally, the paper does not delve deeply into the potential limitations or potential negative societal impacts of these technologies. As with any powerful AI systems, there are valid concerns around issues like data biases, transparency, and accountability that should be carefully considered.
Nonetheless, the paper makes a valuable contribution to the ongoing efforts to develop more efficient and effective language models that can be deployed in real-world applications. By bridging the gap between retrieval and fine-tuning, the work opens up new avenues for further research and innovation in this rapidly evolving field.
Conclusion
This paper investigates the intersection of retrieval and parameter-efficient fine-tuning techniques for large language models, with the goal of creating more powerful and efficient systems. By comparing the performance of GPT and RETRO models, and exploring how to apply parameter-efficient methods to retrieval-enhanced architectures, the researchers shed light on promising approaches for leveraging the strengths of both paradigms.
While the analysis is limited in scope, the paper represents an important step towards developing language models that can balance broad understanding with targeted knowledge retrieval, all while maintaining high efficiency. As the field of AI continues to advance, continued research in this direction could yield significant benefits for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GPT vs RETRO: Exploring the Intersection of Retrieval and Parameter-Efficient Fine-Tuning
Aleksander Ficek, Jiaqi Zeng, Oleksii Kuchaiev
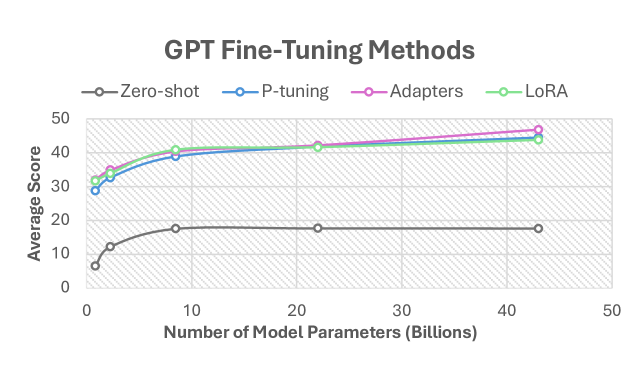
Parameter-Efficient Fine-Tuning (PEFT) and Retrieval-Augmented Generation (RAG) have become popular methods for adapting large language models while minimizing compute requirements. In this paper, we apply PEFT methods (P-tuning, Adapters, and LoRA) to a modified Retrieval-Enhanced Transformer (RETRO) and a baseline GPT model across several sizes, ranging from 823 million to 48 billion parameters. We show that RETRO models outperform GPT models in zero-shot settings due to their unique pre-training process but GPT models have higher performance potential with PEFT. Additionally, our study indicates that 8B parameter models strike an optimal balance between cost and performance and P-tuning lags behind other PEFT techniques. We further provide a comparative analysis of between applying PEFT to an Instruction-tuned RETRO model and base RETRO model. This work presents the first comprehensive comparison of various PEFT methods integrated with RAG, applied to both GPT and RETRO models, highlighting their relative performance.
Read more7/8/2024

0
New!Comparing Retrieval-Augmentation and Parameter-Efficient Fine-Tuning for Privacy-Preserving Personalization of Large Language Models
Alireza Salemi, Hamed Zamani
Privacy-preserving methods for personalizing large language models (LLMs) are relatively under-explored. There are two schools of thought on this topic: (1) generating personalized outputs by personalizing the input prompt through retrieval augmentation from the user's personal information (RAG-based methods), and (2) parameter-efficient fine-tuning of LLMs per user that considers efficiency and space limitations (PEFT-based methods). This paper presents the first systematic comparison between two approaches on a wide range of personalization tasks using seven diverse datasets. Our results indicate that RAG-based and PEFT-based personalization methods on average yield 14.92% and 1.07% improvements over the non-personalized LLM, respectively. We find that combining RAG with PEFT elevates these improvements to 15.98%. Additionally, we identify a positive correlation between the amount of user data and PEFT's effectiveness, indicating that RAG is a better choice for cold-start users (i.e., user's with limited personal data).
Read more9/17/2024

0
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
Read more4/30/2024

0
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Tong Su, Xin Peng, Sarubi Thillainathan, David Guzm'an, Surangika Ranathunga, En-Shiun Annie Lee
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
Read more4/8/2024