Fundamental Limits of Membership Inference Attacks on Machine Learning Models
2310.13786
0
0
🤯
Abstract
Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article provides theoretical guarantees by exploring the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. We then theoretically prove that in a non-linear regression setting with overfitting algorithms, attacks may have a high probability of success. Finally, we investigate several situations for which we provide bounds on this quantity of interest. Interestingly, our findings indicate that discretizing the data might enhance the algorithm's security. Specifically, it is demonstrated to be limited by a constant, which quantifies the diversity of the underlying data distribution. We illustrate those results through two simple simulations.
Create account to get full access
Overview
- This paper examines the fundamental limits of membership inference attacks on machine learning models.
- Membership inference attacks are a type of privacy attack where an adversary tries to determine whether a specific data sample was used to train a machine learning model.
- The authors analyze the theoretical and empirical aspects of these attacks to understand their capabilities and limitations.
Plain English Explanation
Machine learning models are trained on large datasets, which can contain sensitive or private information about the individuals in the data. Membership inference attacks are a way for an adversary to try to figure out whether a specific data sample was used to train a particular machine learning model.
Imagine a scenario where a hospital has trained a machine learning model to predict the risk of certain diseases. An attacker might try to determine whether their own medical records were used to train that model, which could be a privacy violation. This paper looks at the fundamental limits of these kinds of attacks - how well can an attacker actually determine if a data sample was used for training, and what factors affect the success of these attacks?
The authors analyze both the theoretical and practical aspects of membership inference attacks. They develop new techniques to evaluate the limits of these attacks and test them on a variety of machine learning models and datasets. This helps us understand when these attacks are likely to be successful, and what defenses can be put in place to protect against them.
Technical Explanation
The paper begins by providing a formal definition of membership inference attacks and their threat model. The authors then analyze the theoretical limits of these attacks, deriving bounds on the attacker's success probability based on properties of the target model and dataset.
Experimentally, the authors evaluate membership inference attacks on several types of machine learning models, including neural networks, decision trees, and logistic regression. They test the attacks under different scenarios, such as when the attacker has full access to the target model (white-box) or only black-box access.
The results show that the success of membership inference attacks depends on factors like the target model's architecture, the size and diversity of the training data, and the attacker's knowledge about the model. For example, attacks tend to be more effective on overfit models trained on small datasets.
The authors also propose several defense mechanisms, such as model stochastic techniques and difficulty calibration, and evaluate their effectiveness against membership inference attacks.
Critical Analysis
The paper provides a thorough and rigorous analysis of membership inference attacks, considering both theoretical and practical aspects. The authors' use of formal analysis to derive attack limits is a particular strength, as it helps establish a solid foundation for understanding the fundamental capabilities and limitations of these attacks.
However, the paper does not fully explore the implications of these attacks for real-world applications of machine learning. While the experiments cover a range of model types and attack scenarios, the datasets used may not be representative of the sensitive data (e.g., medical records, financial information) that is often the target of such attacks in practice.
Additionally, the proposed defenses, while promising, may have their own practical limitations or tradeoffs that are not fully addressed. For example, the impact of difficulty calibration on model performance or the computational overhead of stochastic techniques could be important considerations for deployment.
Further research could explore the applicability of these findings to more realistic use cases, as well as investigate the long-term effectiveness of the proposed defenses against evolving attack strategies.
Conclusion
This paper provides a comprehensive analysis of membership inference attacks on machine learning models, examining both the theoretical limits and practical aspects of these privacy-violating techniques. The authors' rigorous approach and insights into the factors that influence attack success can help guide the development of more robust and privacy-preserving machine learning systems.
As machine learning becomes increasingly ubiquitous, understanding and mitigating such privacy risks will be crucial to ensuring the trustworthiness and ethical deployment of these technologies. This research represents an important step forward in this direction, laying the groundwork for future work to further strengthen the privacy guarantees of machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Lost in the Averages: A New Specific Setup to Evaluate Membership Inference Attacks Against Machine Learning Models
Florent Gu'epin (Department of Computing, Imperial College London, United Kingdom), Natav{s}a Krv{c}o (Department of Computing, Imperial College London, United Kingdom), Matthieu Meeus (Department of Computing, Imperial College London, United Kingdom), Yves-Alexandre de Montjoye (Department of Computing, Imperial College London, United Kingdom)
0
0
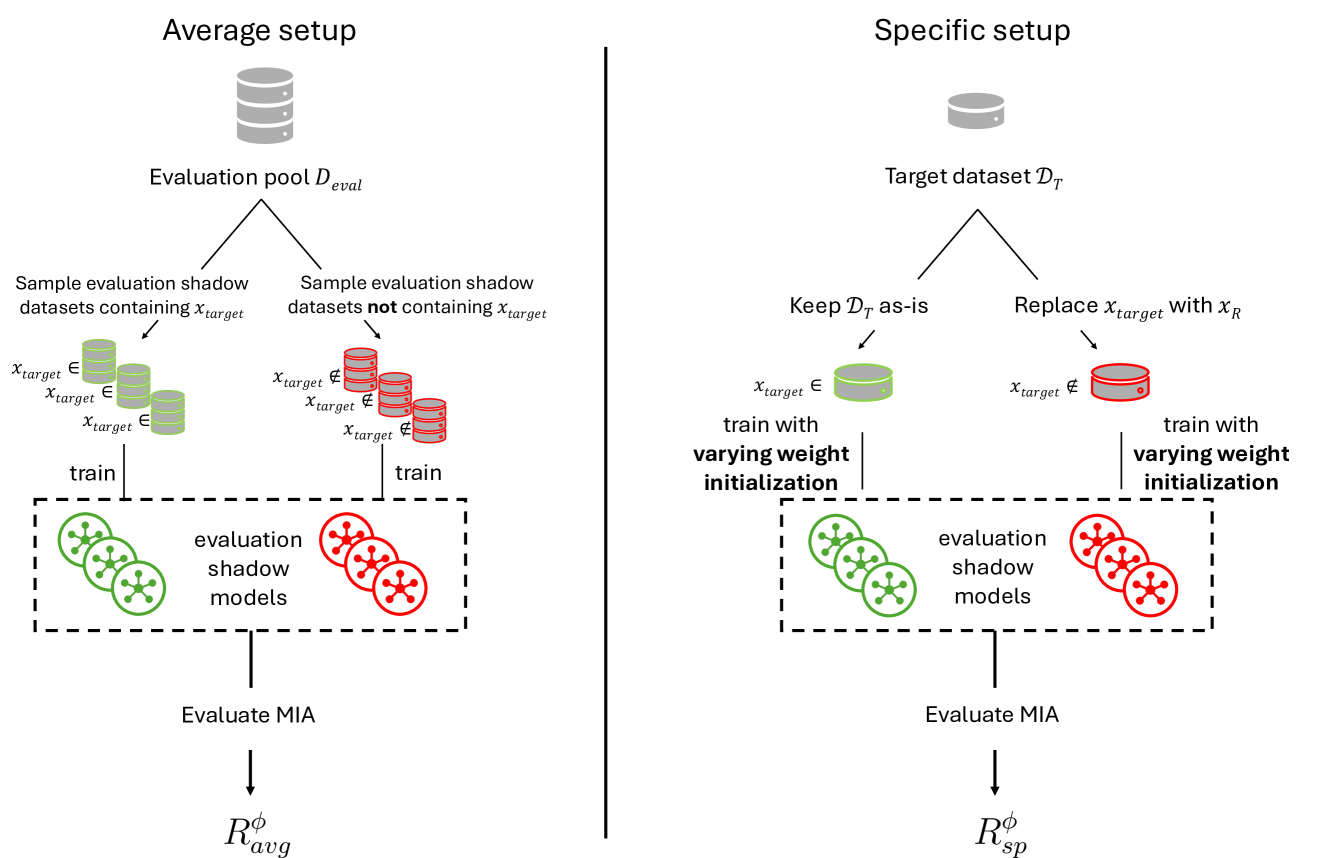
Membership Inference Attacks (MIAs) are widely used to evaluate the propensity of a machine learning (ML) model to memorize an individual record and the privacy risk releasing the model poses. MIAs are commonly evaluated similarly to ML models: the MIA is performed on a test set of models trained on datasets unseen during training, which are sampled from a larger pool, $D_{eval}$. The MIA is evaluated across all datasets in this test set, and is thus evaluated across the distribution of samples from $D_{eval}$. While this was a natural extension of ML evaluation to MIAs, recent work has shown that a record's risk heavily depends on its specific dataset. For example, outliers are particularly vulnerable, yet an outlier in one dataset may not be one in another. The sources of randomness currently used to evaluate MIAs may thus lead to inaccurate individual privacy risk estimates. We propose a new, specific evaluation setup for MIAs against ML models, using weight initialization as the sole source of randomness. This allows us to accurately evaluate the risk associated with the release of a model trained on a specific dataset. Using SOTA MIAs, we empirically show that the risk estimates given by the current setup lead to many records being misclassified as low risk. We derive theoretical results which, combined with empirical evidence, suggest that the risk calculated in the current setup is an average of the risks specific to each sampled dataset, validating our use of weight initialization as the only source of randomness. Finally, we consider an MIA with a stronger adversary leveraging information about the target dataset to infer membership. Taken together, our results show that current MIA evaluation is averaging the risk across datasets leading to inaccurate risk estimates, and the risk posed by attacks leveraging information about the target dataset to be potentially underestimated.
5/27/2024

Towards a Game-theoretic Understanding of Explanation-based Membership Inference Attacks
Kavita Kumari, Murtuza Jadliwala, Sumit Kumar Jha, Anindya Maiti
0
0
Model explanations improve the transparency of black-box machine learning (ML) models and their decisions; however, they can also be exploited to carry out privacy threats such as membership inference attacks (MIA). Existing works have only analyzed MIA in a single what if interaction scenario between an adversary and the target ML model; thus, it does not discern the factors impacting the capabilities of an adversary in launching MIA in repeated interaction settings. Additionally, these works rely on assumptions about the adversary's knowledge of the target model's structure and, thus, do not guarantee the optimality of the predefined threshold required to distinguish the members from non-members. In this paper, we delve into the domain of explanation-based threshold attacks, where the adversary endeavors to carry out MIA attacks by leveraging the variance of explanations through iterative interactions with the system comprising of the target ML model and its corresponding explanation method. We model such interactions by employing a continuous-time stochastic signaling game framework. In our framework, an adversary plays a stopping game, interacting with the system (having imperfect information about the type of an adversary, i.e., honest or malicious) to obtain explanation variance information and computing an optimal threshold to determine the membership of a datapoint accurately. First, we propose a sound mathematical formulation to prove that such an optimal threshold exists, which can be used to launch MIA. Then, we characterize the conditions under which a unique Markov perfect equilibrium (or steady state) exists in this dynamic system. By means of a comprehensive set of simulations of the proposed game model, we assess different factors that can impact the capability of an adversary to launch MIA in such repeated interaction settings.
4/11/2024
🤯
Low-Cost High-Power Membership Inference Attacks
Sajjad Zarifzadeh, Philippe Liu, Reza Shokri
0
0
Membership inference attacks aim to detect if a particular data point was used in training a model. We design a novel statistical test to perform robust membership inference attacks (RMIA) with low computational overhead. We achieve this by a fine-grained modeling of the null hypothesis in our likelihood ratio tests, and effectively leveraging both reference models and reference population data samples. RMIA has superior test power compared with prior methods, throughout the TPR-FPR curve (even at extremely low FPR, as low as 0). Under computational constraints, where only a limited number of pre-trained reference models (as few as 1) are available, and also when we vary other elements of the attack (e.g., data distribution), our method performs exceptionally well, unlike prior attacks that approach random guessing. RMIA lays the groundwork for practical yet accurate data privacy risk assessment in machine learning.
6/13/2024

On the Impact of Dataset Properties on Membership Privacy of Deep Learning
Marlon Tobaben, Joonas Jalko, Gauri Pradhan, Yuan He, Antti Honkela
0
0
We apply a state-of-the-art membership inference attack (MIA) to systematically test the practical privacy vulnerability of fine-tuning large image classification models. We focus on understanding the properties of data sets and samples that make them vulnerable to membership inference. In terms of data set properties, we find a strong power law dependence between the number of examples per class in the data and the MIA vulnerability, as measured by true positive rate of the attack at a low false positive rate. We train a linear model to predict true positive rate based on data set properties and observe good fit for MIA vulnerability on unseen data. To analyse the phenomenon theoretically, we reproduce the result on a simplified model of membership inference that behaves similarly to our experimental data. We prove that in this model, the logarithm of the difference of true and false positive rates depends linearly on the logarithm of the number of examples per class.For an individual sample, the gradient norm is predictive of its vulnerability.
6/13/2024