Towards Black-Box Membership Inference Attack for Diffusion Models
2405.20771
0
0
Abstract
Identifying whether an artwork was used to train a diffusion model is an important research topic, given the rising popularity of AI-generated art and the associated copyright concerns. The work approaches this problem from the membership inference attack (MIA) perspective. We first identify the limitations of applying existing MIA methods for copyright protection: the required access of internal U-nets and the choice of non-member datasets for evaluation. To address the above problems, we introduce a novel black-box membership inference attack method that operates without needing access to the model's internal U-net. We then construct a DALL-E generated dataset for a more comprehensive evaluation. We validate our method across various setups, and our experimental results outperform previous works.
Create account to get full access
Overview
- This paper presents a black-box membership inference attack against diffusion models, which are a type of generative AI model.
- Membership inference attacks aim to determine whether a given data sample was used to train a machine learning model.
- The proposed attack leverages the noise injection and diffusion processes inherent to diffusion models to infer membership.
- Experiments on multiple diffusion model architectures and datasets demonstrate the effectiveness of the attack.
Plain English Explanation
Towards Black-Box Membership Inference Attack for Diffusion Models explores a way to determine if a particular data sample was used to train a diffusion model. Diffusion models are a type of AI that can generate new images, text, and other data by starting with random noise and gradually transforming it.
The key insight is that the noise injection and diffusion processes used by these models leave "fingerprints" that can be detected. The researchers developed a technique to analyze these fingerprints and infer whether a given sample was part of the model's training data. This is known as a "membership inference attack."
Membership inference attacks are important because they can reveal private information about the data used to train AI models. The paper shows this attack works effectively against multiple diffusion model architectures and datasets, demonstrating the potential privacy risks of these increasingly popular generative AI systems.
Technical Explanation
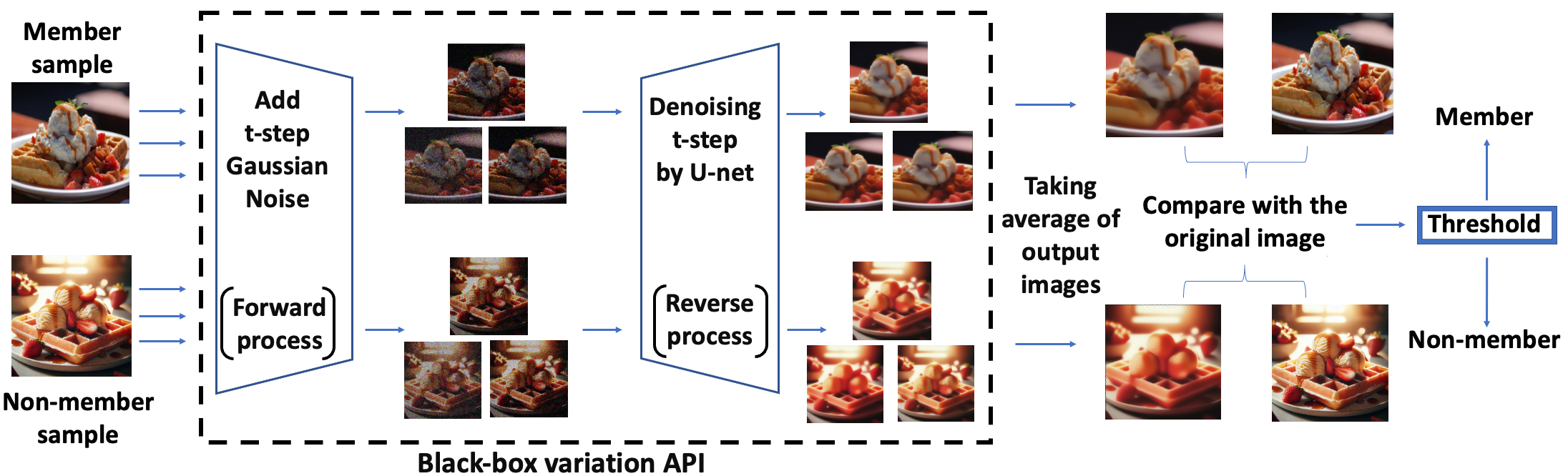
The paper proposes a black-box membership inference attack for diffusion models. The key idea is to leverage the noise injection and diffusion processes inherent to these models to infer whether a given data sample was part of the training set.
The attack works by training a separate "attack model" that can detect these subtle fingerprints left by the diffusion process. The attack model takes as input a data sample and the diffusion model's outputs at different stages of the generation process. It then predicts whether the sample was in the training set or not.
The researchers evaluated their attack on several diffusion model architectures, including Latent Diffusion and Stable Diffusion, across multiple datasets. Their results demonstrate the effectiveness of the attack, with high membership inference accuracy in many cases.
Critical Analysis
The paper provides a thorough technical explanation of the proposed black-box membership inference attack and its evaluation. However, there are a few potential limitations and areas for further research:
-
The attack assumes access to the diffusion model's outputs at different stages of the generation process. In a true black-box setting, this information may not be available, which could reduce the attack's effectiveness.
-
The experiments focus on image datasets, but the attack may not transfer as effectively to other modalities like text, where the diffusion process could behave differently.
-
The paper does not explore potential defense mechanisms against this type of membership inference attack. Learning-based difficulty calibration or other techniques could be investigated to mitigate these privacy risks.
-
The Pandora's White-Box paper presents a more powerful white-box attack that could be compared to the black-box approach in this paper.
Overall, this research contributes to our understanding of the privacy vulnerabilities of diffusion models and highlights the need for further investigation into membership inference attacks and potential defenses.
Conclusion
This paper presents a novel black-box membership inference attack against diffusion models, which are a type of increasingly popular generative AI system. The attack leverages the noise injection and diffusion processes inherent to these models to infer whether a given data sample was part of the training set.
The experimental results demonstrate the effectiveness of the attack across multiple diffusion model architectures and datasets, highlighting the potential privacy risks of these generative AI systems. The findings underscore the importance of further research into membership inference attacks and defense mechanisms to ensure the responsible development and deployment of diffusion models and other advanced AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GLiRA: Black-Box Membership Inference Attack via Knowledge Distillation
Andrey V. Galichin, Mikhail Pautov, Alexey Zhavoronkin, Oleg Y. Rogov, Ivan Oseledets
0
0
While Deep Neural Networks (DNNs) have demonstrated remarkable performance in tasks related to perception and control, there are still several unresolved concerns regarding the privacy of their training data, particularly in the context of vulnerability to Membership Inference Attacks (MIAs). In this paper, we explore a connection between the susceptibility to membership inference attacks and the vulnerability to distillation-based functionality stealing attacks. In particular, we propose {GLiRA}, a distillation-guided approach to membership inference attack on the black-box neural network. We observe that the knowledge distillation significantly improves the efficiency of likelihood ratio of membership inference attack, especially in the black-box setting, i.e., when the architecture of the target model is unknown to the attacker. We evaluate the proposed method across multiple image classification datasets and models and demonstrate that likelihood ratio attacks when guided by the knowledge distillation, outperform the current state-of-the-art membership inference attacks in the black-box setting.
5/14/2024
🤯
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Eric Aubinais, Elisabeth Gassiat, Pablo Piantanida
0
0
Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article provides theoretical guarantees by exploring the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. We then theoretically prove that in a non-linear regression setting with overfitting algorithms, attacks may have a high probability of success. Finally, we investigate several situations for which we provide bounds on this quantity of interest. Interestingly, our findings indicate that discretizing the data might enhance the algorithm's security. Specifically, it is demonstrated to be limited by a constant, which quantifies the diversity of the underlying data distribution. We illustrate those results through two simple simulations.
6/12/2024

LLM Dataset Inference: Did you train on my dataset?
Pratyush Maini, Hengrui Jia, Nicolas Papernot, Adam Dziedzic
0
0
The proliferation of large language models (LLMs) in the real world has come with a rise in copyright cases against companies for training their models on unlicensed data from the internet. Recent works have presented methods to identify if individual text sequences were members of the model's training data, known as membership inference attacks (MIAs). We demonstrate that the apparent success of these MIAs is confounded by selecting non-members (text sequences not used for training) belonging to a different distribution from the members (e.g., temporally shifted recent Wikipedia articles compared with ones used to train the model). This distribution shift makes membership inference appear successful. However, most MIA methods perform no better than random guessing when discriminating between members and non-members from the same distribution (e.g., in this case, the same period of time). Even when MIAs work, we find that different MIAs succeed at inferring membership of samples from different distributions. Instead, we propose a new dataset inference method to accurately identify the datasets used to train large language models. This paradigm sits realistically in the modern-day copyright landscape, where authors claim that an LLM is trained over multiple documents (such as a book) written by them, rather than one particular paragraph. While dataset inference shares many of the challenges of membership inference, we solve it by selectively combining the MIAs that provide positive signal for a given distribution, and aggregating them to perform a statistical test on a given dataset. Our approach successfully distinguishes the train and test sets of different subsets of the Pile with statistically significant p-values < 0.1, without any false positives.
6/11/2024

New!Unveiling the Unseen: Exploring Whitebox Membership Inference through the Lens of Explainability
Chenxi Li, Abhinav Kumar, Zhen Guo, Jie Hou, Reza Tourani
0
0
The increasing prominence of deep learning applications and reliance on personalized data underscore the urgent need to address privacy vulnerabilities, particularly Membership Inference Attacks (MIAs). Despite numerous MIA studies, significant knowledge gaps persist, particularly regarding the impact of hidden features (in isolation) on attack efficacy and insufficient justification for the root causes of attacks based on raw data features. In this paper, we aim to address these knowledge gaps by first exploring statistical approaches to identify the most informative neurons and quantifying the significance of the hidden activations from the selected neurons on attack accuracy, in isolation and combination. Additionally, we propose an attack-driven explainable framework by integrating the target and attack models to identify the most influential features of raw data that lead to successful membership inference attacks. Our proposed MIA shows an improvement of up to 26% on state-of-the-art MIA.
7/2/2024