Towards a Game-theoretic Understanding of Explanation-based Membership Inference Attacks
2404.07139
0
0

Abstract
Model explanations improve the transparency of black-box machine learning (ML) models and their decisions; however, they can also be exploited to carry out privacy threats such as membership inference attacks (MIA). Existing works have only analyzed MIA in a single what if interaction scenario between an adversary and the target ML model; thus, it does not discern the factors impacting the capabilities of an adversary in launching MIA in repeated interaction settings. Additionally, these works rely on assumptions about the adversary's knowledge of the target model's structure and, thus, do not guarantee the optimality of the predefined threshold required to distinguish the members from non-members. In this paper, we delve into the domain of explanation-based threshold attacks, where the adversary endeavors to carry out MIA attacks by leveraging the variance of explanations through iterative interactions with the system comprising of the target ML model and its corresponding explanation method. We model such interactions by employing a continuous-time stochastic signaling game framework. In our framework, an adversary plays a stopping game, interacting with the system (having imperfect information about the type of an adversary, i.e., honest or malicious) to obtain explanation variance information and computing an optimal threshold to determine the membership of a datapoint accurately. First, we propose a sound mathematical formulation to prove that such an optimal threshold exists, which can be used to launch MIA. Then, we characterize the conditions under which a unique Markov perfect equilibrium (or steady state) exists in this dynamic system. By means of a comprehensive set of simulations of the proposed game model, we assess different factors that can impact the capability of an adversary to launch MIA in such repeated interaction settings.
Create account to get full access
Overview
- The paper explores a game-theoretic approach to understanding explanation-based membership inference attacks, which aim to determine if a data point was used to train a machine learning model.
- It analyzes the dynamics between a model owner who wants to protect their model's privacy and a membership inference attacker who aims to breach that privacy.
- The paper proposes a game-theoretic framework to model this adversarial scenario and derives optimal strategies for both the model owner and the attacker.
Plain English Explanation
Machine learning models can be trained on sensitive data, and there is a risk that an attacker could try to determine if a specific data point was used to train the model. This is known as a membership inference attack.
To defend against these attacks, model owners may provide explanations about their model's predictions, hoping to obscure the training data. However, these explanation-based defenses can themselves be vulnerable to attack.
This paper takes a game-theoretic approach to understand the dynamics between the model owner, who wants to protect their model's privacy, and the attacker, who aims to breach that privacy. It models this as an adversarial game and derives optimal strategies for both parties.
The key insight is that the model owner and attacker have conflicting goals - the owner wants to provide useful explanations to users while minimizing the risk of membership inference, while the attacker wants to leverage those explanations to infer membership. By framing this as a strategic game, the paper provides a framework for understanding how these two sides can interact and make optimal decisions.
Technical Explanation
The paper first establishes a game-theoretic framework to model the interaction between the model owner and the membership inference attacker. The model owner chooses an explanation mechanism to provide to users, while the attacker observes these explanations and attempts to infer whether a given data point was used to train the model.
The authors then analyze the Nash equilibrium of this game, deriving the optimal strategies for both the model owner and the attacker. They show that the model owner's optimal strategy involves providing "noisy" explanations that balance utility for users with privacy protection. The attacker's optimal strategy is to leverage these explanations to infer membership as accurately as possible.
The paper also explores how factors like the model's accuracy, the attacker's prior knowledge, and the cost of explanations can influence the equilibrium strategies. Through numerical experiments, the authors demonstrate how this game-theoretic analysis can provide insights into the fundamental tradeoffs involved in explanation-based defenses against membership inference attacks.
Critical Analysis
The paper presents a thoughtful game-theoretic framework for analyzing the interplay between model owners and membership inference attackers. By modeling this as an adversarial scenario, the authors are able to derive useful insights about the optimal strategies for both sides.
However, the paper does acknowledge some limitations. For example, the model assumes the attacker has full knowledge of the model owner's explanation mechanism, which may not always be the case in practice. Additionally, the framework does not consider the possibility of adversarial attacks that could undermine the explanations themselves.
Further research could explore more realistic scenarios, such as incomplete information, multiple attackers, or the use of tensor networks for explainable AI. Additionally, it would be valuable to consider the broader societal implications of this type of attack, and how to ensure that explanation-based defenses do not inadvertently create new vulnerabilities.
Conclusion
This paper presents a novel game-theoretic approach to understanding the dynamics between model owners and membership inference attackers in the context of explanation-based defenses. By framing this as an adversarial scenario, the authors are able to derive optimal strategies for both parties and provide insights into the fundamental tradeoffs involved.
While the framework has some limitations, it represents an important step towards a more comprehensive understanding of the complex interplay between machine learning privacy, security, and explainability. As AI systems become more pervasive, research like this will be crucial for developing robust and trustworthy models that can withstand a range of attacks and privacy breaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Unveiling the Unseen: Exploring Whitebox Membership Inference through the Lens of Explainability
Chenxi Li, Abhinav Kumar, Zhen Guo, Jie Hou, Reza Tourani
0
0
The increasing prominence of deep learning applications and reliance on personalized data underscore the urgent need to address privacy vulnerabilities, particularly Membership Inference Attacks (MIAs). Despite numerous MIA studies, significant knowledge gaps persist, particularly regarding the impact of hidden features (in isolation) on attack efficacy and insufficient justification for the root causes of attacks based on raw data features. In this paper, we aim to address these knowledge gaps by first exploring statistical approaches to identify the most informative neurons and quantifying the significance of the hidden activations from the selected neurons on attack accuracy, in isolation and combination. Additionally, we propose an attack-driven explainable framework by integrating the target and attack models to identify the most influential features of raw data that lead to successful membership inference attacks. Our proposed MIA shows an improvement of up to 26% on state-of-the-art MIA.
7/2/2024
🤯
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Eric Aubinais, Elisabeth Gassiat, Pablo Piantanida
0
0
Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article provides theoretical guarantees by exploring the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. We then theoretically prove that in a non-linear regression setting with overfitting algorithms, attacks may have a high probability of success. Finally, we investigate several situations for which we provide bounds on this quantity of interest. Interestingly, our findings indicate that discretizing the data might enhance the algorithm's security. Specifically, it is demonstrated to be limited by a constant, which quantifies the diversity of the underlying data distribution. We illustrate those results through two simple simulations.
6/12/2024
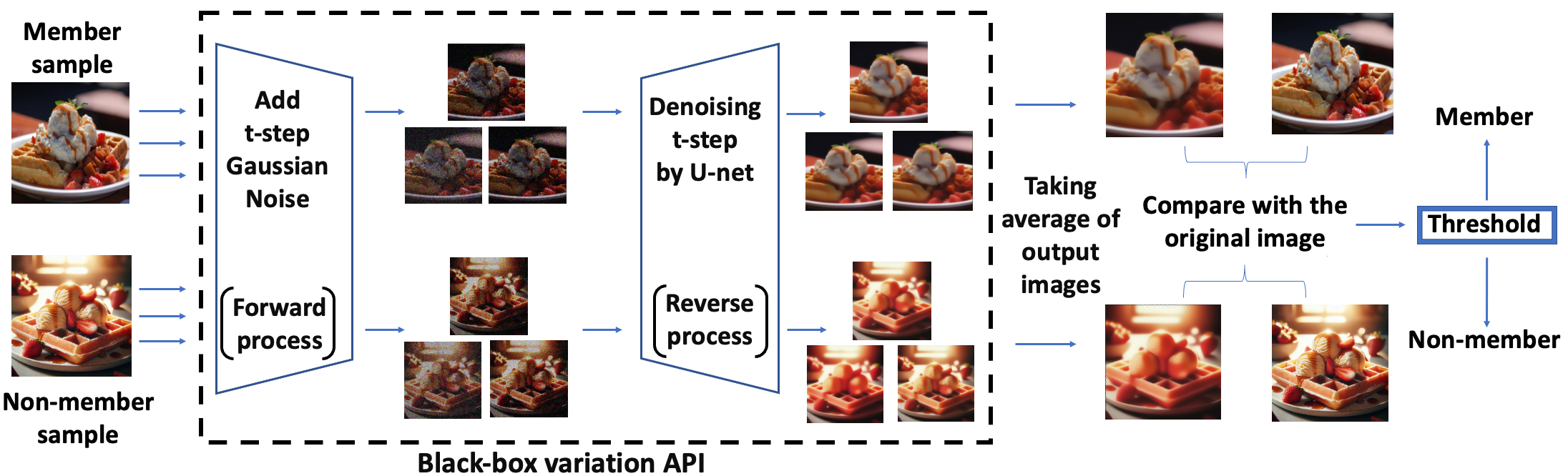
Towards Black-Box Membership Inference Attack for Diffusion Models
Jingwei Li, Jing Dong, Tianxing He, Jingzhao Zhang
0
0
Identifying whether an artwork was used to train a diffusion model is an important research topic, given the rising popularity of AI-generated art and the associated copyright concerns. The work approaches this problem from the membership inference attack (MIA) perspective. We first identify the limitations of applying existing MIA methods for copyright protection: the required access of internal U-nets and the choice of non-member datasets for evaluation. To address the above problems, we introduce a novel black-box membership inference attack method that operates without needing access to the model's internal U-net. We then construct a DALL-E generated dataset for a more comprehensive evaluation. We validate our method across various setups, and our experimental results outperform previous works.
6/3/2024
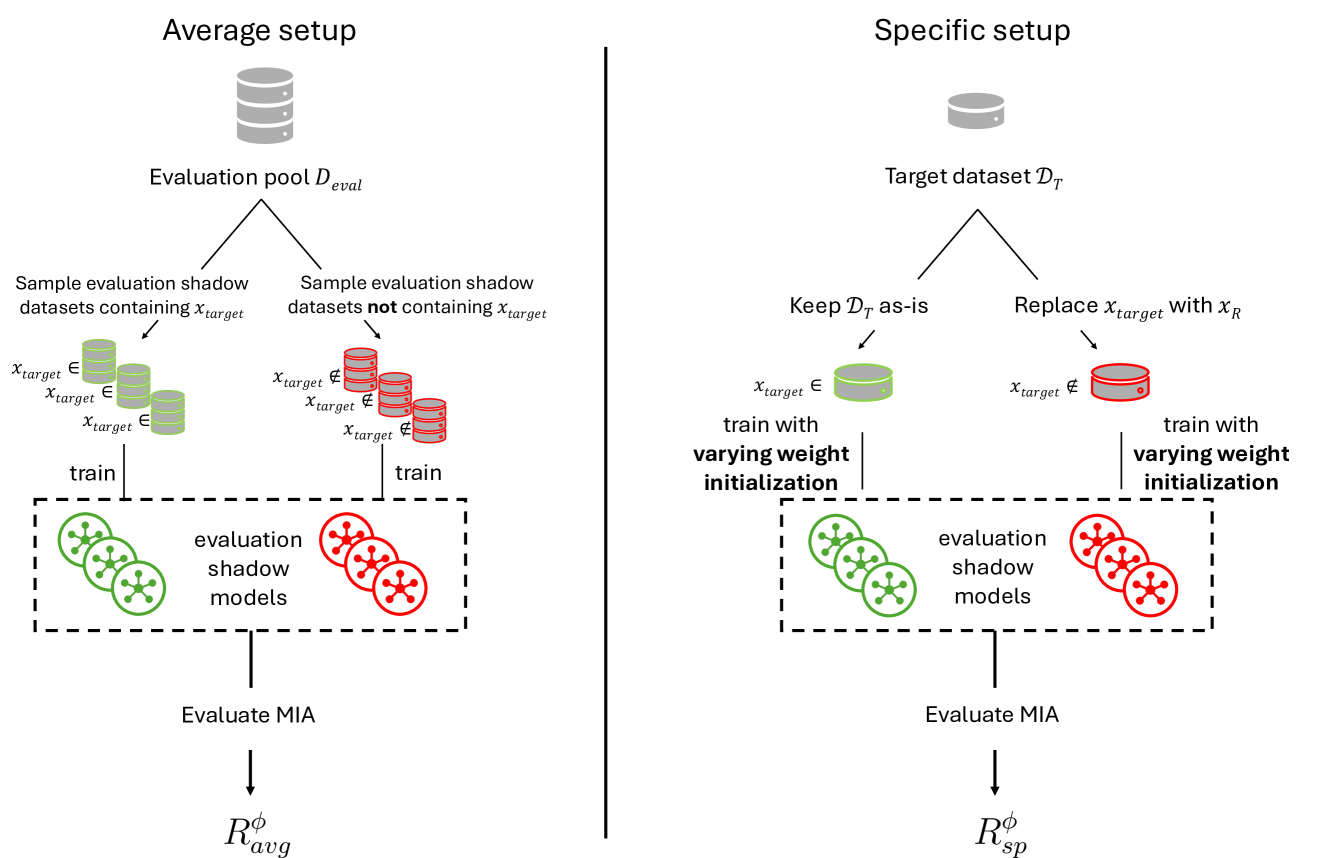
Lost in the Averages: A New Specific Setup to Evaluate Membership Inference Attacks Against Machine Learning Models
Florent Gu'epin (Department of Computing, Imperial College London, United Kingdom), Natav{s}a Krv{c}o (Department of Computing, Imperial College London, United Kingdom), Matthieu Meeus (Department of Computing, Imperial College London, United Kingdom), Yves-Alexandre de Montjoye (Department of Computing, Imperial College London, United Kingdom)
0
0
Membership Inference Attacks (MIAs) are widely used to evaluate the propensity of a machine learning (ML) model to memorize an individual record and the privacy risk releasing the model poses. MIAs are commonly evaluated similarly to ML models: the MIA is performed on a test set of models trained on datasets unseen during training, which are sampled from a larger pool, $D_{eval}$. The MIA is evaluated across all datasets in this test set, and is thus evaluated across the distribution of samples from $D_{eval}$. While this was a natural extension of ML evaluation to MIAs, recent work has shown that a record's risk heavily depends on its specific dataset. For example, outliers are particularly vulnerable, yet an outlier in one dataset may not be one in another. The sources of randomness currently used to evaluate MIAs may thus lead to inaccurate individual privacy risk estimates. We propose a new, specific evaluation setup for MIAs against ML models, using weight initialization as the sole source of randomness. This allows us to accurately evaluate the risk associated with the release of a model trained on a specific dataset. Using SOTA MIAs, we empirically show that the risk estimates given by the current setup lead to many records being misclassified as low risk. We derive theoretical results which, combined with empirical evidence, suggest that the risk calculated in the current setup is an average of the risks specific to each sampled dataset, validating our use of weight initialization as the only source of randomness. Finally, we consider an MIA with a stronger adversary leveraging information about the target dataset to infer membership. Taken together, our results show that current MIA evaluation is averaging the risk across datasets leading to inaccurate risk estimates, and the risk posed by attacks leveraging information about the target dataset to be potentially underestimated.
5/27/2024