Fusion and Cross-Modal Transfer for Zero-Shot Human Action Recognition

0

Sign in to get full access
Overview
- This paper explores fusion and cross-modal transfer for zero-shot human action recognition.
- It proposes a method to learn a shared feature space across different modalities like RGB and skeleton data.
- The key idea is to leverage relationships between modalities to recognize actions without labeled data for a specific modality.
Plain English Explanation
The paper is about recognizing human actions, like walking or jumping, even when you don't have labeled examples of those actions for a particular type of sensor data, like video or motion sensors.
The researchers developed a way to learn a shared feature space across different types of sensor data. This allows them to fuse information from multiple sensors, like cameras and motion sensors, to recognize actions even when they only have labeled examples for one sensor type.
The key idea is to learn the relationships between the different sensor modalities, so you can use that knowledge to recognize actions in the modality without labeled data. This "cross-modal transfer" allows them to achieve good action recognition performance even in this zero-shot setting where you don't have labeled examples for all the sensor types.
Technical Explanation
The paper proposes a fusion and cross-modal transfer approach for zero-shot human action recognition. The key technical contributions are:
-
Modality-Aware Fusion: The model learns a shared feature space across RGB and skeleton modalities. This allows it to fuse information from both modalities, even when labels are only available for one.
-
Cross-Modal Transfer: The model leverages relationships between modalities to recognize actions in a target modality (e.g. skeleton) using knowledge transferred from a source modality (e.g. RGB) where labeled data is available.
-
Architecture: The model uses a modality-aware fusion module and a cross-modal transfer module. The fusion module learns the shared feature space, while the transfer module uses adversarial training to align the feature distributions across modalities.
-
Experiments: The approach is evaluated on several benchmark datasets for zero-shot action recognition, demonstrating strong performance compared to prior methods.
Critical Analysis
The paper makes a compelling case for the benefits of fusion and cross-modal transfer for zero-shot action recognition. The proposed approach seems technically sound and the experimental results are promising.
However, the paper does not fully address the potential limitations of this approach. For example, it's unclear how well the method would scale to larger numbers of action classes or sensor modalities. Additionally, the reliance on adversarial training may make the model less stable and harder to train in practice.
Further research could explore alternative cross-modal alignment techniques, investigate the model's robustness to noisy or missing sensor data, and examine the transferability of the learned representations to new domains or tasks.
Conclusion
This paper presents an innovative approach to zero-shot human action recognition that leverages fusion and cross-modal transfer. By learning a shared feature space and exploiting relationships between modalities, the model can effectively recognize actions even when labeled data is only available for a subset of the sensor types.
The technical contributions and promising experimental results suggest this line of research has the potential to significantly advance the state of the art in human action recognition, with applications in areas like robotics, video analysis, and healthcare monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fusion and Cross-Modal Transfer for Zero-Shot Human Action Recognition
Abhi Kamboj, Anh Duy Nguyen, Minh Do
Despite living in a multi-sensory world, most AI models are limited to textual and visual interpretations of human motion and behavior. Inertial measurement units (IMUs) provide a salient signal to understand human motion; however, they are challenging to use due to their uninterpretability and scarcity of their data. We investigate a method to transfer knowledge between visual and inertial modalities using the structure of an informative joint representation space designed for human action recognition (HAR). We apply the resulting Fusion and Cross-modal Transfer (FACT) method to a novel setup, where the model does not have access to labeled IMU data during training and is able to perform HAR with only IMU data during testing. Extensive experiments on a wide range of RGB-IMU datasets demonstrate that FACT significantly outperforms existing methods in zero-shot cross-modal transfer.
Read more7/25/2024

0
Enhancing Inertial Hand based HAR through Joint Representation of Language, Pose and Synthetic IMUs
Vitor Fortes Rey, Lala Shakti Swarup Ray, Xia Qingxin, Kaishun Wu, Paul Lukowicz
Due to the scarcity of labeled sensor data in HAR, prior research has turned to video data to synthesize Inertial Measurement Units (IMU) data, capitalizing on its rich activity annotations. However, generating IMU data from videos presents challenges for HAR in real-world settings, attributed to the poor quality of synthetic IMU data and its limited efficacy in subtle, fine-grained motions. In this paper, we propose Multi$^3$Net, our novel multi-modal, multitask, and contrastive-based framework approach to address the issue of limited data. Our pretraining procedure uses videos from online repositories, aiming to learn joint representations of text, pose, and IMU simultaneously. By employing video data and contrastive learning, our method seeks to enhance wearable HAR performance, especially in recognizing subtle activities.Our experimental findings validate the effectiveness of our approach in improving HAR performance with IMU data. We demonstrate that models trained with synthetic IMU data generated from videos using our method surpass existing approaches in recognizing fine-grained activities.
Read more7/30/2024
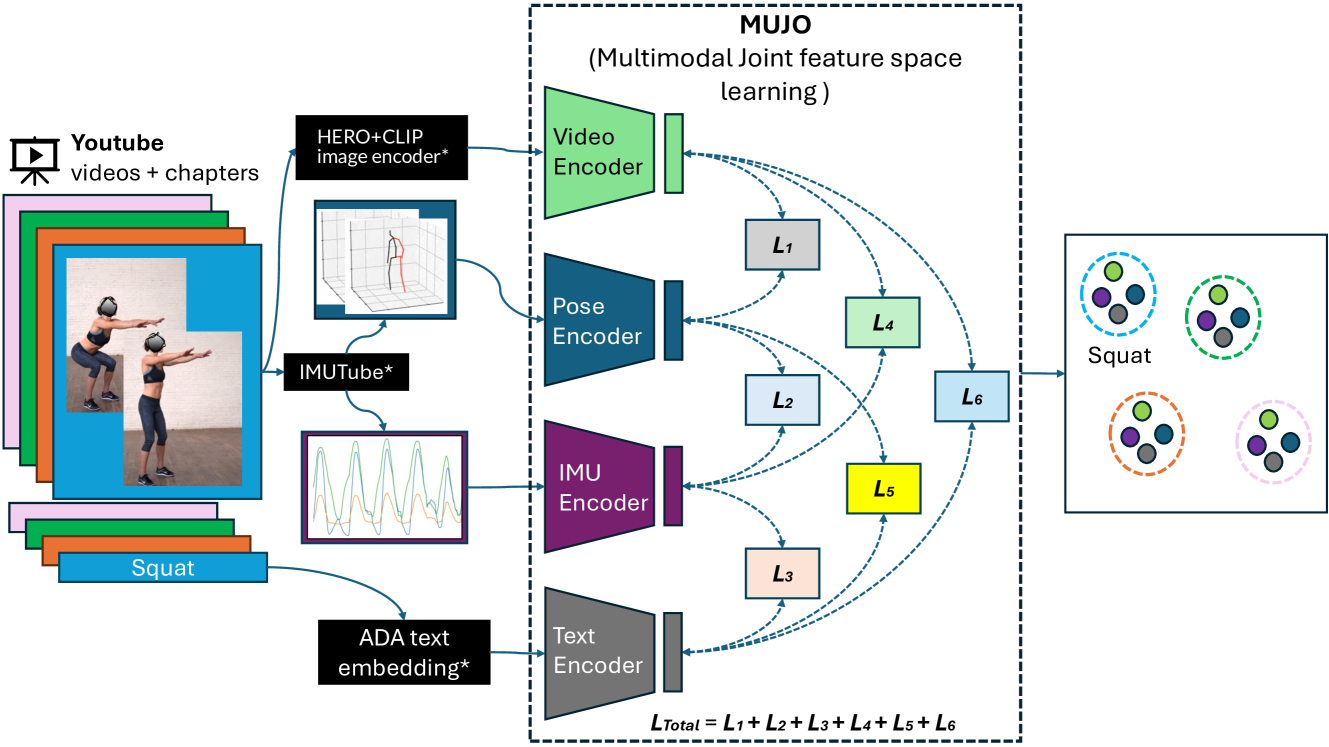
0
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Stefan Gerd Fritsch, Cennet Oguz, Vitor Fortes Rey, Lala Ray, Maximilian Kiefer-Emmanouilidis, Paul Lukowicz
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
Read more6/7/2024

0
FLOW: Fusing and Shuffling Global and Local Views for Cross-User Human Activity Recognition with IMUs
Qi Qiu, Tao Zhu, Furong Duan, Kevin I-Kai Wang, Liming Chen, Mingxing Nie, Mingxing Nie
Inertial Measurement Unit (IMU) sensors are widely employed for Human Activity Recognition (HAR) due to their portability, energy efficiency, and growing research interest. However, a significant challenge for IMU-HAR models is achieving robust generalization performance across diverse users. This limitation stems from substantial variations in data distribution among individual users. One primary reason for this distribution disparity lies in the representation of IMU sensor data in the local coordinate system, which is susceptible to subtle user variations during IMU wearing. To address this issue, we propose a novel approach that extracts a global view representation based on the characteristics of IMU data, effectively alleviating the data distribution discrepancies induced by wearing styles. To validate the efficacy of the global view representation, we fed both global and local view data into model for experiments. The results demonstrate that global view data significantly outperforms local view data in cross-user experiments. Furthermore, we propose a Multi-view Supervised Network (MVFNet) based on Shuffling to effectively fuse local view and global view data. It supervises the feature extraction of each view through view division and view shuffling, so as to avoid the model ignoring important features as much as possible. Extensive experiments conducted on OPPORTUNITY and PAMAP2 datasets demonstrate that the proposed algorithm outperforms the current state-of-the-art methods in cross-user HAR.
Read more6/28/2024