Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
2404.16192
0
0
👀
Abstract
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a medical vision-language model that integrates large vision and language models adapted for the medical domain.
- This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets.
- The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset and demonstrates strong performance on another MedVQA dataset, VQA-RAD.
Plain English Explanation
Vision-language models are AI systems that can understand and process both images and text. They have been effective in general domains, like answering questions about images. However, these models struggle to maintain the same level of effectiveness when applied to more specialized domains, such as the medical field.
To address this challenge, the researchers developed a medical vision-language model. This model is built by taking large pre-existing vision and language models and adapting them specifically for the medical domain. The model goes through a three-stage training process using different medical-related datasets, including biomedical information and radiology images.
The researchers tested this medical vision-language model on two medical visual question-answering (MedVQA) datasets. The first is the SLAKE 1.0 dataset, and the second is the VQA-RAD dataset. The model achieved state-of-the-art performance on the SLAKE 1.0 dataset, correctly answering 87.5% of the questions. It also demonstrated strong performance on the VQA-RAD dataset, correctly answering 73.2% of the questions.
Technical Explanation
The researchers propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets.
In the first stage, the model is trained on a biomedical dataset to learn medical-specific language and visual understanding. In the second stage, the model is trained on a radiology dataset to learn how to interpret medical images. Finally, in the third stage, the model is fine-tuned on a medical visual question-answering (MedVQA) dataset to specialize in answering questions about medical images and text.
The researchers tested the proposed model on two MedVQA datasets: SLAKE 1.0 and VQA-RAD. On the SLAKE 1.0 dataset, the model achieved an overall accuracy of 87.5%, setting a new state-of-the-art performance. On the VQA-RAD dataset, the model achieved an overall accuracy of 73.2%, demonstrating strong performance on this task as well.
Critical Analysis
The researchers acknowledge that while their medical vision-language model performs well on the evaluated MedVQA datasets, it may not generalize to all medical domains or tasks. The model is trained on specific datasets and may not be able to handle the full breadth of medical information and imagery.
Additionally, the researchers note that the model's performance could be further improved by incorporating more diverse medical datasets or using more advanced training techniques, such as latent prompt-based assistance or explainable medical VQA.
It's also important to consider the potential biases and limitations of the datasets used to train the model, as they may not fully represent the diversity of medical information and imagery. Further research is needed to expand the evaluation benchmarks and ensure the model's robustness in real-world medical settings.
Conclusion
The proposed medical vision-language model demonstrates the potential for adapting general-purpose vision-language models to specialized domains, such as healthcare. By going through a structured training process using diverse medical datasets, the model is able to achieve state-of-the-art performance on medical visual question-answering tasks.
This research highlights the importance of developing domain-specific AI models to tackle complex challenges in specialized fields. The success of this medical vision-language model suggests that similar approaches could be applied to other specialized domains, potentially unlocking new applications and improving the real-world impact of AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
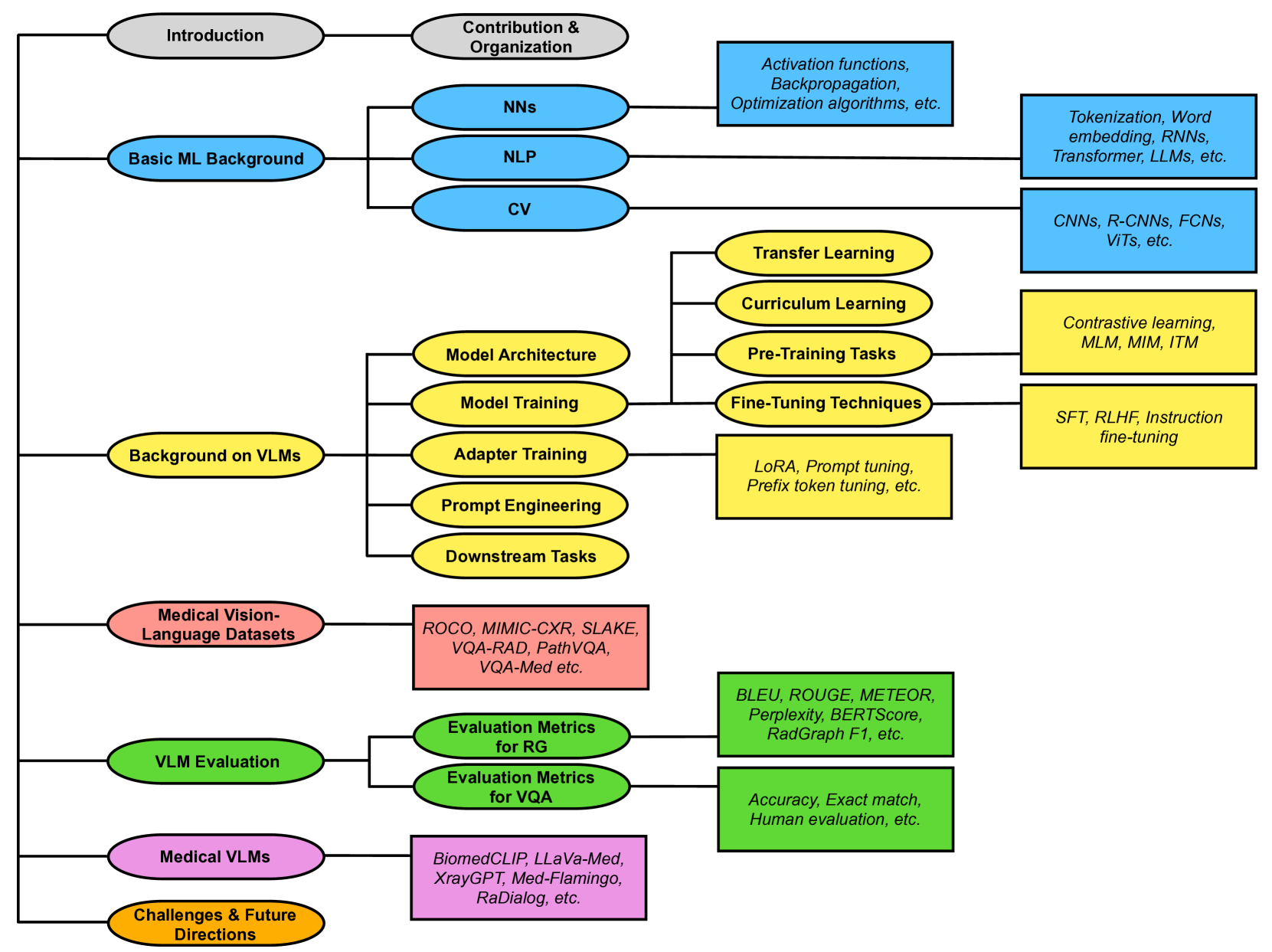
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
0
0
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
4/16/2024
💬
MedThink: Explaining Medical Visual Question Answering via Multimodal Decision-Making Rationale
Xiaotang Gai, Chenyi Zhou, Jiaxiang Liu, Yang Feng, Jian Wu, Zuozhu Liu
0
0
Medical Visual Question Answering (MedVQA), which offers language responses to image-based medical inquiries, represents a challenging task and significant advancement in healthcare. It assists medical experts to swiftly interpret medical images, thereby enabling faster and more accurate diagnoses. However, the model interpretability and transparency of existing MedVQA solutions are often limited, posing challenges in understanding their decision-making processes. To address this issue, we devise a semi-automated annotation process to streamlining data preparation and build new benchmark MedVQA datasets R-RAD and R-SLAKE. The R-RAD and R-SLAKE datasets provide intermediate medical decision-making rationales generated by multimodal large language models and human annotations for question-answering pairs in existing MedVQA datasets, i.e., VQA-RAD and SLAKE. Moreover, we design a novel framework which finetunes lightweight pretrained generative models by incorporating medical decision-making rationales into the training process. The framework includes three distinct strategies to generate decision outcomes and corresponding rationales, thereby clearly showcasing the medical decision-making process during reasoning. Extensive experiments demonstrate that our method can achieve an accuracy of 83.5% on R-RAD and 86.3% on R-SLAKE, significantly outperforming existing state-of-the-art baselines. Dataset and code will be released.
4/19/2024
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Tongkun Su, Jun Li, Xi Zhang, Haibo Jin, Hao Chen, Qiong Wang, Faqin Lv, Baoliang Zhao, Yin Hu
0
0
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
4/9/2024
👁️
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, Ping Luo
0
0
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 73 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our code with dataset are available at https://github.com/OpenGVLab/Multi-Modality-Arena.
4/23/2024