Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
2403.02469
0
0
Abstract
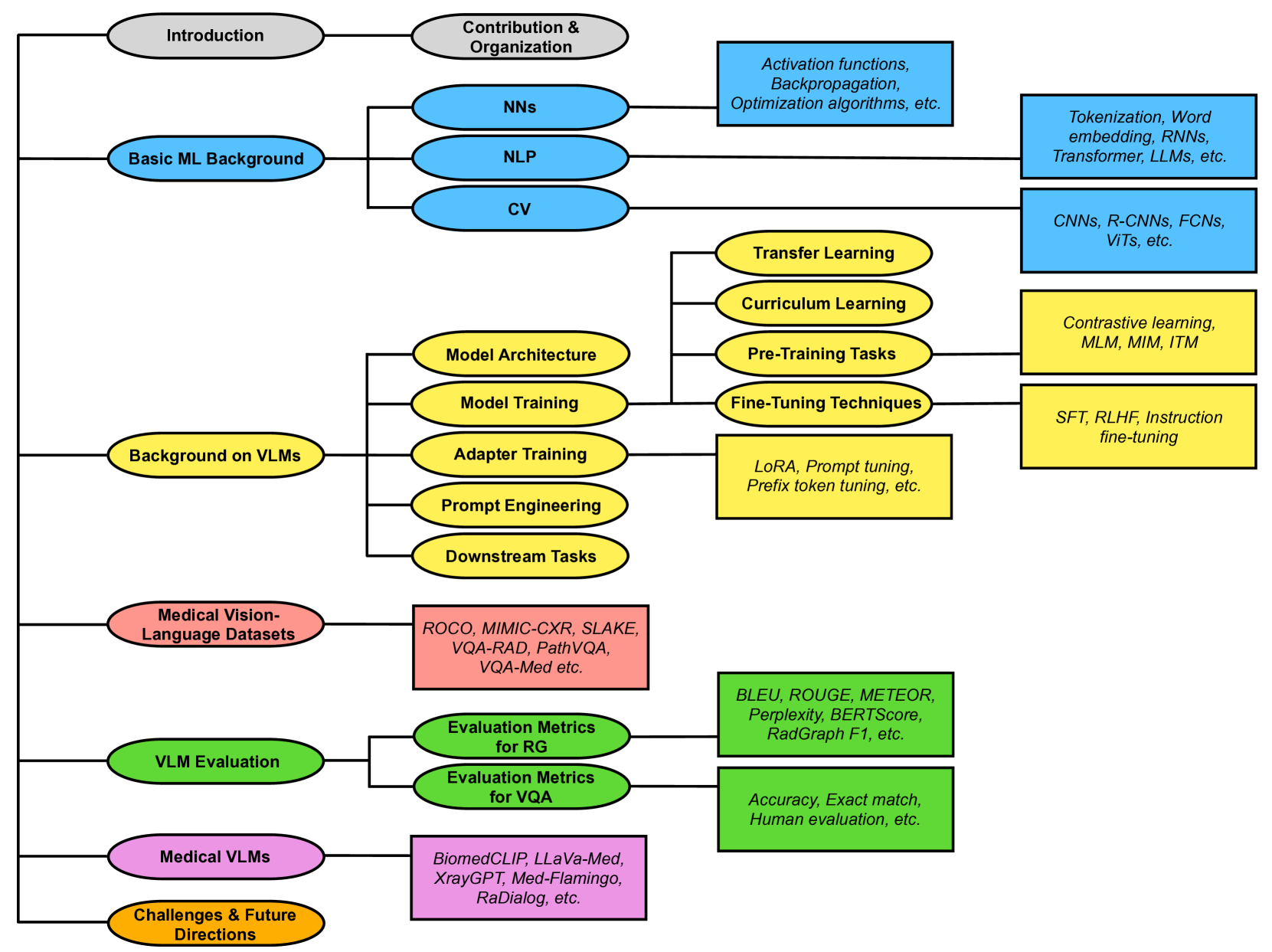
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive review of vision-language models for medical report generation and visual question answering (VQA) tasks.
- It covers the recent advancements in these models, including their architectures, training approaches, and applications in the medical domain.
- The review also discusses the challenges and limitations of current vision-language models in the medical context, and identifies potential areas for future research.
Plain English Explanation
Vision-language models are a type of artificial intelligence (AI) system that can understand and process both visual and textual information. These models have shown impressive capabilities in tasks like generating medical reports and answering questions about medical images.
In this paper, the researchers review the latest developments in vision-language models for the medical field. They explain how these models are designed, how they are trained to learn from both images and text, and how they are being used to assist healthcare professionals. For example, a vision-language model could be used to automatically generate a detailed report describing the findings in a medical image, or to answer specific questions about the content of an image.
The review also discusses the challenges and limitations of current vision-language models, such as their tendency to generate biased or inaccurate information in the medical context. The researchers identify areas where further research and development are needed to improve the reliability and performance of these models for medical applications.
Technical Explanation
The paper begins by providing an overview of the recent advancements in vision-language models, which combine computer vision and natural language processing techniques to understand and generate text based on visual inputs. The authors then focus on the application of these models in the medical domain, specifically for tasks like medical report generation and visual question answering (VQA).
The review covers the key architectural components and training approaches used in state-of-the-art vision-language models for medical applications. This includes the use of transformer-based models, such as BERT and ViT, as well as the integration of domain-specific knowledge and pre-training techniques to improve the models' performance on medical tasks.
The paper also discusses the various datasets and benchmarks used to evaluate the performance of these vision-language models in the medical context, such as the Hallucination Benchmark for Medical VQA and the Concept-based Analysis of Neural Networks framework. The authors highlight the challenges and limitations of current approaches, such as the tendency of these models to generate biased or hallucinated responses in medical settings.
Critical Analysis
The paper provides a comprehensive and up-to-date review of the state of the art in vision-language models for medical applications. The authors have done a thorough job of covering the key architectural and training advancements, as well as the various datasets and benchmarks used to evaluate these models.
One potential limitation of the review is that it does not delve deeply into the specific clinical applications and use cases of these vision-language models in the medical field. While the paper touches on tasks like medical report generation and visual question answering, it could have provided more detailed examples and case studies to illustrate the real-world impact and potential of these technologies.
Additionally, the review could have explored the ethical and privacy considerations associated with the use of vision-language models in healthcare, such as the need for robust data privacy and bias mitigation strategies. These are important factors to consider as these models become more widely adopted in the medical domain.
Conclusion
This paper provides a comprehensive review of the recent advancements in vision-language models for medical report generation and visual question answering tasks. The authors have done a thorough job of covering the key architectural and training approaches, as well as the challenges and limitations of current models in the medical context.
The review highlights the significant potential of these technologies to assist healthcare professionals and improve patient outcomes, but also underscores the need for further research and development to address the reliability and bias issues that currently exist. As vision-language models continue to evolve, it will be crucial for researchers and practitioners to work closely with medical experts to ensure these technologies are developed and deployed responsibly and ethically in the healthcare domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Cuong Nhat Ha, Shima Asaadi, Sanjeev Kumar Karn, Oladimeji Farri, Tobias Heimann, Thomas Runkler
0
0
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
4/26/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
👁️
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, Ping Luo
0
0
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 73 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our code with dataset are available at https://github.com/OpenGVLab/Multi-Modality-Arena.
4/23/2024
Medical Vision-Language Pre-Training for Brain Abnormalities
Masoud Monajatipoor, Zi-Yi Dou, Aichi Chien, Nanyun Peng, Kai-Wei Chang
0
0
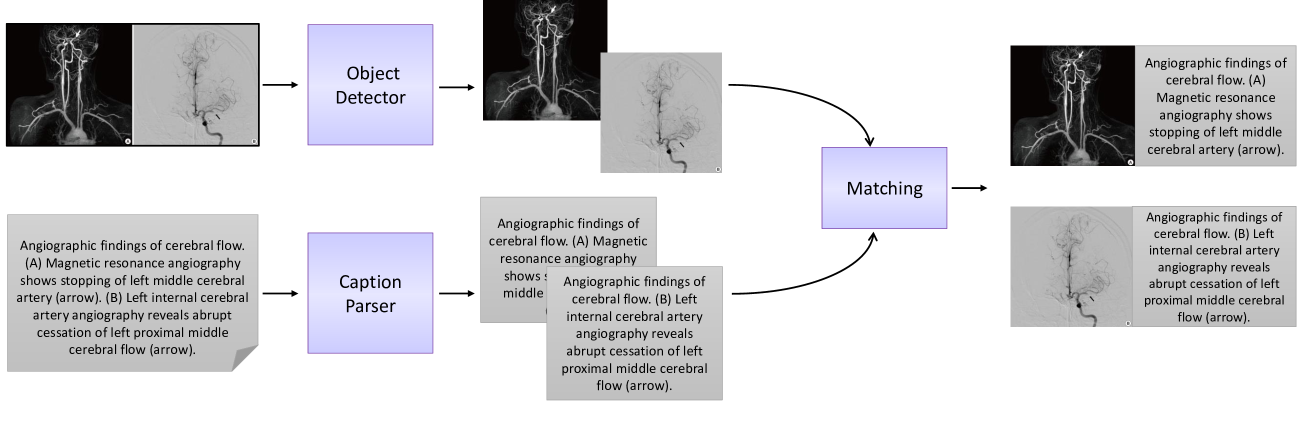
Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
4/30/2024