LaPA: Latent Prompt Assist Model For Medical Visual Question Answering

0

Sign in to get full access
Overview
- This paper introduces LaPA, a Latent Prompt Assist Model for improving medical visual question answering (VQA) performance.
- The key idea is to leverage a latent prompt representation to better guide the model's reasoning and answer generation process.
- The model is evaluated on several medical VQA datasets, demonstrating improved performance compared to existing approaches.
Plain English Explanation
Medical visual question answering (VQA) is the task of answering questions about medical images, such as X-rays or CT scans. This can be a challenging problem, as it requires understanding both the visual information in the image and the context of the medical domain.
The LaPA: Latent Prompt Assist Model For Medical Visual Question Answering paper proposes a new model called LaPA that aims to improve medical VQA performance. The key innovation of LaPA is the use of a "latent prompt" - a learned representation that helps the model better understand the question and how to answer it based on the image.
Imagine you're trying to answer a question about a medical image, like "What is the size of the tumor in this X-ray?" The latent prompt acts as a guide, helping the model focus on the relevant parts of the image and connect the visual information to the specific question being asked. This can lead to more accurate and relevant answers compared to models that don't have this additional guidance.
The researchers evaluate LaPA on several medical VQA datasets and show that it outperforms other state-of-the-art approaches. This suggests that the latent prompt representation is a promising technique for improving the performance of medical VQA systems, which could have important applications in healthcare and medical diagnosis.
Technical Explanation
The LaPA: Latent Prompt Assist Model For Medical Visual Question Answering paper introduces a new model architecture called LaPA that leverages a latent prompt representation to improve medical visual question answering (VQA) performance.
The key components of the LaPA model are:
-
Visual and Language Encoders: LaPA uses separate encoder networks to process the input image and the question text. These encoders extract relevant features from the visual and textual inputs.
-
Latent Prompt Generator: This module learns a latent prompt representation that captures the semantic and contextual information needed to guide the model's reasoning and answer generation process.
-
Prompt-Guided Reasoning: The latent prompt is used to condition the model's attention mechanism and feature fusion layers, helping it focus on the most relevant parts of the image and question to formulate the final answer.
The researchers evaluate LaPA on several medical VQA datasets, including VQA-RAD, VQA-MED, and Med-VQA. They show that LaPA outperforms existing state-of-the-art approaches, such as MedThink and Hallucination Benchmark, in terms of both overall accuracy and performance on specific question types.
Critical Analysis
The LaPA: Latent Prompt Assist Model For Medical Visual Question Answering paper presents a promising approach for improving medical VQA, but it also has some limitations and areas for further research.
One potential limitation is the reliance on the latent prompt representation, which may not be able to capture all the nuances and contextual information needed to answer complex medical questions. The paper does not provide a detailed analysis of the types of questions or images where the latent prompt is most effective, which could be useful for understanding the model's strengths and weaknesses.
Additionally, the paper focuses on evaluating LaPA on existing medical VQA datasets, but it would be interesting to see how the model performs on real-world medical applications, where the questions and images may be more diverse and challenging. Integrating question-driven techniques could also potentially improve the model's ability to understand and reason about the questions.
Overall, the LaPA: Latent Prompt Assist Model For Medical Visual Question Answering paper presents a promising step forward in improving medical VQA, and the latent prompt approach could have broader applications in other domains where visual and textual understanding are crucial.
Conclusion
The LaPA: Latent Prompt Assist Model For Medical Visual Question Answering paper introduces a new model called LaPA that leverages a latent prompt representation to improve medical visual question answering (VQA) performance. The key innovation is the use of this latent prompt to guide the model's reasoning and answer generation process, helping it better understand the context and requirements of the medical domain.
Experimental results on several medical VQA datasets show that LaPA outperforms existing state-of-the-art approaches, demonstrating the potential of this technique for improving the accuracy and robustness of medical VQA systems. This could have important implications for healthcare applications, such as assisting medical professionals in diagnosis and treatment planning.
While the paper presents a promising step forward, there are also opportunities for further research to address the model's limitations and explore its integration with other advanced techniques, such as question-driven approaches. Continued advancements in medical VQA could lead to significant improvements in the quality and accessibility of healthcare services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LaPA: Latent Prompt Assist Model For Medical Visual Question Answering
Tiancheng Gu, Kaicheng Yang, Dongnan Liu, Weidong Cai
Medical visual question answering (Med-VQA) aims to automate the prediction of correct answers for medical images and questions, thereby assisting physicians in reducing repetitive tasks and alleviating their workload. Existing approaches primarily focus on pre-training models using additional and comprehensive datasets, followed by fine-tuning to enhance performance in downstream tasks. However, there is also significant value in exploring existing models to extract clinically relevant information. In this paper, we propose the Latent Prompt Assist model (LaPA) for medical visual question answering. Firstly, we design a latent prompt generation module to generate the latent prompt with the constraint of the target answer. Subsequently, we propose a multi-modal fusion block with latent prompt fusion module that utilizes the latent prompt to extract clinical-relevant information from uni-modal and multi-modal features. Additionally, we introduce a prior knowledge fusion module to integrate the relationship between diseases and organs with the clinical-relevant information. Finally, we combine the final integrated information with image-language cross-modal information to predict the final answers. Experimental results on three publicly available Med-VQA datasets demonstrate that LaPA outperforms the state-of-the-art model ARL, achieving improvements of 1.83%, 0.63%, and 1.80% on VQA-RAD, SLAKE, and VQA-2019, respectively. The code is publicly available at https://github.com/GaryGuTC/LaPA_model.
Read more4/22/2024

0
Targeted Visual Prompting for Medical Visual Question Answering
Sergio Tascon-Morales, Pablo M'arquez-Neila, Raphael Sznitman
With growing interest in recent years, medical visual question answering (Med-VQA) has rapidly evolved, with multimodal large language models (MLLMs) emerging as an alternative to classical model architectures. Specifically, their ability to add visual information to the input of pre-trained LLMs brings new capabilities for image interpretation. However, simple visual errors cast doubt on the actual visual understanding abilities of these models. To address this, region-based questions have been proposed as a means to assess and enhance actual visual understanding through compositional evaluation. To combine these two perspectives, this paper introduces targeted visual prompting to equip MLLMs with region-based questioning capabilities. By presenting the model with both the isolated region and the region in its context in a customized visual prompt, we show the effectiveness of our method across multiple datasets while comparing it to several baseline models. Our code and data are available at https://github.com/sergiotasconmorales/locvqallm.
Read more8/7/2024

0
Prompting Medical Large Vision-Language Models to Diagnose Pathologies by Visual Question Answering
Danfeng Guo, Demetri Terzopoulos
Large Vision-Language Models (LVLMs) have achieved significant success in recent years, and they have been extended to the medical domain. Although demonstrating satisfactory performance on medical Visual Question Answering (VQA) tasks, Medical LVLMs (MLVLMs) suffer from the hallucination problem, which makes them fail to diagnose complex pathologies. Moreover, they readily fail to learn minority pathologies due to imbalanced training data. We propose two prompting strategies for MLVLMs that reduce hallucination and improve VQA performance. In the first strategy, we provide a detailed explanation of the queried pathology. In the second strategy, we fine-tune a cheap, weak learner to achieve high performance on a specific metric, and textually provide its judgment to the MLVLM. Tested on the MIMIC-CXR-JPG and Chexpert datasets, our methods significantly improve the diagnostic F1 score, with the highest increase being 0.27. We also demonstrate that our prompting strategies can be extended to general LVLM domains. Based on POPE metrics, it effectively suppresses the false negative predictions of existing LVLMs and improves Recall by approximately 0.07.
Read more8/1/2024
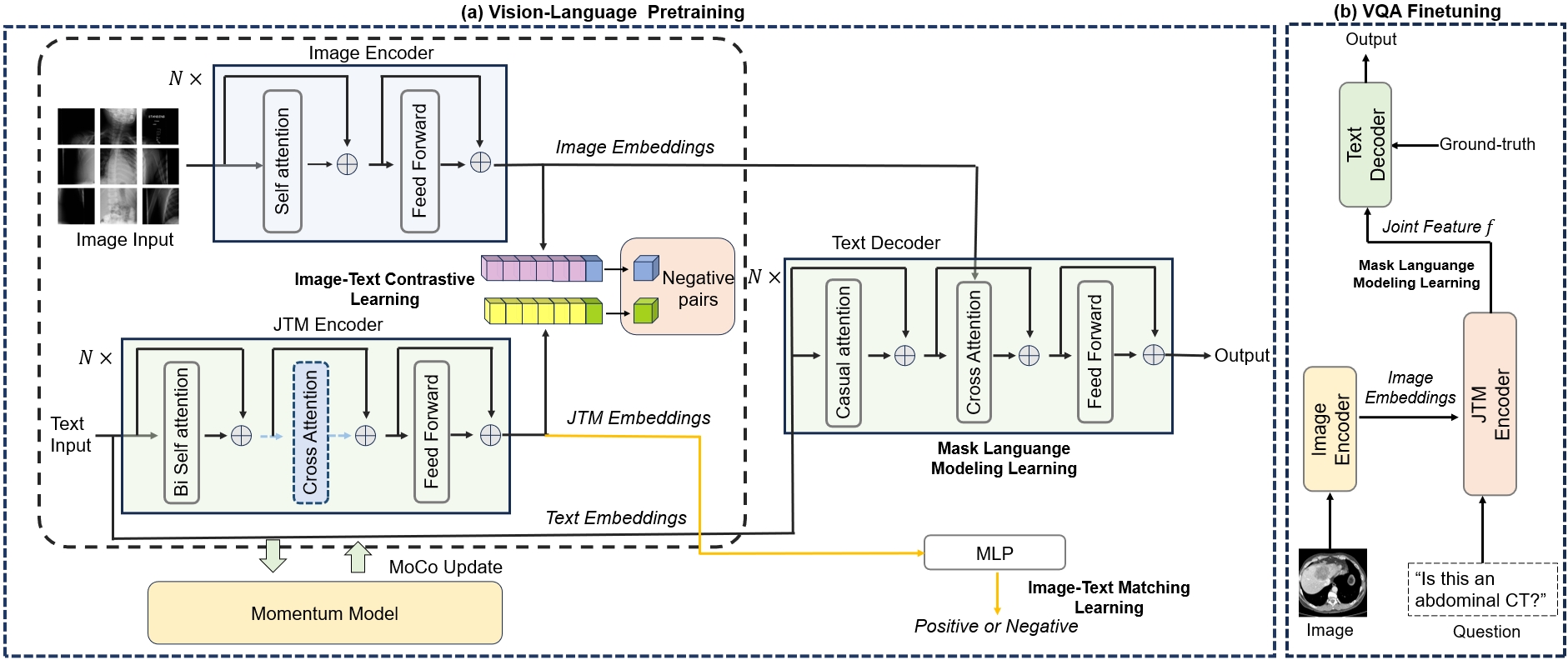
0
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jiawei Chen, Dingkang Yang, Yue Jiang, Yuxuan Lei, Lihua Zhang
Medical visual question answering (VQA) is a challenging multimodal task, where Vision-Language Pre-training (VLP) models can effectively improve the generalization performance. However, most methods in the medical field treat VQA as an answer classification task which is difficult to transfer to practical application scenarios. Additionally, due to the privacy of medical images and the expensive annotation process, large-scale medical image-text pairs datasets for pretraining are severely lacking. In this paper, we propose a large-scale MultI-task Self-Supervised learning based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning. Furthermore, we propose a Transfer-and-Caption method that extends the feature space of single-modal image datasets using Large Language Models (LLMs), enabling those traditional medical vision field task data to be applied to VLP. Experiments show that our method achieves excellent results with fewer multimodal datasets and demonstrates the advantages of generative VQA models.
Read more6/21/2024