Fusion-Eval: Integrating Assistant Evaluators with LLMs

0
🛠️
Sign in to get full access
Overview
- This paper introduces a new approach called "Fusion-Eval" for evaluating natural language systems, particularly in the areas of natural language understanding and high-level reasoning.
- Fusion-Eval leverages Large Language Models (LLMs) to integrate insights from various specialized assistant evaluators.
- The LLM is provided with the example to evaluate, along with scores from the different assistant evaluators, each of which focuses on assessing distinct aspects of the responses.
- Fusion-Eval achieves significantly higher correlations with human evaluation scores compared to baseline methods, demonstrating its potential for natural language system evaluation.
Plain English Explanation
Evaluating the performance of natural language systems, such as chatbots or virtual assistants, can be quite challenging, especially when it comes to understanding language and reasoning at a high level. The paper proposes a new approach called "Fusion-Eval" that aims to address these challenges.
The key idea behind Fusion-Eval is to use a Large Language Model (LLM) as a way to bring together the insights from multiple specialized assistant evaluators. Each of these assistants is designed to assess a particular aspect of the language system's responses, such as coherence, relevance, or depth of understanding.
The LLM is then given the example response to evaluate, along with the scores provided by the different assistant evaluators. By integrating this information, the LLM can provide an overall assessment that captures the various nuances of the language system's performance.
The researchers found that Fusion-Eval achieves significantly higher correlations with human evaluation scores compared to other methods. This suggests that the approach is quite effective at capturing the complexities of natural language system performance, and could be a valuable tool for evaluating and improving these systems.
Technical Explanation
The paper introduces the Fusion-Eval approach, which leverages Large Language Models (LLMs) to integrate insights from multiple specialized assistant evaluators for the task of natural language system evaluation.
The key components of Fusion-Eval are:
-
Assistant Evaluators: These are specialized models or systems that are designed to assess distinct aspects of a language system's responses, such as coherence, relevance, or depth of understanding.
-
LLM Integrator: The LLM is given the example response to evaluate, along with the scores provided by the different assistant evaluators. The LLM then uses this information to generate an overall assessment of the language system's performance.
The researchers evaluated Fusion-Eval on two benchmark datasets: SummEval for summarization and TopicalChat for open-domain dialogue. They found that Fusion-Eval achieved a 0.962 system-level Kendall-Tau correlation with human evaluation scores on SummEval, and a 0.744 turn-level Spearman correlation on TopicalChat. These results significantly outperformed baseline methods, highlighting the potential of Fusion-Eval for evaluating natural language systems.
Critical Analysis
The paper presents a promising approach for evaluating natural language systems, but it also acknowledges some potential limitations and areas for further research.
One potential concern is the reliance on specialized assistant evaluators, which may require significant effort to develop and maintain. The paper suggests that future work could explore ways to make the assistant evaluator development process more efficient and scalable.
Additionally, the paper focuses on the overall performance of the language systems, but does not delve into the specific strengths and weaknesses of the systems being evaluated. Future research could explore ways to provide more granular and actionable feedback to system developers.
Despite these considerations, the strong performance of Fusion-Eval compared to baseline methods is a promising result, and the approach has the potential to significantly advance the field of natural language system evaluation.
Conclusion
The paper introduces Fusion-Eval, a novel approach that leverages Large Language Models (LLMs) to integrate insights from multiple specialized assistant evaluators for the purpose of natural language system evaluation. The results demonstrate that Fusion-Eval significantly outperforms baseline methods, suggesting that it could be a valuable tool for evaluating and improving the performance of natural language systems, particularly in the areas of language understanding and high-level reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Fusion-Eval: Integrating Assistant Evaluators with LLMs
Lei Shu, Nevan Wichers, Liangchen Luo, Yun Zhu, Yinxiao Liu, Jindong Chen, Lei Meng
Evaluating natural language systems poses significant challenges, particularly in the realms of natural language understanding and high-level reasoning. In this paper, we introduce 'Fusion-Eval', an innovative approach that leverages Large Language Models (LLMs) to integrate insights from various assistant evaluators. The LLM is given the example to evaluate along with scores from the assistant evaluators. Each of these evaluators specializes in assessing distinct aspects of responses. Fusion-Eval achieves a 0.962 system-level Kendall-Tau correlation with humans on SummEval and a 0.744 turn-level Spearman correlation on TopicalChat, which is significantly higher than baseline methods. These results highlight Fusion-Eval's significant potential in the realm of natural language system evaluation.
Read more6/10/2024
💬
0
Large Language Models as Partners in Student Essay Evaluation
Toru Ishida, Tongxi Liu, Hailong Wang, William K. Cheung
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.
Read more5/30/2024

0
METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
Read more4/3/2024
0
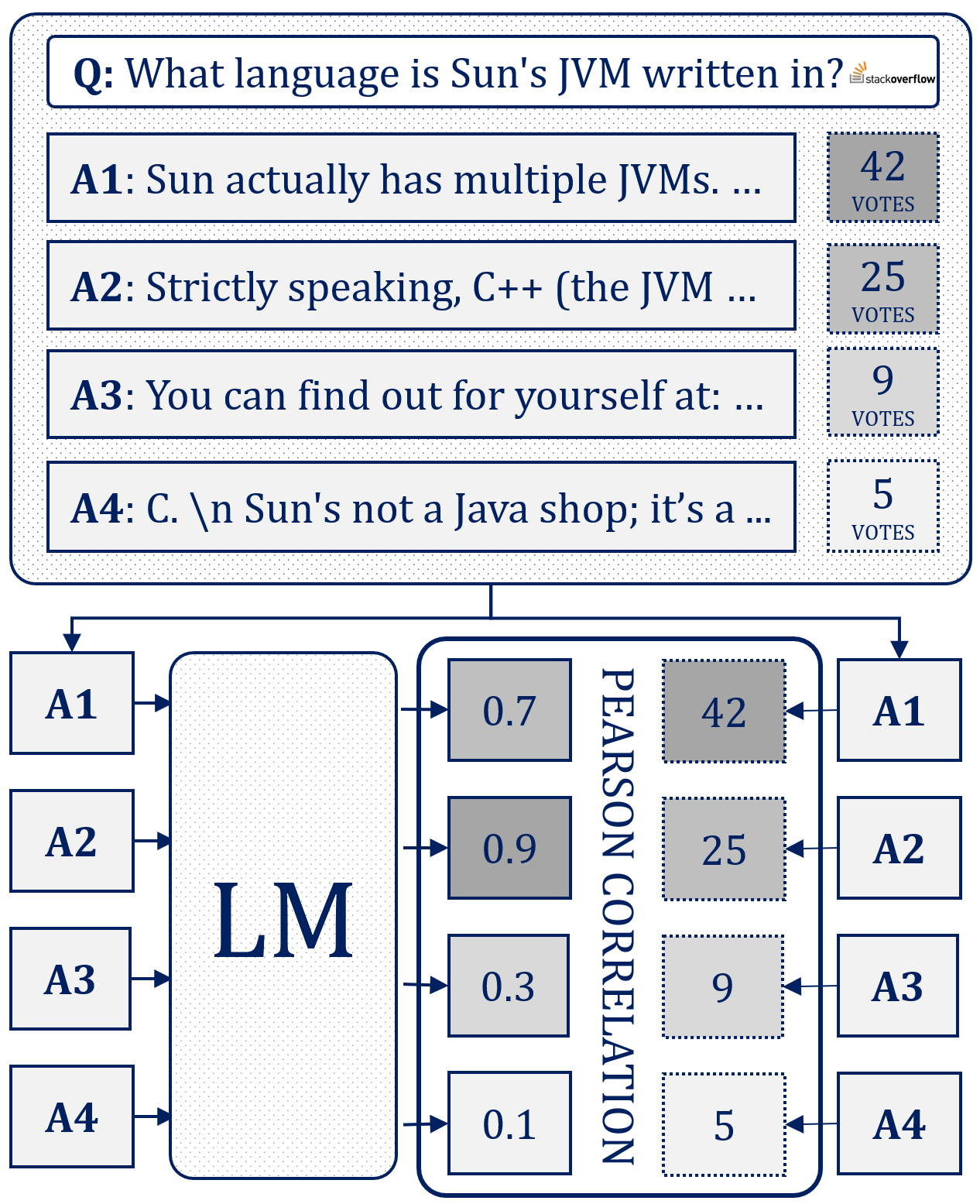
HumanRankEval: Automatic Evaluation of LMs as Conversational Assistants
Milan Gritta, Gerasimos Lampouras, Ignacio Iacobacci
Language models (LMs) as conversational assistants recently became popular tools that help people accomplish a variety of tasks. These typically result from adapting LMs pretrained on general domain text sequences through further instruction-tuning and possibly preference optimisation methods. The evaluation of such LMs would ideally be performed using human judgement, however, this is not scalable. On the other hand, automatic evaluation featuring auxiliary LMs as judges and/or knowledge-based tasks is scalable but struggles with assessing conversational ability and adherence to instructions. To help accelerate the development of LMs as conversational assistants, we propose a novel automatic evaluation task: HumanRankEval (HRE). It consists of a large-scale, diverse and high-quality set of questions, each with several answers authored and scored by humans. To perform evaluation, HRE ranks these answers based on their log-likelihood under the LM's distribution, and subsequently calculates their correlation with the corresponding human rankings. We support HRE's efficacy by investigating how efficiently it separates pretrained and instruction-tuned LMs of various sizes. We show that HRE correlates well with human judgements and is particularly responsive to model changes following instruction-tuning.
Read more5/16/2024