FusionBench: A Comprehensive Benchmark of Deep Model Fusion

0

Sign in to get full access
Overview
- FusionBench is a comprehensive benchmark for evaluating the performance of deep model fusion techniques.
- It provides a standardized set of datasets, tasks, and evaluation metrics to enable fair and systematic comparisons between different fusion methods.
- The benchmark covers a range of fusion scenarios, including multi-modal, multi-task, and cross-domain fusion, to capture the diverse needs of real-world applications.
Plain English Explanation
FusionBench: A Comprehensive Benchmark of Deep Model Fusion is a new tool that helps researchers and developers assess the capabilities of different deep learning models when they are combined or "fused" together. Deep learning is a powerful AI technique that can tackle a wide variety of tasks, but often these models are trained and optimized for specific problems. By fusing multiple deep models, you can potentially create a more versatile and capable system that can handle a broader range of challenges.
The key idea behind FusionBench is to provide a standardized set of test datasets, tasks, and evaluation metrics that can be used to compare the performance of different fusion techniques. This helps ensure a fair and consistent way to evaluate these methods, rather than relying on ad-hoc or inconsistent benchmarks. The benchmark covers several fusion scenarios, such as combining models that work with different types of data (e.g., images and text) or models trained for different but related tasks. This allows researchers to better understand the strengths and limitations of various fusion approaches in real-world applications.
Technical Explanation
FusionBench is designed to provide a comprehensive and standardized evaluation framework for assessing deep model fusion techniques. The benchmark encompasses a diverse set of datasets, tasks, and evaluation metrics to capture the various fusion scenarios that may arise in practice.
The benchmark includes datasets and tasks that cover multi-modal fusion (e.g., combining vision and language models), multi-task fusion (e.g., fusing models trained on related but distinct tasks), and cross-domain fusion (e.g., transferring knowledge from one domain to another). These fusion scenarios are crucial for developing versatile AI systems that can leverage the complementary expertise of multiple deep models.
To ensure fair and systematic comparisons, FusionBench defines a set of standardized evaluation metrics, such as task-specific performance measures and efficiency metrics like inference time and memory usage. These metrics allow researchers to assess the effectiveness, robustness, and practicality of different fusion approaches.
The FusionBench framework is designed to be extensible, allowing researchers to easily integrate new datasets, tasks, and fusion techniques into the benchmark. This flexibility ensures that the benchmark can evolve and keep pace with the rapid advancements in deep learning and fusion research.
Critical Analysis
The FusionBench benchmark is a valuable contribution to the field of deep model fusion, as it addresses the lack of a comprehensive and standardized evaluation framework. By providing a diverse set of datasets, tasks, and metrics, FusionBench enables researchers to rigorously assess the performance of their fusion techniques across a wide range of scenarios.
However, the paper acknowledges that the benchmark is not exhaustive and may not capture all possible fusion scenarios. As the field of deep learning continues to evolve, new fusion challenges and use cases may emerge that are not currently represented in the benchmark. Ongoing maintenance and updates to FusionBench will be crucial to ensure its relevance and usefulness over time.
Additionally, the paper does not delve into the specific implementation details or design choices behind the benchmark. While the authors mention the extensibility of the framework, more information about the benchmarking infrastructure and its flexibility for incorporating new fusion methods would be helpful for researchers seeking to use or contribute to FusionBench.
Conclusion
FusionBench is a significant step towards establishing a comprehensive and standardized evaluation framework for deep model fusion techniques. By providing a diverse set of datasets, tasks, and metrics, the benchmark enables researchers to systematically compare the performance of different fusion approaches and identify the most effective solutions for real-world applications.
The flexibility of the FusionBench framework, along with its coverage of various fusion scenarios, makes it a valuable resource for the research community. As deep learning and fusion techniques continue to evolve, the ongoing maintenance and expansion of FusionBench will be crucial to ensure its relevance and impact in driving the development of more versatile and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FusionBench: A Comprehensive Benchmark of Deep Model Fusion
Anke Tang, Li Shen, Yong Luo, Han Hu, Bo Du, Dacheng Tao
Deep model fusion is an emerging technique that unifies the predictions or parameters of several deep neural networks into a single model in a cost-effective and data-efficient manner. This enables the unified model to take advantage of the original models' strengths, potentially exceeding their performance. Although a variety of deep model fusion techniques have been introduced, their evaluations tend to be inconsistent and often inadequate to validate their effectiveness and robustness against distribution shifts. To address this issue, we introduce FusionBench, which is the first comprehensive benchmark dedicated to deep model fusion. FusionBench covers a wide range of tasks, including open-vocabulary image classification, text classification, and text-to-text generation. Each category includes up to eight tasks with corresponding task-specific models, featuring both full fine-tuning and LoRA fine-tuning, as well as models of different sizes, to ensure fair and balanced comparisons of various multi-task model fusion techniques across different tasks, model scales, and fine-tuning strategies. We implement and evaluate a broad spectrum of deep model fusion techniques. These techniques range from model ensemble methods, which combine the predictions to improve the overall performance, to model merging, which integrates different models into a single one, and model mixing methods, which upscale or recombine the components of the original models. FusionBench now contains 26 distinct tasks, 74 fine-tuned models, and 16 fusion techniques, and we are committed to consistently expanding the benchmark with more tasks, models, and fusion techniques. In addition, we offer a well-documented set of resources and guidelines to aid researchers in understanding and replicating the benchmark results. Homepage https://github.com/tanganke/fusion_bench
Read more6/17/2024

0
A Comprehensive Benchmark of Machine and Deep Learning Across Diverse Tabular Datasets
Assaf Shmuel, Oren Glickman, Teddy Lazebnik
The analysis of tabular datasets is highly prevalent both in scientific research and real-world applications of Machine Learning (ML). Unlike many other ML tasks, Deep Learning (DL) models often do not outperform traditional methods in this area. Previous comparative benchmarks have shown that DL performance is frequently equivalent or even inferior to models such as Gradient Boosting Machines (GBMs). In this study, we introduce a comprehensive benchmark aimed at better characterizing the types of datasets where DL models excel. Although several important benchmarks for tabular datasets already exist, our contribution lies in the variety and depth of our comparison: we evaluate 111 datasets with 20 different models, including both regression and classification tasks. These datasets vary in scale and include both those with and without categorical variables. Importantly, our benchmark contains a sufficient number of datasets where DL models perform best, allowing for a thorough analysis of the conditions under which DL models excel. Building on the results of this benchmark, we train a model that predicts scenarios where DL models outperform alternative methods with 86.1% accuracy (AUC 0.78). We present insights derived from this characterization and compare these findings to previous benchmarks.
Read more8/28/2024

0
Fusing Models with Complementary Expertise
Hongyi Wang, Felipe Maia Polo, Yuekai Sun, Souvik Kundu, Eric Xing, Mikhail Yurochkin
Training AI models that generalize across tasks and domains has long been among the open problems driving AI research. The emergence of Foundation Models made it easier to obtain expert models for a given task, but the heterogeneity of data that may be encountered at test time often means that any single expert is insufficient. We consider the Fusion of Experts (FoE) problem of fusing outputs of expert models with complementary knowledge of the data distribution and formulate it as an instance of supervised learning. Our method is applicable to both discriminative and generative tasks and leads to significant performance improvements in image and text classification, text summarization, multiple-choice QA, and automatic evaluation of generated text. We also extend our method to the frugal setting where it is desired to reduce the number of expert model evaluations at test time. Our implementation is publicly available at https://github.com/hwang595/FoE-ICLR2024.
Read more5/10/2024
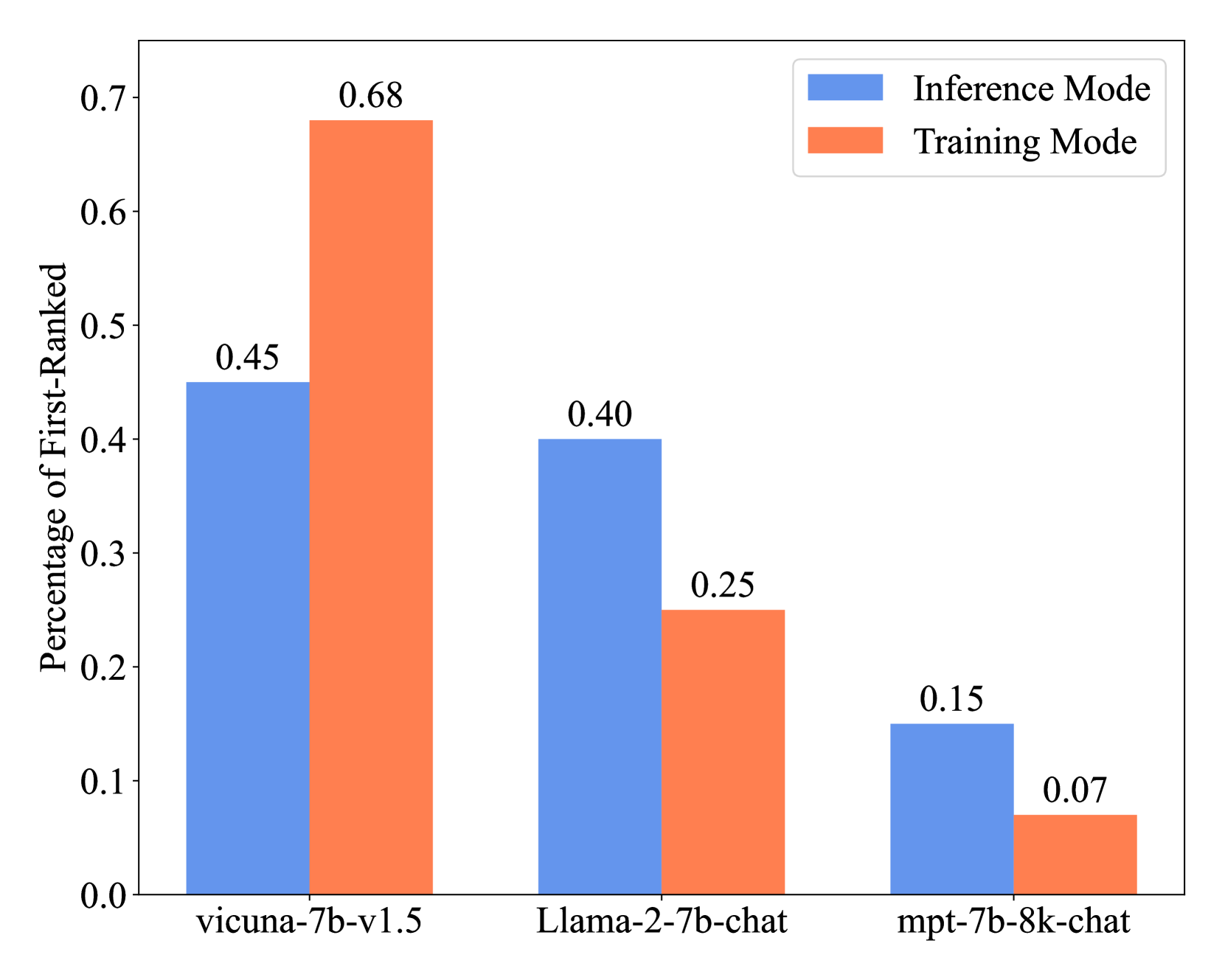
0
ProFuser: Progressive Fusion of Large Language Models
Tianyuan Shi, Fanqi Wan, Canbin Huang, Xiaojun Quan, Chenliang Li, Ming Yan, Ji Zhang
While fusing the capacities and advantages of various large language models (LLMs) offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during the training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including vicuna-7b-v1.5, Llama-2-7b-chat, and mpt-7b-8k-chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.
Read more8/12/2024