ProFuser: Progressive Fusion of Large Language Models

0
Sign in to get full access
Overview
- Proposes a novel method called "ProFuser" for progressively fusing large language models
- Aims to efficiently combine the capabilities of multiple pre-trained language models without catastrophic forgetting
- Experiments show ProFuser outperforms previous fusion approaches on various language tasks
Plain English Explanation
The paper introduces a new technique called "ProFuser" that allows researchers to combine the knowledge and abilities of multiple large language models in an efficient way. Large language models, like GPT-3, are powerful AI systems that can understand and generate human-like text. However, training these models from scratch is extremely resource-intensive.
The key idea behind ProFuser is to take several pre-trained language models and gradually "fuse" them together, rather than starting from scratch. This allows the model to build on the existing knowledge and capabilities of the individual models, while also learning new skills and information. The "progressive" part refers to how the fusion happens in stages, gradually merging the models over time.
ProFuser: Progressive Fusion of Large Language Models claims this approach outperforms previous methods for combining language models, achieving better performance on a range of language tasks. This could be very valuable, as it provides a more efficient way to create powerful AI systems that can draw on diverse sources of knowledge.
Technical Explanation
The paper first reviews prior work on combining or "fusing" language models, noting the limitations of approaches like fine-tuning or multi-task training. ProFuser is presented as a new fusion method that progressively aligns and integrates multiple pre-trained models.
The key steps in the ProFuser approach are:
-
Model Initialization: Start with a set of pre-trained language models (e.g. GPT-3, BERT, etc.).
-
Progressive Alignment: Gradually align the representations of the models by minimizing the distances between their hidden states.
-
Progressive Fusion: Progressively merge the model weights, combining the capabilities of the individual models.
-
Continued Pre-training: Further pre-train the fused model on a broad corpus to enhance its knowledge and abilities.
The authors conduct experiments comparing ProFuser to previous fusion methods on a variety of language tasks like question answering, textual entailment, and commonsense reasoning. They show that ProFuser achieves superior performance, demonstrating the effectiveness of its progressive fusion approach.
Critical Analysis
The paper provides a solid technical explanation of the ProFuser method and presents compelling experimental results. However, a few potential limitations or areas for further research are worth noting:
-
The authors acknowledge that ProFuser may struggle with "catastrophic forgetting" if the pre-trained models have very different capabilities or knowledge bases. More work may be needed to address this challenge.
-
The experiments focus on language tasks, but it's unclear how well ProFuser would generalize to other domains like vision or multi-modal understanding. Expanding the evaluation could strengthen the claims.
Knowledge Fusion by Evolving Weights of Language Models proposes a related but distinct approach to model fusion, which could be an interesting point of comparison.
Overall, ProFuser seems to be a promising technique that could significantly improve the efficiency of building powerful AI language models. But as with any new method, further research and real-world testing will be important to fully understand its strengths, limitations, and broader implications.
Conclusion
The ProFuser paper introduces an innovative approach to combining the capabilities of multiple large language models in a progressive and efficient manner. By gradually aligning and merging pre-trained models, the method can leverage existing knowledge to create more capable AI systems without the need for costly from-scratch training.
The strong experimental results suggest ProFuser could be a valuable tool for AI researchers and developers looking to build advanced language models. While some caveats and areas for further study remain, the core ideas behind ProFuser represent an important advancement in the field of knowledge fusion and model combination.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProFuser: Progressive Fusion of Large Language Models
Tianyuan Shi, Fanqi Wan, Canbin Huang, Xiaojun Quan, Chenliang Li, Ming Yan, Ji Zhang
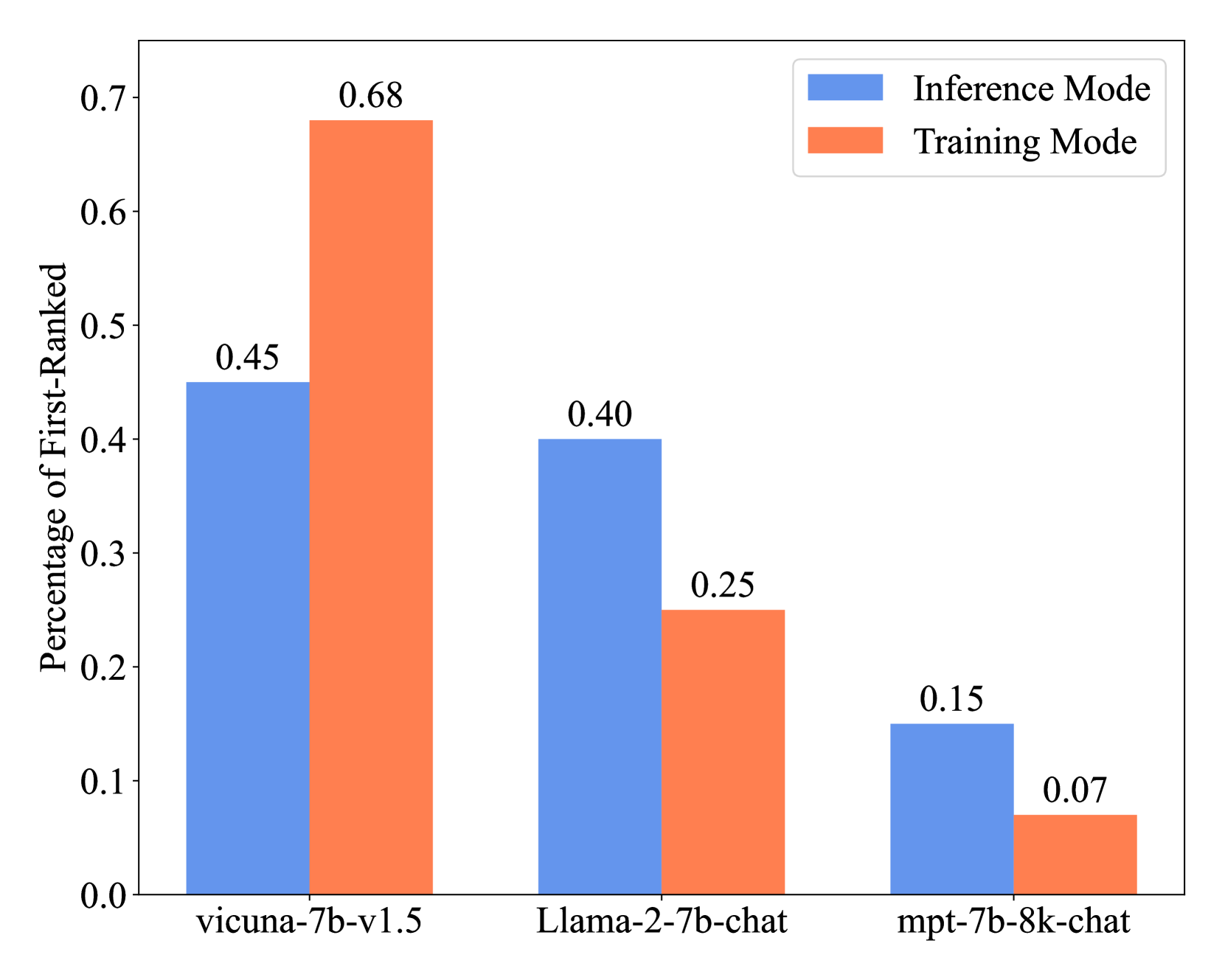
While fusing the capacities and advantages of various large language models (LLMs) offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during the training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including vicuna-7b-v1.5, Llama-2-7b-chat, and mpt-7b-8k-chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.
Read more8/12/2024
0
FuseChat: Knowledge Fusion of Chat Models
Fanqi Wan, Longguang Zhong, Ziyi Yang, Ruijun Chen, Xiaojun Quan
While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, it incurs substantial costs and may lead to redundancy in competencies. Knowledge fusion aims to integrate existing LLMs of diverse architectures and capabilities into a more potent LLM through lightweight continual training, thereby reducing the need for costly LLM development. In this work, we propose a new framework for the knowledge fusion of chat LLMs through two main stages, resulting in FuseChat. Firstly, we conduct pairwise knowledge fusion on source chat LLMs of varying structures and scales to create multiple target LLMs with identical structure and size via lightweight fine-tuning. During this process, a statistics-based token alignment approach is introduced as the cornerstone for fusing LLMs with different structures. Secondly, we merge these target LLMs within the parameter space, where we propose a novel method for determining the merging coefficients based on the magnitude of parameter updates before and after fine-tuning. We implement and validate FuseChat using six prominent chat LLMs with diverse architectures and scales, including OpenChat-3.5-7B, Starling-LM-7B-alpha, NH2-SOLAR-10.7B, InternLM2-Chat-20B, Mixtral-8x7B-Instruct, and Qwen-1.5-Chat-72B. Experimental results on two instruction-following benchmarks, AlpacaEval 2.0 and MT-Bench, demonstrate the superiority of FuseChat-7B over baselines of various sizes. Our model is even comparable to the larger Mixtral-8x7B-Instruct and approaches GPT-3.5-Turbo-1106 on MT-Bench. Our code, model weights, and data are public at url{https://github.com/fanqiwan/FuseAI}.
Read more8/16/2024

0
FuseChat: Knowledge Fusion of Chat Models
Fanqi Wan, Ziyi Yang, Longguang Zhong, Xiaojun Quan, Xinting Huang, Wei Bi
Recently, FuseLLM introduced the concept of knowledge fusion to transfer the collective knowledge of multiple structurally varied LLMs into a target LLM through lightweight continual training. In this report, we extend the scalability and flexibility of the FuseLLM framework to realize the fusion of chat LLMs, resulting in FusionChat. FusionChat comprises two main stages. Firstly, we undertake knowledge fusion for structurally and scale-varied source LLMs to derive multiple target LLMs of identical structure and size via lightweight fine-tuning. Then, these target LLMs are merged within the parameter space, wherein we propose a novel method for determining the merging weights based on the variation ratio of parameter matrices before and after fine-tuning. We validate our approach using three prominent chat LLMs with diverse architectures and scales, namely NH2-Mixtral-8x7B, NH2-Solar-10.7B, and OpenChat-3.5-7B. Experimental results spanning various chat domains demonstrate the superiority of FusionChat-7B across a broad spectrum of chat LLMs at 7B and 34B scales, even surpassing GPT-3.5 (March) and approaching Mixtral-8x7B-Instruct.
Read more5/29/2024

0
Cool-Fusion: Fuse Large Language Models without Training
Cong Liu, Xiaojun Quan, Yan Pan, Liang Lin, Weigang Wu, Xu Chen
We focus on the problem of fusing two or more heterogeneous large language models (LLMs) to facilitate their complementary strengths. One of the challenges on model fusion is high computational load, i.e. to fine-tune or to align vocabularies via combinatorial optimization. To this end, we propose emph{Cool-Fusion}, a simple yet effective approach that fuses the knowledge of heterogeneous source LLMs to leverage their complementary strengths. emph{Cool-Fusion} is the first method that does not require any type of training like the ensemble approaches. But unlike ensemble methods, it is applicable to any set of source LLMs that have different vocabularies. The basic idea is to have each source LLM individually generate tokens until the tokens can be decoded into a text segment that ends at word boundaries common to all source LLMs. Then, the source LLMs jointly rerank the generated text segment and select the best one, which is the fused text generation in one step. Extensive experiments are conducted across a variety of benchmark datasets. On emph{GSM8K}, emph{Cool-Fusion} increases accuracy from three strong source LLMs by a significant 8%-17.8%.
Read more7/30/2024