Language Models Still Struggle to Zero-shot Reason about Time Series
2404.11757
0
0
Abstract
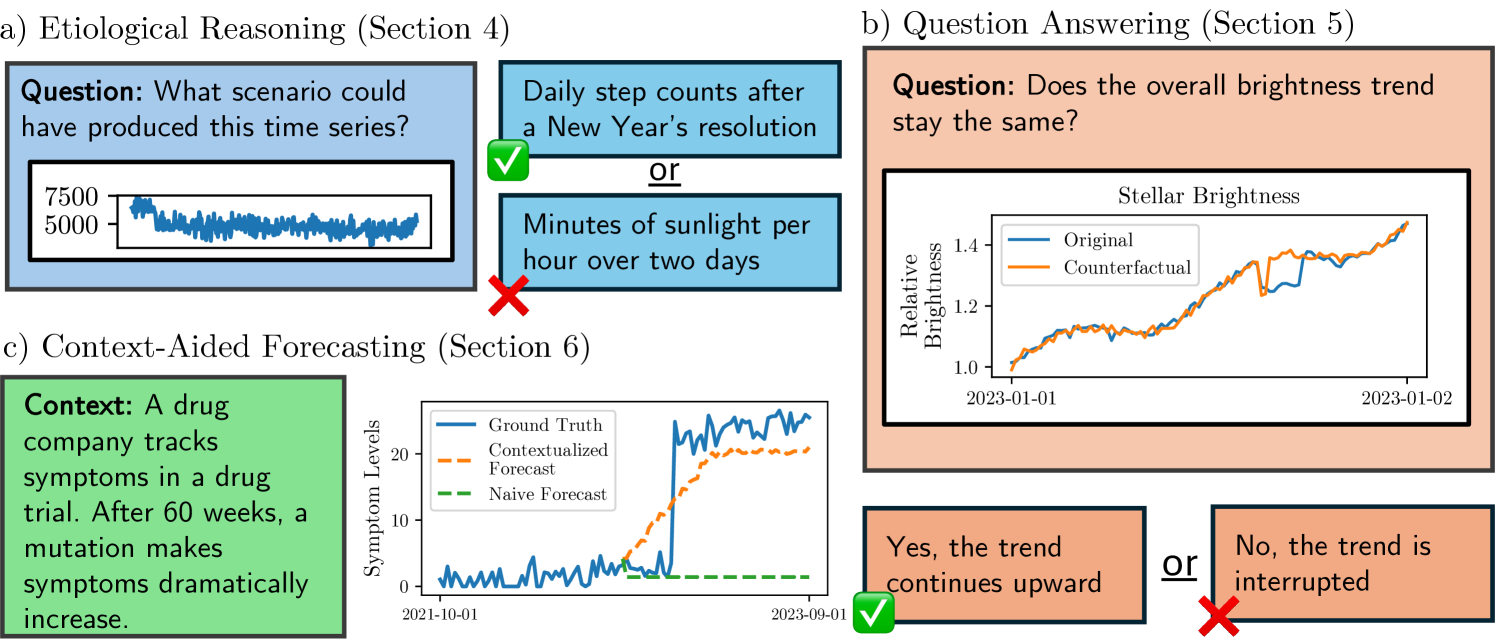
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the limitations of language models in zero-shot reasoning about time series data.
- The researchers developed a dataset to assess different forms of time series reasoning and evaluated the performance of large language models on this task.
- The results suggest that current language models still struggle to effectively reason about time series data, highlighting the need for further research and development in this area.
Plain English Explanation
Language models, the advanced artificial intelligence systems that can process and generate human-like text, have made impressive advances in recent years. However, this paper reveals that these models still have significant limitations when it comes to reasoning about time series data.
Time series data refers to a sequence of measurements or observations taken over time, such as stock prices, weather patterns, or sales figures. Reasoning about this type of data often requires understanding concepts like trends, cycles, and seasonality, as well as making predictions and drawing insights from the data.
The researchers behind this paper developed a specialized dataset to test different forms of time series reasoning, such as identifying patterns, making forecasts, and answering questions about the data. They then evaluated the performance of several large language models on this dataset, and the results were not very encouraging.
The language models struggled to accurately reason about the time series data, often making mistakes or providing responses that did not demonstrate a true understanding of the underlying concepts. This suggests that current language models, while powerful in many areas, still have significant room for improvement when it comes to working with time-dependent data.
The implications of this research are important for anyone working with time series data, from financial analysts to meteorologists. It highlights the need for further advancements in language model architecture, training, and evaluation to better equip these systems for the unique challenges of time series reasoning.
Technical Explanation
The researchers in this paper developed a dataset called the Time Series Reasoning (TSR) dataset to assess the ability of language models to reason about time series data in a zero-shot setting. The dataset covers a variety of time series reasoning tasks, including pattern identification, forecasting, and answering questions about the data.
To evaluate the performance of language models on the TSR dataset, the researchers tested several large, pre-trained models, including GPT-3, PALM, and BERT. The models were asked to perform the various time series reasoning tasks without any fine-tuning or additional training on the dataset.
The results showed that the language models struggled to effectively reason about the time series data, often making mistakes or providing responses that did not demonstrate a clear understanding of the underlying concepts. This was true across the different types of reasoning tasks, suggesting that current language models still have significant limitations when it comes to working with time-dependent data.
The researchers attribute this poor performance to the inherent challenges of time series reasoning, which requires a deep understanding of concepts like trends, cycles, and seasonality. They argue that existing language models, which are primarily trained on static, textual data, may not be well-equipped to handle the unique characteristics of time series data.
The paper also discusses potential avenues for future research, such as incorporating specialized time series modeling techniques into language model architectures or developing novel evaluation frameworks that better capture the nuances of time series reasoning.
Critical Analysis
The findings of this paper are significant and raise important questions about the limitations of current language models. While these models have demonstrated impressive capabilities in many domains, the struggle to reason about time series data highlights a crucial gap in their abilities.
One potential limitation of the research is the use of a relatively small dataset for the time series reasoning tasks. While the TSR dataset covers a range of relevant scenarios, a larger and more diverse dataset could provide a more comprehensive assessment of language model performance.
Additionally, the paper does not explore the potential impact of fine-tuning or further training the language models on time series data. It's possible that with specialized training, the models could improve their time series reasoning abilities, though this would require additional research.
Furthermore, the paper does not delve into the specific reasons why language models struggle with time series data. A deeper analysis of the underlying challenges, such as the models' difficulty in capturing temporal dependencies or understanding the unique characteristics of time-dependent data, could provide valuable insights for future research.
Despite these potential limitations, the paper's findings are an important contribution to the field of natural language processing. The researchers have identified a significant weakness in current language models and have laid the groundwork for further exploration and development in this area.
Conclusion
This paper highlights a critical limitation of current language models: their struggle to effectively reason about time series data. The researchers developed a specialized dataset to assess different forms of time series reasoning and found that large language models, despite their impressive capabilities in many domains, still struggle to perform these tasks.
The implications of this research are far-reaching, as time series data is ubiquitous across various industries and applications, from finance and economics to meteorology and supply chain management. The inability of language models to reason about this type of data poses a significant obstacle to their broader adoption and integration in real-world scenarios.
The findings of this paper underscore the need for further research and development in language model architecture, training, and evaluation to better equip these systems for the unique challenges of time series reasoning. By addressing this limitation, researchers and practitioners can unlock the full potential of language models and enable more robust and accurate decision-making across a wide range of applications.
Related Papers

A Survey of Time Series Foundation Models: Generalizing Time Series Representation with Large Language Mode
Jiexia Ye, Weiqi Zhang, Ke Yi, Yongzi Yu, Ziyue Li, Jia Li, Fugee Tsung
0
0
Time series data are ubiquitous across various domains, making time series analysis critically important. Traditional time series models are task-specific, featuring singular functionality and limited generalization capacity. Recently, large language foundation models have unveiled their remarkable capabilities for cross-task transferability, zero-shot/few-shot learning, and decision-making explainability. This success has sparked interest in the exploration of foundation models to solve multiple time series challenges simultaneously. There are two main research lines, namely pre-training foundation models from scratch for time series and adapting large language foundation models for time series. They both contribute to the development of a unified model that is highly generalizable, versatile, and comprehensible for time series analysis. This survey offers a 3E analytical framework for comprehensive examination of related research. Specifically, we examine existing works from three dimensions, namely Effectiveness, Efficiency and Explainability. In each dimension, we focus on discussing how related works devise tailored solution by considering unique challenges in the realm of time series. Furthermore, we provide a domain taxonomy to help followers keep up with the domain-specific advancements. In addition, we introduce extensive resources to facilitate the field's development, including datasets, open-source, time series libraries. A GitHub repository is also maintained for resource updates (https://github.com/start2020/Awesome-TimeSeries-LLM-FM).
5/8/2024
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
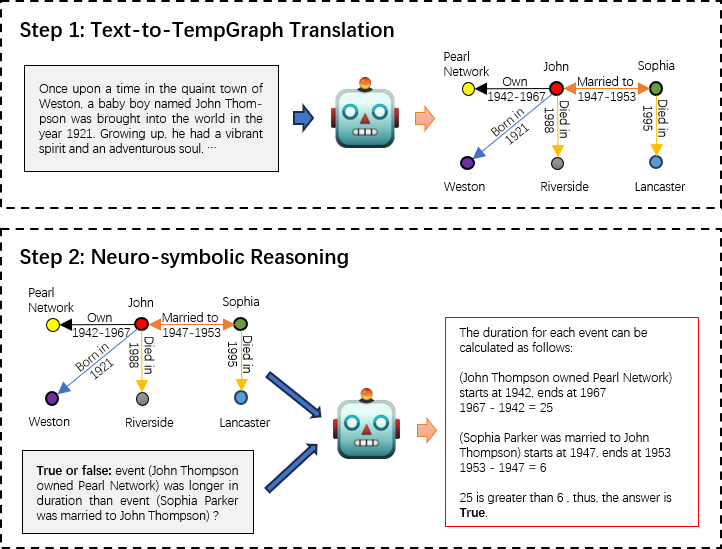
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal expressions and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that facilitates the TR learning. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain of Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
4/23/2024
💬
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Elizabeth Fons, Rachneet Kaur, Soham Palande, Zhen Zeng, Svitlana Vyetrenko, Tucker Balch
0
0
Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
4/26/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
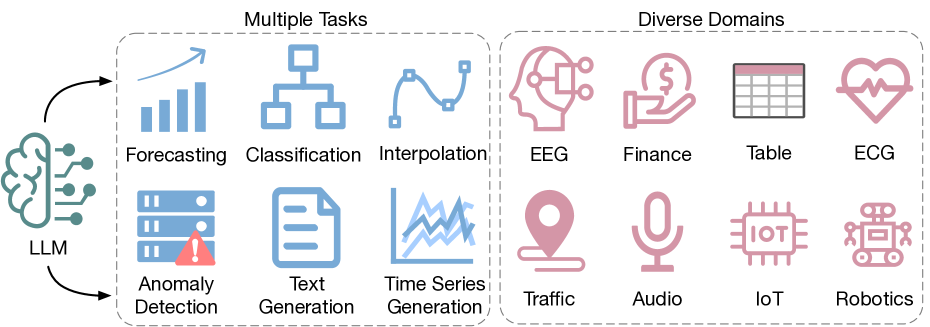
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024