FutureHuman3D: Forecasting Complex Long-Term 3D Human Behavior from Video Observations

0
🤿
Sign in to get full access
Overview
- The paper presents a generative approach to forecast long-term future human behavior in 3D, using only readily available 2D human action data for weak supervision.
- This is a fundamental task enabling many downstream applications, as capturing ground-truth 3D human motion data is challenging, while 2D data is easier to acquire.
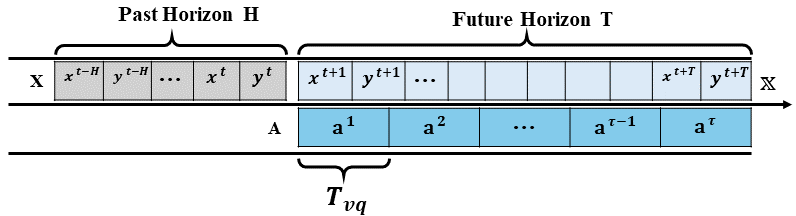
- The method predicts long and complex human behavior sequences, jointly forecasting high-level coarse action labels and their low-level fine-grained 3D realizations as characteristic human poses.
Plain English Explanation
The researchers have developed a way to predict how people will move and behave in 3D over long periods of time, using only 2D video data as a starting point. This is an important problem because capturing accurate 3D motion data, such as with specialized suits or setups, is difficult and expensive. However, regular 2D video cameras are much more accessible.
The key idea is to use the 2D video data to weakly supervise a model that can then generate long, complex 3D sequences of human behavior, such as cooking or assembling something. The model learns to predict not just the overall high-level actions, but also the detailed 3D poses and movements that make up those actions.
This joint prediction of high-level actions and low-level 3D poses is advantageous, as the two are closely related and can benefit each other. For example, knowing the overall action of "cooking" can help predict the characteristic 3D hand and body motions, while observing those 3D poses can reinforce the model's understanding of the cooking action.
Technical Explanation
The paper proposes a generative approach to forecast long-term future human behavior in 3D, using only weakly supervised 2D human action data. This is a crucial task enabling many downstream applications, as capturing ground-truth 3D human motion data is challenging, while 2D data is more readily available.
The method uses a differentiable 2D projection scheme in an autoregressive manner for weak supervision, and an adversarial loss for 3D regularization. It predicts long and complex human behavior sequences, jointly forecasting high-level coarse action labels and their low-level fine-grained 3D realizations as characteristic human poses.
The paper demonstrates that these two action representations are coupled, and joint prediction benefits both action and pose forecasting. The experiments show that the joint approach outperforms treating each task individually, enables robust longer-term sequence prediction, and improves over alternative methods.
Critical Analysis
The paper acknowledges that while the proposed method can generate long-term 3D human behavior sequences, there are still some limitations. For example, the reliability and uncertainty of the predictions are not fully addressed, and the model may struggle with more complex, intention-driven human actions.
Additionally, the paper does not discuss the potential biases or ethical considerations that may arise from such a system, such as how it might reflect or amplify societal biases in the training data. Further research is needed to ensure the fairness and responsible deployment of such predictive technologies.
Overall, the paper presents a promising approach to this challenging problem, but there is room for improvement, particularly in terms of robustness, uncertainty handling, and ethical considerations.
Conclusion
This paper introduces a novel generative approach to forecast long-term 3D human behavior, using only 2D video data for weak supervision. By jointly predicting high-level action labels and low-level 3D poses, the method can generate complex, realistic human motion sequences that outperform alternative approaches.
While the research has limitations and requires further refinement, it represents an important step towards enabling many downstream applications that rely on understanding and anticipating human behavior, such as robotics, human-computer interaction, and safety-critical systems. As the field continues to advance, it will be crucial to address the ethical implications and ensure these technologies are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
FutureHuman3D: Forecasting Complex Long-Term 3D Human Behavior from Video Observations
Christian Diller, Thomas Funkhouser, Angela Dai
We present a generative approach to forecast long-term future human behavior in 3D, requiring only weak supervision from readily available 2D human action data. This is a fundamental task enabling many downstream applications. The required ground-truth data is hard to capture in 3D (mocap suits, expensive setups) but easy to acquire in 2D (simple RGB cameras). Thus, we design our method to only require 2D RGB data at inference time while being able to generate 3D human motion sequences. We use a differentiable 2D projection scheme in an autoregressive manner for weak supervision, and an adversarial loss for 3D regularization. Our method predicts long and complex human behavior sequences (e.g., cooking, assembly) consisting of multiple sub-actions. We tackle this in a semantically hierarchical manner, jointly predicting high-level coarse action labels together with their low-level fine-grained realizations as characteristic 3D human poses. We observe that these two action representations are coupled in nature, and joint prediction benefits both action and pose forecasting. Our experiments demonstrate the complementary nature of joint action and 3D pose prediction: our joint approach outperforms each task treated individually, enables robust longer-term sequence prediction, and improves over alternative approaches to forecast actions and characteristic 3D poses.
Read more5/20/2024

0
Long-Term Human Trajectory Prediction using 3D Dynamic Scene Graphs
Nicolas Gorlo, Lukas Schmid, Luca Carlone
We present a novel approach for long-term human trajectory prediction, which is essential for long-horizon robot planning in human-populated environments. State-of-the-art human trajectory prediction methods are limited by their focus on collision avoidance and short-term planning, and their inability to model complex interactions of humans with the environment. In contrast, our approach overcomes these limitations by predicting sequences of human interactions with the environment and using this information to guide trajectory predictions over a horizon of up to 60s. We leverage Large Language Models (LLMs) to predict interactions with the environment by conditioning the LLM prediction on rich contextual information about the scene. This information is given as a 3D Dynamic Scene Graph that encodes the geometry, semantics, and traversability of the environment into a hierarchical representation. We then ground these interaction sequences into multi-modal spatio-temporal distributions over human positions using a probabilistic approach based on continuous-time Markov Chains. To evaluate our approach, we introduce a new semi-synthetic dataset of long-term human trajectories in complex indoor environments, which also includes annotations of human-object interactions. We show in thorough experimental evaluations that our approach achieves a 54% lower average negative log-likelihood (NLL) and a 26.5% lower Best-of-20 displacement error compared to the best non-privileged baselines for a time horizon of 60s.
Read more5/2/2024
0
Predicting Long-Term Human Behaviors in Discrete Representations via Physics-Guided Diffusion
Zhitian Zhang, Anjian Li, Angelica Lim, Mo Chen
Long-term human trajectory prediction is a challenging yet critical task in robotics and autonomous systems. Prior work that studied how to predict accurate short-term human trajectories with only unimodal features often failed in long-term prediction. Reinforcement learning provides a good solution for learning human long-term behaviors but can suffer from challenges in data efficiency and optimization. In this work, we propose a long-term human trajectory forecasting framework that leverages a guided diffusion model to generate diverse long-term human behaviors in a high-level latent action space, obtained via a hierarchical action quantization scheme using a VQ-VAE to discretize continuous trajectories and the available context. The latent actions are predicted by our guided diffusion model, which uses physics-inspired guidance at test time to constrain generated multimodal action distributions. Specifically, we use reachability analysis during the reverse denoising process to guide the diffusion steps toward physically feasible latent actions. We evaluate our framework on two publicly available human trajectory forecasting datasets: SFU-Store-Nav and JRDB, and extensive experimental results show that our framework achieves superior performance in long-term human trajectory forecasting.
Read more5/31/2024

0
Massively Multi-Person 3D Human Motion Forecasting with Scene Context
Felix B Mueller, Julian Tanke, Juergen Gall
Forecasting long-term 3D human motion is challenging: the stochasticity of human behavior makes it hard to generate realistic human motion from the input sequence alone. Information on the scene environment and the motion of nearby people can greatly aid the generation process. We propose a scene-aware social transformer model (SAST) to forecast long-term (10s) human motion motion. Unlike previous models, our approach can model interactions between both widely varying numbers of people and objects in a scene. We combine a temporal convolutional encoder-decoder architecture with a Transformer-based bottleneck that allows us to efficiently combine motion and scene information. We model the conditional motion distribution using denoising diffusion models. We benchmark our approach on the Humans in Kitchens dataset, which contains 1 to 16 persons and 29 to 50 objects that are visible simultaneously. Our model outperforms other approaches in terms of realism and diversity on different metrics and in a user study. Code is available at https://github.com/felixbmuller/SAST.
Read more9/19/2024