GEM3D: GEnerative Medial Abstractions for 3D Shape Synthesis
2402.16994
0
0
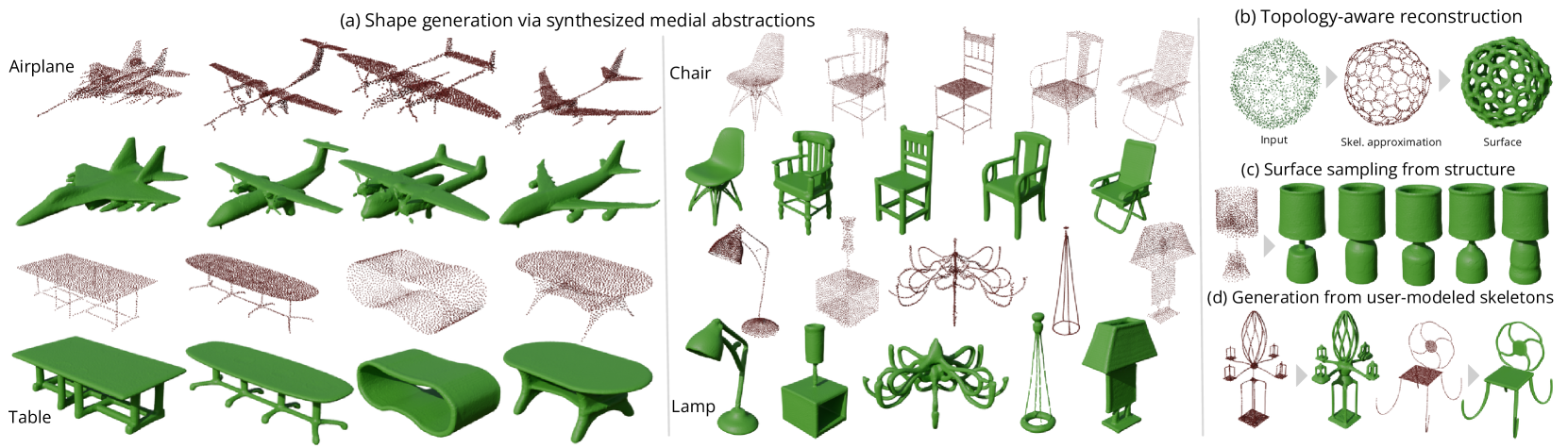
Abstract
We introduce GEM3D -- a new deep, topology-aware generative model of 3D shapes. The key ingredient of our method is a neural skeleton-based representation encoding information on both shape topology and geometry. Through a denoising diffusion probabilistic model, our method first generates skeleton-based representations following the Medial Axis Transform (MAT), then generates surfaces through a skeleton-driven neural implicit formulation. The neural implicit takes into account the topological and geometric information stored in the generated skeleton representations to yield surfaces that are more topologically and geometrically accurate compared to previous neural field formulations. We discuss applications of our method in shape synthesis and point cloud reconstruction tasks, and evaluate our method both qualitatively and quantitatively. We demonstrate significantly more faithful surface reconstruction and diverse shape generation results compared to the state-of-the-art, also involving challenging scenarios of reconstructing and synthesizing structurally complex, high-genus shape surfaces from Thingi10K and ShapeNet.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces GEM3D, a novel approach for 3D shape synthesis using generative medial abstractions.
- GEM3D leverages a medial representation of 3D shapes to enable efficient and controllable generation of diverse 3D shapes.
- The method outperforms state-of-the-art 3D generation techniques on several benchmark tasks.
Plain English Explanation
The paper presents a new way to generate 3D shapes called GEM3D. Traditional 3D modeling can be complex and time-consuming, so the researchers developed a more efficient approach.
GEM3D works by representing 3D shapes using a "medial" representation, which captures the central structure or "skeleton" of the shape. This medial representation allows the system to generate diverse 3D shapes in a more controlled and efficient manner compared to other 3D generation methods.
The researchers show that GEM3D outperforms existing 3D generation techniques on standard benchmarks. This suggests the medial representation is a powerful way to tackle the challenge of 3D shape synthesis, which has important applications in areas like computer graphics, animation, and product design.
Technical Explanation
The paper introduces GEM3D, a novel approach for 3D shape synthesis that leverages a generative medial abstraction. Rather than directly generating 3D shapes, GEM3D first learns to generate a medial representation, which captures the central structure or "skeleton" of a 3D shape. This medial representation is then used to efficiently reconstruct the full 3D geometry.
The key innovation of GEM3D is the use of this medial representation as an intermediate step in the generation process. This allows the model to capture the essential structural properties of 3D shapes in a more compact and controllable way, enabling the synthesis of diverse and high-quality 3D content.
The authors evaluate GEM3D on several 3D shape generation benchmark tasks, demonstrating that it outperforms state-of-the-art methods like G3DR, 3D Human Reconstruction in the Wild, and IDEA-2. GEM3D also shows improved performance on tasks like 3D Geometry-Aware Deformable Gaussian Splatting and Text-to-3D, demonstrating the versatility and effectiveness of the medial representation approach.
Critical Analysis
The paper provides a comprehensive evaluation of GEM3D and thoroughly compares it to prior work. However, the authors acknowledge several limitations and areas for future research. For example, the medial representation may struggle to capture fine-grained details of complex 3D shapes, and the generation process could potentially be further optimized for speed and efficiency.
Additionally, while the results demonstrate the benefits of the medial representation, it would be interesting to understand the tradeoffs in expressiveness compared to directly generating 3D shapes. The authors could also explore the interpretability and explainability of the medial representation, which could be valuable for certain applications.
Overall, the GEM3D approach represents a promising direction in 3D shape synthesis, and the paper provides a solid foundation for further research and development in this area.
Conclusion
The GEM3D paper introduces a novel approach for 3D shape synthesis that leverages a generative medial abstraction. By representing 3D shapes using a compact and controllable medial representation, GEM3D is able to outperform state-of-the-art methods on various 3D generation tasks.
This work highlights the potential of using intermediate representations, like the medial abstraction, to tackle challenging 3D modeling problems. The approach has important implications for applications in computer graphics, animation, and product design, where the ability to efficiently generate diverse and high-quality 3D content is highly valuable.
The researchers have demonstrated the effectiveness of the GEM3D method, and future work could explore further refinements and extensions of the medial representation to address the identified limitations and expand the capabilities of 3D shape synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

G3DR: Generative 3D Reconstruction in ImageNet
Pradyumna Reddy, Ismail Elezi, Jiankang Deng
0
0
We introduce a novel 3D generative method, Generative 3D Reconstruction (G3DR) in ImageNet, capable of generating diverse and high-quality 3D objects from single images, addressing the limitations of existing methods. At the heart of our framework is a novel depth regularization technique that enables the generation of scenes with high-geometric fidelity. G3DR also leverages a pretrained language-vision model, such as CLIP, to enable reconstruction in novel views and improve the visual realism of generations. Additionally, G3DR designs a simple but effective sampling procedure to further improve the quality of generations. G3DR offers diverse and efficient 3D asset generation based on class or text conditioning. Despite its simplicity, G3DR is able to beat state-of-theart methods, improving over them by up to 22% in perceptual metrics and 90% in geometry scores, while needing only half of the training time. Code is available at https://github.com/preddy5/G3DR
4/4/2024
🛸
Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields
Yuhang Huang, SHilong Zou, Xinwang Liu, Kai Xu
0
0
This paper presents a novel latent 3D diffusion model for the generation of neural voxel fields, aiming to achieve accurate part-aware structures. Compared to existing methods, there are two key designs to ensure high-quality and accurate part-aware generation. On one hand, we introduce a latent 3D diffusion process for neural voxel fields, enabling generation at significantly higher resolutions that can accurately capture rich textural and geometric details. On the other hand, a part-aware shape decoder is introduced to integrate the part codes into the neural voxel fields, guiding the accurate part decomposition and producing high-quality rendering results. Through extensive experimentation and comparisons with state-of-the-art methods, we evaluate our approach across four different classes of data. The results demonstrate the superior generative capabilities of our proposed method in part-aware shape generation, outperforming existing state-of-the-art methods.
5/10/2024
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Yongtao Ge, Wenjia Wang, Yongfan Chen, Hao Chen, Chunhua Shen
0
0
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
4/12/2024

Interactive3D: Create What You Want by Interactive 3D Generation
Shaocong Dong, Lihe Ding, Zhanpeng Huang, Zibin Wang, Tianfan Xue, Dan Xu
0
0
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at url{https://interactive-3d.github.io/}.
4/26/2024