AHDGAN: An Attention-Based Generator and Heterogeneous Dual-Discriminator Generative Adversarial Network for Infrared and Visible Image Fusion

0
Sign in to get full access
Overview
- This paper presents a new generative adversarial network (GAN) called HDDGAN for fusing infrared and visible images.
- HDDGAN uses a heterogeneous dual-discriminator approach to improve the quality and realism of the fused images.
- The authors demonstrate the effectiveness of HDDGAN on several image fusion tasks and benchmark datasets.
Plain English Explanation
The paper introduces a new deep learning model called HDDGAN that can combine infrared and visible (regular) images into a single, high-quality image. Infrared cameras can see details that regular cameras miss, like heat signatures, but the images they produce can look a bit strange. HDDGAN takes the best parts of both infrared and visible images and blends them together seamlessly.
The key innovation in HDDGAN is that it uses two separate discriminator networks to assess the fused images. One discriminator checks if the images look realistic, while the other checks if the important details from both the infrared and visible images have been preserved. This "dual-discriminator" approach helps HDDGAN produce fused images that are not only visually appealing, but also contain all the critical information from the original images.
The authors show that HDDGAN outperforms other state-of-the-art image fusion methods on several benchmark datasets, meaning it can create better-quality fused images than its competitors. This could be useful for applications like surveillance, navigation, and medical imaging, where getting accurate and clear images from different camera types is important.
Technical Explanation
The paper proposes a heterogeneous dual-discriminator generative adversarial network (HDDGAN) for infrared and visible image fusion. The key components of HDDGAN include:
- A generator network that takes infrared and visible images as input and produces a fused output image.
- Two discriminator networks: one that evaluates the realism of the fused image, and another that assesses the preservation of important details from the input images.
- A multi-scale structural similarity (MS-SSIM) loss function that encourages the generator to produce fused images that are both visually appealing and retain crucial information from the input images.
The authors evaluate HDDGAN on several benchmark datasets and show that it outperforms other state-of-the-art image fusion methods, such as IaIFNet, VIFNet, SAMGN, and IMST. The results demonstrate the effectiveness of HDDGAN's heterogeneous dual-discriminator approach in producing high-quality fused images.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated image fusion model, HDDGAN, that addresses the limitations of previous approaches. The use of a heterogeneous dual-discriminator architecture is a novel and promising idea that seems to improve the quality and realism of the fused images.
However, the paper does not discuss potential limitations or caveats of the HDDGAN approach. For example, it is unclear how the model would perform on more challenging or diverse datasets, or how it would handle cases where the input infrared and visible images have significant misalignment or differences in scale and resolution.
Additionally, the paper does not provide much insight into the internal workings of the HDDGAN model, such as the specific architectural details of the generator and discriminator networks, or the training process and hyperparameter tuning. This makes it difficult for readers to fully understand the nuances of the approach and potentially reproduce the results.
Further research could explore the generalization capabilities of HDDGAN, its robustness to different fusion scenarios, and potential extensions or improvements to the core architecture. Incorporating these aspects could strengthen the paper and provide a more comprehensive understanding of the model's strengths and limitations.
Conclusion
The HDDGAN model presented in this paper represents a significant advancement in the field of infrared and visible image fusion. By leveraging a heterogeneous dual-discriminator approach, the authors have developed a GAN-based system that can produce high-quality fused images that retain crucial details from both input modalities.
The demonstrated performance of HDDGAN on benchmark datasets suggests that it could be a valuable tool for a wide range of applications, such as surveillance, autonomous navigation, and medical imaging, where accurate and informative fusion of infrared and visible data is essential.
While the paper does not explore the limitations of the approach in depth, the core ideas behind HDDGAN are innovative and promising, and could inspire further research and development in this important area of computer vision and image processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AHDGAN: An Attention-Based Generator and Heterogeneous Dual-Discriminator Generative Adversarial Network for Infrared and Visible Image Fusion
Guosheng Lu, Zile Fang, Jiaju Tian, Haowen Huang, Yuelong Xu, Zhuolin Han, Yaoming Kang, Can Feng, Zhigang Zhao
Infrared and visible image fusion (IVIF) aims to preserve thermal radiation information from infrared images while integrating texture details from visible images. Thermal radiation information is mainly expressed through image intensities, while texture details are typically expressed through image gradients. However, existing dual-discriminator generative adversarial networks (GANs) often rely on two structurally identical discriminators for learning, which do not fully account for the distinct learning needs of infrared and visible image information. To this end, this paper proposes a novel GAN with a heterogeneous dual-discriminator network and an attention-based fusion strategy (GAN-HA). Specifically, recognizing the intrinsic differences between infrared and visible images, we propose, for the first time, a novel heterogeneous dual-discriminator network to simultaneously capture thermal radiation information and texture details. The two discriminators in this network are structurally different, including a salient discriminator for infrared images and a detailed discriminator for visible images. They are able to learn rich image intensity information and image gradient information, respectively. In addition, a new attention-based fusion strategy is designed in the generator to appropriately emphasize the learned information from different source images, thereby improving the information representation ability of the fusion result. In this way, the fused images generated by GAN-HA can more effectively maintain both the salience of thermal targets and the sharpness of textures. Extensive experiments on various public datasets demonstrate the superiority of GAN-HA over other state-of-the-art (SOTA) algorithms while showcasing its higher potential for practical applications.
Read more9/5/2024

0
IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network
Qiao Yang, Yu Zhang, Zijing Zhao, Jian Zhang, Shunli Zhang
Infrared and visible image fusion (IVIF) is used to generate fusion images with comprehensive features of both images, which is beneficial for downstream vision tasks. However, current methods rarely consider the illumination condition in low-light environments, and the targets in the fused images are often not prominent. To address the above issues, we propose an Illumination-Aware Infrared and Visible Image Fusion Network, named as IAIFNet. In our framework, an illumination enhancement network first estimates the incident illumination maps of input images. Afterwards, with the help of proposed adaptive differential fusion module (ADFM) and salient target aware module (STAM), an image fusion network effectively integrates the salient features of the illumination-enhanced infrared and visible images into a fusion image of high visual quality. Extensive experimental results verify that our method outperforms five state-of-the-art methods of fusing infrared and visible images.
Read more5/28/2024
0
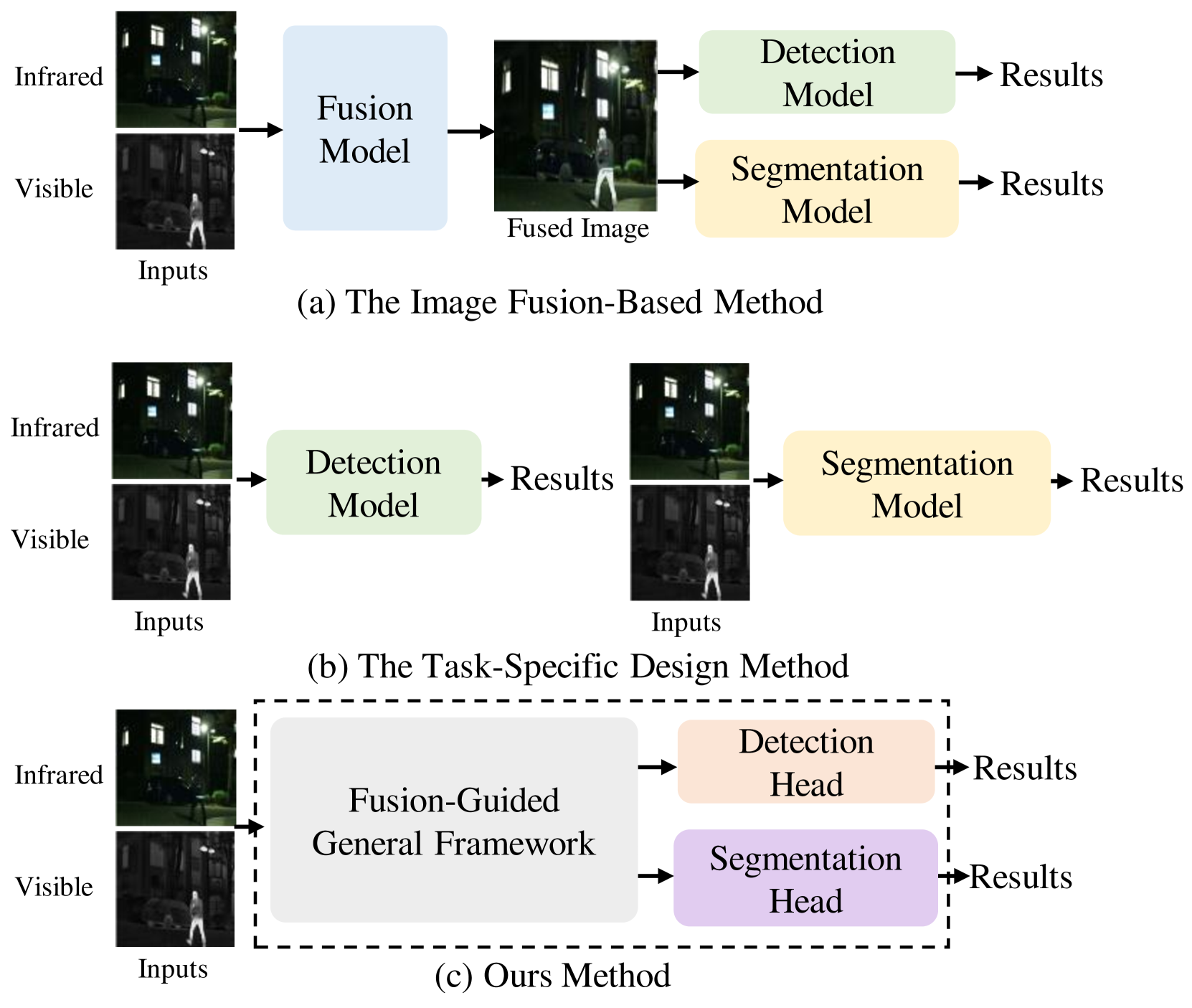
IVGF: The Fusion-Guided Infrared and Visible General Framework
Fangcen Liu, Chenqiang Gao, Fang Chen, Pengcheng Li, Junjie Guo, Deyu Meng
Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
Read more9/17/2024

0
VIFNet: An End-to-end Visible-Infrared Fusion Network for Image Dehazing
Meng Yu, Te Cui, Haoyang Lu, Yufeng Yue
Image dehazing poses significant challenges in environmental perception. Recent research mainly focus on deep learning-based methods with single modality, while they may result in severe information loss especially in dense-haze scenarios. The infrared image exhibits robustness to the haze, however, existing methods have primarily treated the infrared modality as auxiliary information, failing to fully explore its rich information in dehazing. To address this challenge, the key insight of this study is to design a visible-infrared fusion network for image dehazing. In particular, we propose a multi-scale Deep Structure Feature Extraction (DSFE) module, which incorporates the Channel-Pixel Attention Block (CPAB) to restore more spatial and marginal information within the deep structural features. Additionally, we introduce an inconsistency weighted fusion strategy to merge the two modalities by leveraging the more reliable information. To validate this, we construct a visible-infrared multimodal dataset called AirSim-VID based on the AirSim simulation platform. Extensive experiments performed on challenging real and simulated image datasets demonstrate that VIFNet can outperform many state-of-the-art competing methods. The code and dataset are available at https://github.com/mengyu212/VIFNet_dehazing.
Read more4/12/2024