IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network

0

Sign in to get full access
Overview
- Proposed an Illumination-Aware Infrared and Visible Image Fusion Network (IAIFNet) to fuse infrared and visible images while considering illumination differences
- Designed a two-stream architecture with an illumination-aware feature extraction module to capture illumination-aware features
- Introduced a cross-modality attention mechanism to selectively integrate features from both modalities
- Demonstrated state-of-the-art performance on multiple benchmark datasets for infrared and visible image fusion
Plain English Explanation
The paper discusses an Illumination-Aware Infrared and Visible Image Fusion Network (IAIFNet) that is designed to combine infrared and visible images in a way that takes into account differences in lighting conditions. Infrared and visible images can provide complementary information, but their fusion is challenging due to varying illumination levels.
The proposed IAIFNet uses a two-stream architecture, where one stream focuses on extracting illumination-aware features from the input images. This is done through a specialized module that is designed to be sensitive to illumination differences. The other stream extracts general features from the images.
The features from the two streams are then combined using a cross-modality attention mechanism. This allows the network to selectively integrate the most relevant information from both the infrared and visible inputs, while accounting for the illumination differences between them.
The researchers show that IAIFNet outperforms other state-of-the-art methods for infrared and visible image fusion on several benchmark datasets. This suggests that explicitly considering illumination differences can lead to significant improvements in the quality of the fused output.
Technical Explanation
The IAIFNet architecture consists of two main components: an illumination-aware feature extraction module and a cross-modality attention mechanism.
Illumination-Aware Feature Extraction Module
This module is designed to capture illumination-aware features from the input infrared and visible images. It includes a Illumination-Aware Encoder (IAE) that uses a series of convolutional and normalization layers to extract features sensitive to illumination differences.
The IAE is complemented by a Multi-Modal Asymmetric U-Net (MMA-UNet) that combines the illumination-aware features with more general features extracted from the input images.
Cross-Modality Attention Mechanism
The features from the illumination-aware and general feature extraction streams are then integrated using a cross-modality attention mechanism. This allows the network to selectively focus on the most relevant information from each modality, taking into account the illumination differences between them.
The attention mechanism is inspired by the Adaptive Mixed-Scale Feature Fusion Network (AMSF-Net) and the Unified Framework for Visible-Infrared Downstream Tasks (UniRGBIR).
Critical Analysis
The paper makes a compelling case for the importance of considering illumination differences when fusing infrared and visible images. The proposed IAIFNet architecture demonstrates strong performance on benchmark datasets, suggesting that the illumination-aware feature extraction and cross-modality attention mechanisms are effective.
However, the paper does not provide much insight into the limitations of the approach or potential areas for further research. For example, it would be interesting to understand how IAIFNet performs in more challenging real-world scenarios with significant variations in illumination, or how it compares to other fusion methods that do not explicitly consider illumination.
Additionally, the paper focuses on image fusion, but does not explore the potential downstream applications or societal implications of this technology. Further research could investigate how IAIFNet-fused images might be used in tasks like surveillance, search and rescue, or autonomous navigation, and consider the ethical considerations around the use of such systems.
Conclusion
The Illumination-Aware Infrared and Visible Image Fusion Network (IAIFNet) represents a significant advance in the field of infrared and visible image fusion by explicitly addressing the challenge of varying illumination conditions. The two-stream architecture with illumination-aware feature extraction and cross-modality attention mechanisms allows the network to effectively integrate complementary information from the two modalities, leading to state-of-the-art performance on benchmark datasets.
While the paper does not explore the limitations and potential societal implications of this technology in depth, the core ideas presented have the potential to improve a wide range of applications that rely on fusing infrared and visible imagery, from surveillance and search and rescue to autonomous navigation and decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network
Qiao Yang, Yu Zhang, Zijing Zhao, Jian Zhang, Shunli Zhang
Infrared and visible image fusion (IVIF) is used to generate fusion images with comprehensive features of both images, which is beneficial for downstream vision tasks. However, current methods rarely consider the illumination condition in low-light environments, and the targets in the fused images are often not prominent. To address the above issues, we propose an Illumination-Aware Infrared and Visible Image Fusion Network, named as IAIFNet. In our framework, an illumination enhancement network first estimates the incident illumination maps of input images. Afterwards, with the help of proposed adaptive differential fusion module (ADFM) and salient target aware module (STAM), an image fusion network effectively integrates the salient features of the illumination-enhanced infrared and visible images into a fusion image of high visual quality. Extensive experimental results verify that our method outperforms five state-of-the-art methods of fusing infrared and visible images.
Read more5/28/2024

0
VIFNet: An End-to-end Visible-Infrared Fusion Network for Image Dehazing
Meng Yu, Te Cui, Haoyang Lu, Yufeng Yue
Image dehazing poses significant challenges in environmental perception. Recent research mainly focus on deep learning-based methods with single modality, while they may result in severe information loss especially in dense-haze scenarios. The infrared image exhibits robustness to the haze, however, existing methods have primarily treated the infrared modality as auxiliary information, failing to fully explore its rich information in dehazing. To address this challenge, the key insight of this study is to design a visible-infrared fusion network for image dehazing. In particular, we propose a multi-scale Deep Structure Feature Extraction (DSFE) module, which incorporates the Channel-Pixel Attention Block (CPAB) to restore more spatial and marginal information within the deep structural features. Additionally, we introduce an inconsistency weighted fusion strategy to merge the two modalities by leveraging the more reliable information. To validate this, we construct a visible-infrared multimodal dataset called AirSim-VID based on the AirSim simulation platform. Extensive experiments performed on challenging real and simulated image datasets demonstrate that VIFNet can outperform many state-of-the-art competing methods. The code and dataset are available at https://github.com/mengyu212/VIFNet_dehazing.
Read more4/12/2024
0
AHDGAN: An Attention-Based Generator and Heterogeneous Dual-Discriminator Generative Adversarial Network for Infrared and Visible Image Fusion
Guosheng Lu, Zile Fang, Jiaju Tian, Haowen Huang, Yuelong Xu, Zhuolin Han, Yaoming Kang, Can Feng, Zhigang Zhao
Infrared and visible image fusion (IVIF) aims to preserve thermal radiation information from infrared images while integrating texture details from visible images. Thermal radiation information is mainly expressed through image intensities, while texture details are typically expressed through image gradients. However, existing dual-discriminator generative adversarial networks (GANs) often rely on two structurally identical discriminators for learning, which do not fully account for the distinct learning needs of infrared and visible image information. To this end, this paper proposes a novel GAN with a heterogeneous dual-discriminator network and an attention-based fusion strategy (GAN-HA). Specifically, recognizing the intrinsic differences between infrared and visible images, we propose, for the first time, a novel heterogeneous dual-discriminator network to simultaneously capture thermal radiation information and texture details. The two discriminators in this network are structurally different, including a salient discriminator for infrared images and a detailed discriminator for visible images. They are able to learn rich image intensity information and image gradient information, respectively. In addition, a new attention-based fusion strategy is designed in the generator to appropriately emphasize the learned information from different source images, thereby improving the information representation ability of the fusion result. In this way, the fused images generated by GAN-HA can more effectively maintain both the salience of thermal targets and the sharpness of textures. Extensive experiments on various public datasets demonstrate the superiority of GAN-HA over other state-of-the-art (SOTA) algorithms while showcasing its higher potential for practical applications.
Read more9/5/2024
0
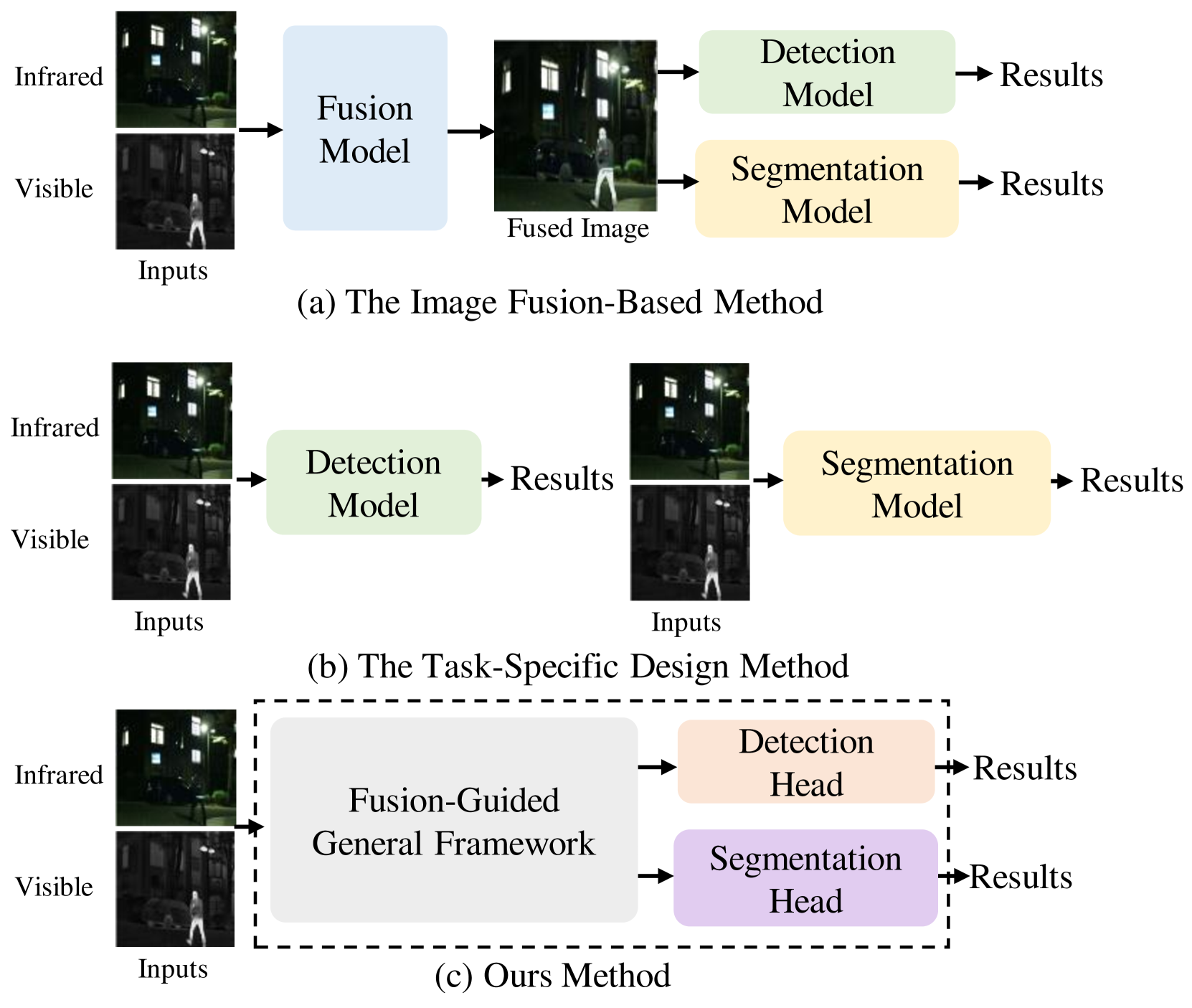
IVGF: The Fusion-Guided Infrared and Visible General Framework
Fangcen Liu, Chenqiang Gao, Fang Chen, Pengcheng Li, Junjie Guo, Deyu Meng
Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
Read more9/17/2024