Gated Low-rank Adaptation for personalized Code-Switching Automatic Speech Recognition on the low-spec devices

0
🗣️
Sign in to get full access
Overview
- Growing interest in using personalized large models on low-spec devices like mobile phones and CPUs
- On-device use of personalized large models is inefficient and limited due to computational cost
- Paper presents a weights separation method to minimize on-device model weights using parameter-efficient fine-tuning
- Addresses code-switching in speech recognition, where people use multiple languages in a single utterance
- Proposes code-switching speech recognition models that incorporate fine-tuned monolingual and multilingual models
- Introduces a Gated Low-Rank Adaptation (GLoRA) technique for parameter-efficient fine-tuning with minimal performance degradation
Plain English Explanation
Nowadays, there is growing interest in using personalized versions of large AI models on low-powered devices like smartphones and basic computers. However, running these personalized models directly on the device is often inefficient and limited by the device's computing power.
To address this problem, the researchers in this paper developed a "weights separation" method. This allows the personalized model to be broken down into smaller, more efficient parts that can run better on low-spec devices. The paper also tackles the challenge of "code-switching" in speech recognition, where people mix multiple languages in the same conversation.
Current speech recognition models can only handle one language per utterance, but the researchers created new models that can recognize multiple languages within the same spoken input. Additionally, they introduce a technique called "Gated Low-Rank Adaptation" (GLoRA) that enables these personalized speech models to be fine-tuned and adapted to individual users' needs, while using a minimal number of parameters to maintain good performance.
Technical Explanation
The paper presents a "weights separation" method to minimize the on-device model size for personalized large models. This involves using parameter-efficient fine-tuning techniques like keyword-guided adaptation and batched low-rank adaptation to reduce the number of model parameters required on the device.
To address code-switching in speech recognition, the researchers propose incorporating fine-tuned monolingual and multilingual speech recognition models into a single code-switching model. This allows the system to handle the mixing of multiple languages within a single utterance.
The paper also introduces a new technique called Gated Low-Rank Adaptation (GLoRA), which builds on prior work like ALORA and personalized collaborative fine-tuning. GLoRA enables parameter-efficient fine-tuning with minimal performance degradation, further improving the efficiency of the personalized speech recognition models.
Critical Analysis
The paper addresses important challenges in deploying personalized large models on low-spec devices and handling code-switching in speech recognition. The proposed weights separation method and GLoRA technique seem promising for improving the efficiency and performance of these personalized models.
However, the paper does not provide detailed analysis of the computational or memory requirements of the weights separation approach, which would be valuable for understanding its practical implications. Additionally, the evaluation is limited to a Korean-English code-switching dataset, so further research would be needed to understand how the techniques generalize to other language combinations and real-world scenarios.
It would also be helpful to see a more in-depth discussion of the potential limitations or failure modes of the code-switching speech recognition models, as well as any ethical considerations around deploying personalized AI systems that can handle multiple languages within a single conversation.
Conclusion
This paper presents novel techniques for enabling the use of personalized large AI models on low-powered devices, as well as for handling code-switching in speech recognition. The weights separation method and GLoRA fine-tuning approach show promise for improving the efficiency and performance of these personalized models, which could have significant implications for making advanced AI capabilities more accessible on a wide range of devices.
Overall, the research tackles important challenges at the intersection of personalization, model efficiency, and multilingual processing, and provides a foundation for further advancements in these areas.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Gated Low-rank Adaptation for personalized Code-Switching Automatic Speech Recognition on the low-spec devices
Gwantae Kim, Bokyeung Lee, Donghyeon Kim, Hanseok Ko
In recent times, there has been a growing interest in utilizing personalized large models on low-spec devices, such as mobile and CPU-only devices. However, utilizing a personalized large model in the on-device is inefficient, and sometimes limited due to computational cost. To tackle the problem, this paper presents the weights separation method to minimize on-device model weights using parameter-efficient fine-tuning methods. Moreover, some people speak multiple languages in an utterance, as known as code-switching, the personalized ASR model is necessary to address such cases. However, current multilingual speech recognition models are limited to recognizing a single language within each utterance. To tackle this problem, we propose code-switching speech recognition models that incorporate fine-tuned monolingual and multilingual speech recognition models. Additionally, we introduce a gated low-rank adaptation(GLoRA) for parameter-efficient fine-tuning with minimal performance degradation. Our experiments, conducted on Korean-English code-switching datasets, demonstrate that fine-tuning speech recognition models for code-switching surpasses the performance of traditional code-switching speech recognition models trained from scratch. Furthermore, GLoRA enhances parameter-efficient fine-tuning performance compared to conventional LoRA.
Read more6/6/2024

0
Listen Again and Choose the Right Answer: A New Paradigm for Automatic Speech Recognition with Large Language Models
Yuchen Hu, Chen Chen, Chengwei Qin, Qiushi Zhu, Eng Siong Chng, Ruizhe Li
Recent advances in large language models (LLMs) have promoted generative error correction (GER) for automatic speech recognition (ASR), which aims to predict the ground-truth transcription from the decoded N-best hypotheses. Thanks to the strong language generation ability of LLMs and rich information in the N-best list, GER shows great effectiveness in enhancing ASR results. However, it still suffers from two limitations: 1) LLMs are unaware of the source speech during GER, which may lead to results that are grammatically correct but violate the source speech content, 2) N-best hypotheses usually only vary in a few tokens, making it redundant to send all of them for GER, which could confuse LLM about which tokens to focus on and thus lead to increased miscorrection. In this paper, we propose ClozeGER, a new paradigm for ASR generative error correction. First, we introduce a multimodal LLM (i.e., SpeechGPT) to receive source speech as extra input to improve the fidelity of correction output. Then, we reformat GER as a cloze test with logits calibration to remove the input information redundancy and simplify GER with clear instructions. Experiments show that ClozeGER achieves a new breakthrough over vanilla GER on 9 popular ASR datasets.
Read more5/17/2024

0
Keyword-Guided Adaptation of Automatic Speech Recognition
Aviv Shamsian, Aviv Navon, Neta Glazer, Gill Hetz, Joseph Keshet
Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
Read more6/6/2024
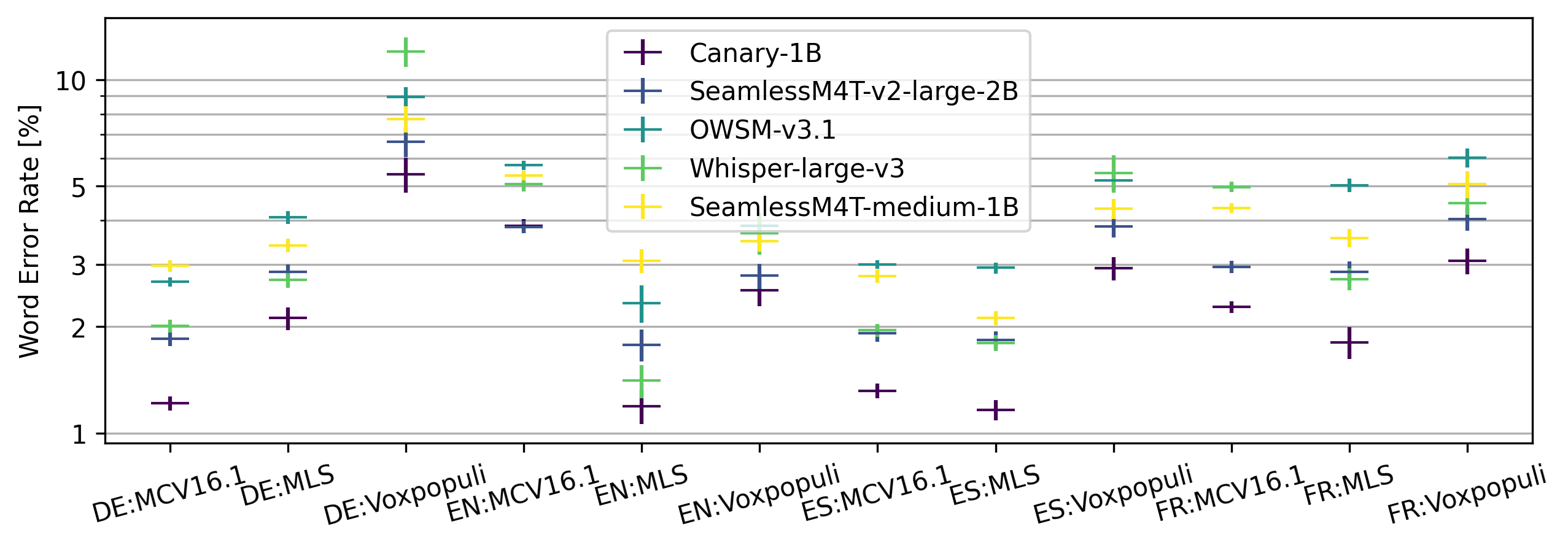
0
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Krishna C. Puvvada, Piotr .Zelasko, He Huang, Oleksii Hrinchuk, Nithin Rao Koluguri, Kunal Dhawan, Somshubra Majumdar, Elena Rastorgueva, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
Read more7/1/2024