Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
2406.19674
0
0
Abstract
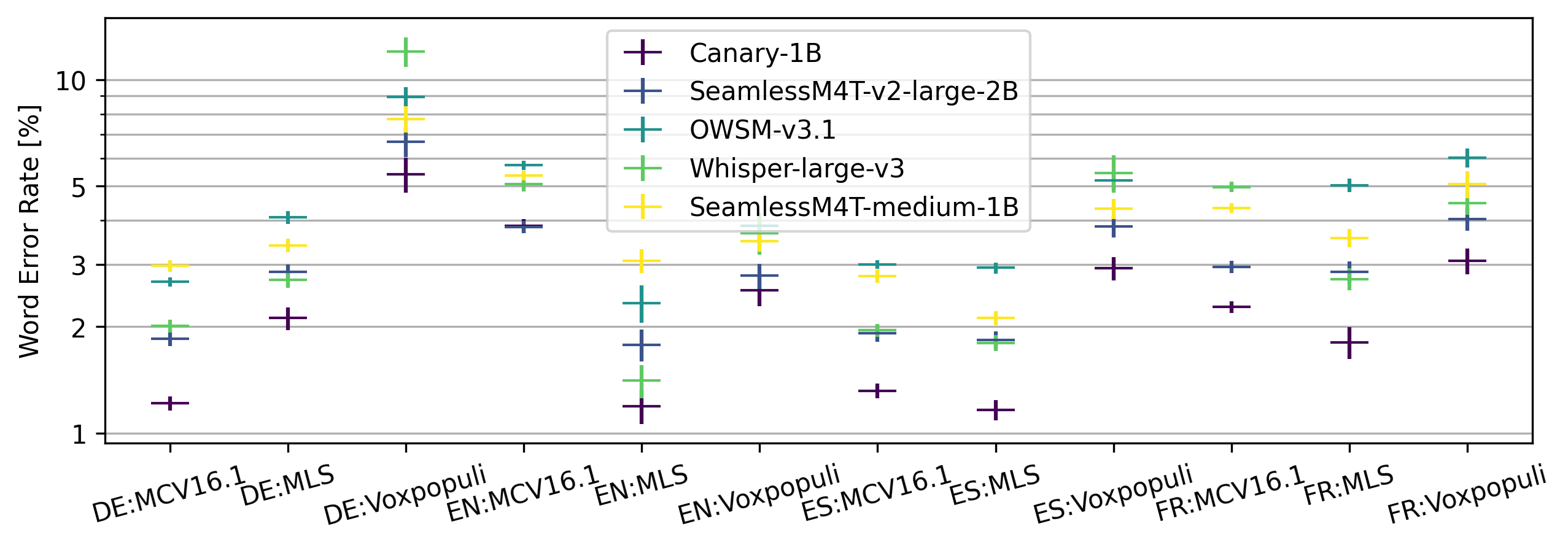
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
Create account to get full access
Overview
- This paper presents a novel approach to accurate speech recognition and translation without relying on large-scale web data.
- The authors demonstrate that their method can achieve state-of-the-art performance on various speech tasks while using significantly less training data compared to traditional methods.
- The paper explores techniques like efficient compression of multitask multilingual speech models, unsupervised speech recognition without pronunciation models, and keyword-guided adaptation for automatic speech recognition.
Plain English Explanation
The paper describes a new way to build speech recognition and translation systems that work well without needing huge amounts of training data from the internet. Traditional speech AI models often rely on collecting and processing massive datasets from the web, which can be costly and time-consuming.
Instead, the authors demonstrate techniques that allow their models to achieve accurate results using much less data. For example, they show how to efficiently compress multitask multilingual speech models to make them smaller and faster, while still maintaining high performance. They also explore unsupervised speech recognition without pronunciation models, which means the models can learn to transcribe speech without being given detailed information about how words are pronounced.
Additionally, the paper investigates keyword-guided adaptation for automatic speech recognition, where the models can be fine-tuned for specific tasks or languages by focusing on important words or phrases. This allows the models to be quickly adapted to new scenarios without requiring a complete retraining.
Overall, the key innovation in this work is the ability to build highly capable speech AI systems that don't depend on scouring the internet for massive training datasets. This could make speech technology more accessible and affordable, especially for lower-resource languages and specialized applications.
Technical Explanation
The paper proposes several techniques to reduce the data requirements for building accurate speech recognition and translation models:
-
Efficient compression of multitask multilingual speech models: The authors demonstrate methods to compress large, multilingual speech models while preserving their performance. This includes techniques like model pruning and knowledge distillation, which allow the models to be made smaller and faster without sacrificing accuracy.
-
Towards unsupervised speech recognition without pronunciation models: The paper explores unsupervised approaches to speech recognition that do not require detailed pronunciation dictionaries. Instead, the models can learn to transcribe speech directly from the audio data, without relying on predefined pronunciation rules.
-
Keyword-guided adaptation for automatic speech recognition: The authors show how speech recognition models can be quickly adapted to new domains or languages by fine-tuning on a small set of keywords or phrases, rather than requiring a full retraining on a large dataset.
The experiments in the paper demonstrate that these techniques can achieve state-of-the-art performance on a variety of speech tasks, including speech recognition and translation, while using significantly less training data than conventional approaches. This has important implications for making speech AI more accessible and deployable in resource-constrained settings.
Critical Analysis
The paper presents a compelling approach to reducing the data requirements for building high-performing speech recognition and translation models. The proposed techniques, such as model compression and unsupervised learning, are well-grounded in the literature and show promising results.
One potential limitation of the work is that it may not capture the full complexity of real-world speech scenarios, which often involve dealing with background noise, accents, and specialized vocabulary. The authors acknowledge this and suggest that further research is needed to extend the techniques to more challenging conditions.
Additionally, while the paper demonstrates the effectiveness of keyword-guided adaptation, it would be interesting to see how the models perform on more open-ended, unconstrained speech tasks. The ability to quickly adapt to new domains or languages is valuable, but the limits of this approach should be explored.
Overall, the research presented in this paper represents an important step towards making speech AI more accessible and practical, especially for low-resource settings or specialized applications. By reducing the reliance on massive web-scale datasets, the proposed methods have the potential to democratize speech technology and enable its deployment in a wider range of contexts.
Conclusion
This paper introduces innovative techniques to build accurate speech recognition and translation models without requiring large-scale web data. By leveraging methods like efficient model compression, unsupervised learning, and keyword-guided adaptation, the authors demonstrate that high-performing speech AI systems can be developed using significantly less training data than traditional approaches.
The implications of this work are significant, as it opens the door to making speech technology more accessible and deployable in a wider range of settings, including low-resource languages and specialized applications. The ability to build speech AI models with much less data could lead to cost savings, faster development cycles, and broader adoption of these transformative technologies.
While further research is needed to address the limitations and extend the techniques to more challenging speech scenarios, this paper represents an important step forward in the field of speech recognition and translation. By reducing the barriers to entry, the authors' work has the potential to accelerate the development and democratization of speech AI, with far-reaching benefits for individuals, organizations, and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
0
0
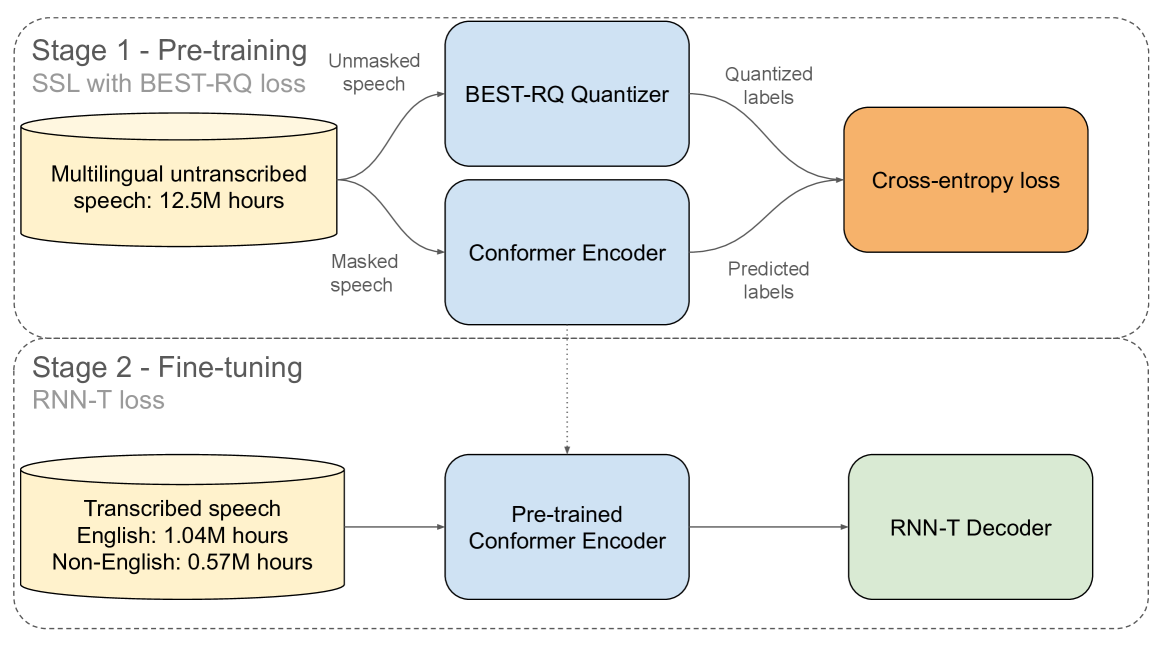
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
4/17/2024
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
0
0
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
5/3/2024
Towards Unsupervised Speech Recognition Without Pronunciation Models
Junrui Ni, Liming Wang, Yang Zhang, Kaizhi Qian, Heting Gao, Mark Hasegawa-Johnson, Chang D. Yoo
0
0
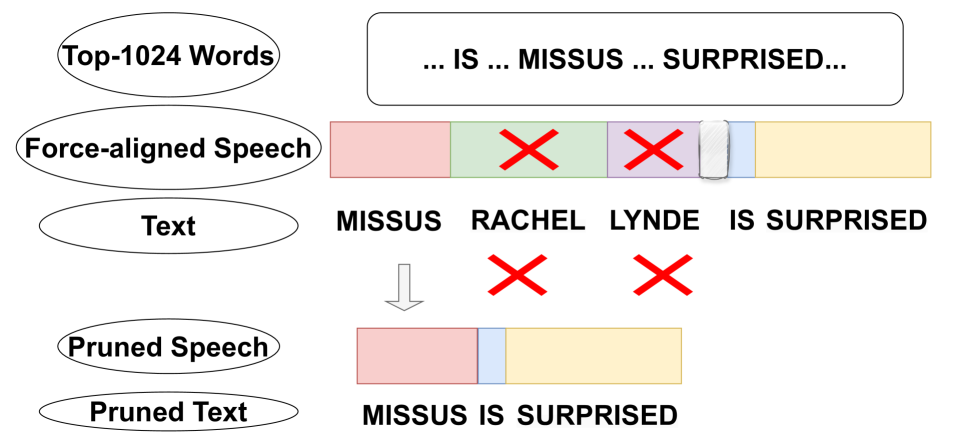
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
6/13/2024

LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR
Zheshu Song, Jianheng Zhuo, Yifan Yang, Ziyang Ma, Shixiong Zhang, Xie Chen
0
0
Recent years have witnessed significant progress in multilingual automatic speech recognition (ASR), driven by the emergence of end-to-end (E2E) models and the scaling of multilingual datasets. Despite that, two main challenges persist in multilingual ASR: language interference and the incorporation of new languages without degrading the performance of the existing ones. This paper proposes LoRA-Whisper, which incorporates LoRA matrix into Whisper for multilingual ASR, effectively mitigating language interference. Furthermore, by leveraging LoRA and the similarities between languages, we can achieve better performance on new languages while upholding consistent performance on original ones. Experiments on a real-world task across eight languages demonstrate that our proposed LoRA-Whisper yields a relative gain of 18.5% and 23.0% over the baseline system for multilingual ASR and language expansion respectively.
6/12/2024