Strategizing against Q-learners: A Control-theoretical Approach
2403.08906
0
0

Abstract
In this paper, we explore the susceptibility of the independent Q-learning algorithms (a classical and widely used multi-agent reinforcement learning method) to strategic manipulation of sophisticated opponents in normal-form games played repeatedly. We quantify how much strategically sophisticated agents can exploit naive Q-learners if they know the opponents' Q-learning algorithm. To this end, we formulate the strategic actors' interactions as a stochastic game (whose state encompasses Q-function estimates of the Q-learners) as if the Q-learning algorithms are the underlying dynamical system. We also present a quantization-based approximation scheme to tackle the continuum state space and analyze its performance for two competing strategic actors and a single strategic actor both analytically and numerically.
Create account to get full access
Overview
- This research paper examines a strategic approach for agents to gain an advantage over Q-learning agents.
- The authors propose a control-theoretical framework that allows strategic agents to model and counter the behavior of Q-learning agents.
- The paper explores various strategies and analyzes their effectiveness in different game scenarios.
Plain English Explanation
In many real-world situations, we encounter agents or entities that use reinforcement learning, specifically Q-learning, to make decisions and learn optimal behaviors. The paper "Learning under Imitative Strategic Behavior: Unforeseeable Outcomes" discusses this in more detail.
The authors of this paper recognize that in these situations, there may be strategic actors who want to gain an advantage over the Q-learning agents. To achieve this, the researchers develop a control-theoretical approach that allows strategic agents to model and predict the behavior of Q-learning agents. This is similar to the ideas explored in the paper "Zero-Sum Positional Differential Games as a Framework".
By understanding how Q-learners operate and make decisions, the strategic agents can then devise countermeasures and strategies to outmaneuver them. This might involve anticipating the Q-learner's moves, shaping the environment to their advantage, or even directly influencing the Q-learner's learning process.
The paper explores various strategies and analyzes their effectiveness in different game scenarios, providing insights into how strategic actors can gain an edge over Q-learning agents. This research could have implications for areas like multi-agent systems, game theory, and even real-world decision-making scenarios where Q-learning is used.
Technical Explanation
The paper presents a control-theoretical framework for strategic agents to model and counter the behavior of Q-learning agents. The authors introduce the concept of a "strategic actor" who aims to gain an advantage over Q-learners by leveraging their understanding of the Q-learning process.
The researchers develop a model that allows strategic agents to predict the Q-learner's behavior and devise appropriate countermeasures. This involves analyzing the Q-learner's value function and updating their own actions accordingly to influence the Q-learner's learning and decision-making.
Through various game scenarios and simulations, the paper explores different strategies that strategic agents can employ, such as the approach discussed in "LOQA: Learning Opponent Q-learning Awareness" or the ideas presented in "Non-linear Welfare-Aware Strategic Learning". The authors evaluate the effectiveness of these strategies in terms of the strategic agent's ability to outperform the Q-learner and achieve their desired outcomes.
The paper also addresses the limitations of the proposed framework, such as the assumptions made about the Q-learner's behavior and the potential challenges in implementing the strategies in real-world settings. The authors acknowledge the need for further research to refine the approach and explore its applicability in more complex multi-agent scenarios.
Critical Analysis
The paper presents a novel and interesting approach to strategizing against Q-learning agents, but it also raises several important considerations:
-
Assumptions about Q-learners: The framework assumes that the strategic agent has a good understanding of the Q-learning process and can accurately model the Q-learner's behavior. In reality, Q-learners may exhibit more complex or unpredictable behaviors, especially in dynamic environments.
-
Generalizability: The paper focuses on specific game scenarios and may not fully capture the nuances of real-world multi-agent systems, where the interactions and incentives can be more complex. Further research is needed to assess the broader applicability of the proposed strategies.
-
Ethical implications: While the paper presents a technical solution, it raises questions about the ethical considerations of strategic agents actively seeking to undermine the decision-making of Q-learning agents. The potential for exploitation or unintended consequences should be carefully examined.
-
Robustness and adaptability: The proposed strategies may be effective in specific scenarios, but it is unclear how they would perform against more sophisticated Q-learners or in the face of changes in the environment or the Q-learner's behavior over time.
Despite these limitations, the paper provides a valuable contribution to the field by introducing a control-theoretical approach to strategizing against Q-learning agents. The insights and frameworks presented can serve as a foundation for further research and development in this area.
Conclusion
This research paper presents a control-theoretical framework for strategic agents to model and counter the behavior of Q-learning agents. By understanding the Q-learning process, the strategic agents can devise various strategies to gain an advantage over the Q-learners.
The paper explores different strategies and analyzes their effectiveness in various game scenarios. While the proposed approach shows promise, it also raises important considerations around the assumptions, generalizability, ethical implications, and robustness of the strategies.
Overall, this work contributes to the broader understanding of multi-agent interactions and decision-making, particularly in scenarios where traditional reinforcement learning agents coexist with strategic actors. The insights and frameworks presented in the paper can serve as a foundation for further research and development in this area, with the potential to impact fields such as game theory, multi-agent systems, and real-world decision-making scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A General Control-Theoretic Approach for Reinforcement Learning: Theory and Algorithms
Weiqin Chen, Mark S. Squillante, Chai Wah Wu, Santiago Paternain
0
0
We devise a control-theoretic reinforcement learning approach to support direct learning of the optimal policy. We establish theoretical properties of our approach and derive an algorithm based on a specific instance of this approach. Our empirical results demonstrate the significant benefits of our approach.
6/24/2024
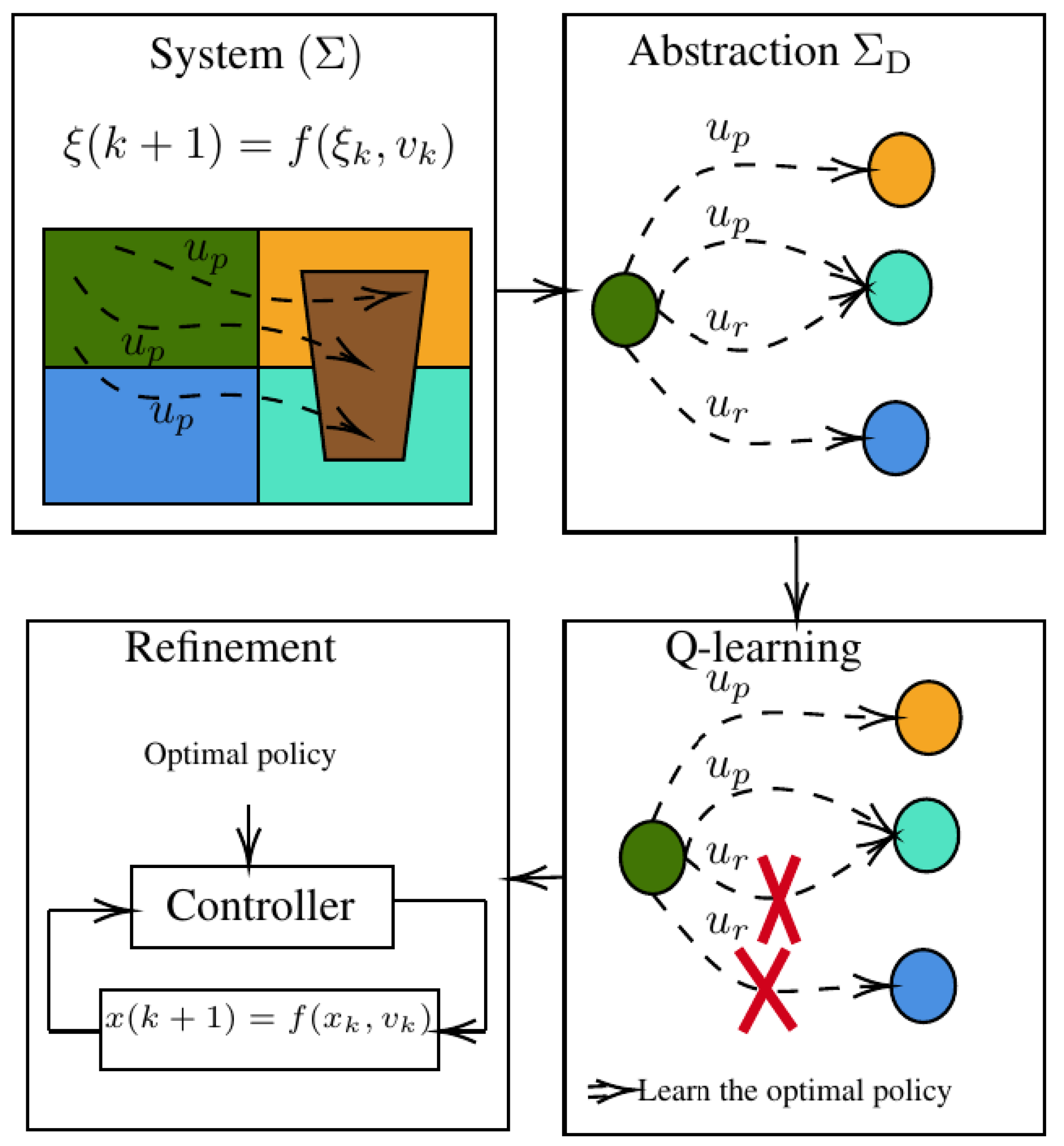
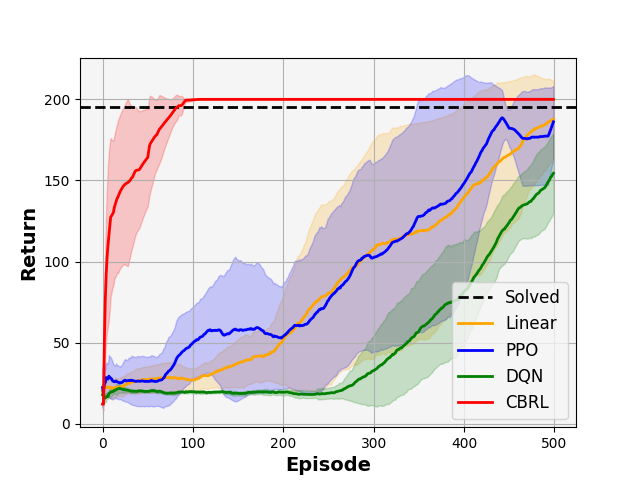
How to discretize continuous state-action spaces in Q-learning: A symbolic control approach
Sadek Belamfedel Alaoui, Adnane Saoud
0
0
Q-learning is widely recognized as an effective approach for synthesizing controllers to achieve specific goals. However, handling challenges posed by continuous state-action spaces remains an ongoing research focus. This paper presents a systematic analysis that highlights a major drawback in space discretization methods. To address this challenge, the paper proposes a symbolic model that represents behavioral relations, such as alternating simulation from abstraction to the controlled system. This relation allows for seamless application of the synthesized controller based on abstraction to the original system. Introducing a novel Q-learning technique for symbolic models, the algorithm yields two Q-tables encoding optimal policies. Theoretical analysis demonstrates that these Q-tables serve as both upper and lower bounds on the Q-values of the original system with continuous spaces. Additionally, the paper explores the correlation between the parameters of the space abstraction and the loss in Q-values. The resulting algorithm facilitates achieving optimality within an arbitrary accuracy, providing control over the trade-off between accuracy and computational complexity. The obtained results provide valuable insights for selecting appropriate learning parameters and refining the controller. The engineering relevance of the proposed Q-learning based symbolic model is illustrated through two case studies.
6/7/2024

LOQA: Learning with Opponent Q-Learning Awareness
Milad Aghajohari, Juan Agustin Duque, Tim Cooijmans, Aaron Courville
0
0
In various real-world scenarios, interactions among agents often resemble the dynamics of general-sum games, where each agent strives to optimize its own utility. Despite the ubiquitous relevance of such settings, decentralized machine learning algorithms have struggled to find equilibria that maximize individual utility while preserving social welfare. In this paper we introduce Learning with Opponent Q-Learning Awareness (LOQA), a novel, decentralized reinforcement learning algorithm tailored to optimizing an agent's individual utility while fostering cooperation among adversaries in partially competitive environments. LOQA assumes the opponent samples actions proportionally to their action-value function Q. Experimental results demonstrate the effectiveness of LOQA at achieving state-of-the-art performance in benchmark scenarios such as the Iterated Prisoner's Dilemma and the Coin Game. LOQA achieves these outcomes with a significantly reduced computational footprint, making it a promising approach for practical multi-agent applications.
5/3/2024

Reinforcement Learning for High-Level Strategic Control in Tower Defense Games
Joakim Bergdahl, Alessandro Sestini, Linus Gissl'en
0
0
In strategy games, one of the most important aspects of game design is maintaining a sense of challenge for players. Many mobile titles feature quick gameplay loops that allow players to progress steadily, requiring an abundance of levels and puzzles to prevent them from reaching the end too quickly. As with any content creation, testing and validation are essential to ensure engaging gameplay mechanics, enjoyable game assets, and playable levels. In this paper, we propose an automated approach that can be leveraged for gameplay testing and validation that combines traditional scripted methods with reinforcement learning, reaping the benefits of both approaches while adapting to new situations similarly to how a human player would. We test our solution on a popular tower defense game, Plants vs. Zombies. The results show that combining a learned approach, such as reinforcement learning, with a scripted AI produces a higher-performing and more robust agent than using only heuristic AI, achieving a 57.12% success rate compared to 47.95% in a set of 40 levels. Moreover, the results demonstrate the difficulty of training a general agent for this type of puzzle-like game.
6/13/2024