Towards a theory of out-of-distribution learning
2109.14501
0
0
🏋️
Abstract
Learning is a process wherein a learning agent enhances its performance through exposure of experience or data. Throughout this journey, the agent may encounter diverse learning environments. For example, data may be presented to the leaner all at once, in multiple batches, or sequentially. Furthermore, the distribution of each data sample could be either identical and independent (iid) or non-iid. Additionally, there may exist computational and space constraints for the deployment of the learning algorithms. The complexity of a learning task can vary significantly, depending on the learning setup and the constraints imposed upon it. However, it is worth noting that the current literature lacks formal definitions for many of the in-distribution and out-of-distribution learning paradigms. Establishing proper and universally agreed-upon definitions for these learning setups is essential for thoroughly exploring the evolution of ideas across different learning scenarios and deriving generalized mathematical bounds for these learners. In this paper, we aim to address this issue by proposing a chronological approach to defining different learning tasks using the provably approximately correct (PAC) learning framework. We will start with in-distribution learning and progress to recently proposed lifelong or continual learning. We employ consistent terminology and notation to demonstrate how each of these learning frameworks represents a specific instance of a broader, more generalized concept of learnability. Our hope is that this work will inspire a universally agreed-upon approach to quantifying different types of learning, fostering greater understanding and progress in the field.
Create account to get full access
Overview
- Explores the evolution of learning scenarios, from in-distribution to continual learning
- Proposes a chronological approach to defining different learning tasks using the PAC learning framework
- Aims to establish a universally agreed-upon approach to quantifying various types of learning
Plain English Explanation
Learning is a process where an agent, such as a machine learning model, improves its performance by exposure to data or experience. The learning environment can vary, with data presented all at once, in batches, or sequentially. The data distribution can also be identical and independent (iid) or non-iid. Additionally, there may be computational and space constraints for deploying the learning algorithms.
The complexity of a learning task can vary significantly depending on the setup and constraints. However, the current literature lacks formal definitions for many of the in-distribution and out-of-distribution learning paradigms. Establishing proper and universally agreed-upon definitions for these learning setups is essential for thoroughly exploring the evolution of ideas across different learning scenarios and deriving generalized mathematical bounds for these learners.
This paper aims to address this issue by proposing a chronological approach to defining different learning tasks using the provably approximately correct (PAC) learning framework. The authors start with in-distribution learning and progress to recently proposed lifelong or continual learning. They employ consistent terminology and notation to demonstrate how each of these learning frameworks represents a specific instance of a broader, more generalized concept of learnability.
Technical Explanation
The paper proposes a chronological approach to defining different learning tasks using the PAC learning framework. The authors start with in-distribution learning, where the data distribution is assumed to be identical and independent (iid), and progress to more complex scenarios, such as out-of-distribution detection and continual learning, where the data distribution may change over time or vary across tasks.
The authors employ consistent terminology and notation to demonstrate how each of these learning frameworks represents a specific instance of a broader, more generalized concept of learnability. By establishing a unified approach to quantifying different types of learning, the paper aims to foster greater understanding and progress in the field, enabling researchers to explore the evolution of ideas across various learning scenarios and derive generalized mathematical bounds for these learners.
Critical Analysis
The paper's main contribution is its attempt to establish a universally agreed-upon approach to defining and quantifying different types of learning tasks. This is an important step in advancing the field, as the lack of formal definitions has hindered the ability to compare and build upon research in various learning paradigms.
However, the paper does not provide a complete solution, as it acknowledges that the current literature lacks formal definitions for many in-distribution and out-of-distribution learning paradigms. The authors' proposed chronological approach using the PAC learning framework is a step in the right direction, but there may be other ways to formalize these concepts that warrant further exploration.
Additionally, the paper does not address the practical challenges of implementing these learning frameworks, such as the computational and memory constraints that may arise in real-world applications. Further research is needed to understand how these theoretical frameworks can be effectively applied in practice, especially in the context of continual learning and other complex learning scenarios.
Conclusion
This paper proposes a chronological approach to defining different learning tasks using the PAC learning framework, with the goal of establishing a universally agreed-upon approach to quantifying various types of learning. By employing consistent terminology and notation, the authors aim to foster greater understanding and progress in the field, enabling researchers to explore the evolution of ideas across diverse learning scenarios and derive generalized mathematical bounds for these learners.
While the paper does not provide a complete solution, it represents an important step towards formalizing the concepts of in-distribution and out-of-distribution learning paradigms. Further research is needed to address the practical challenges of implementing these theoretical frameworks, as well as to explore alternative approaches to defining and quantifying different types of learning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
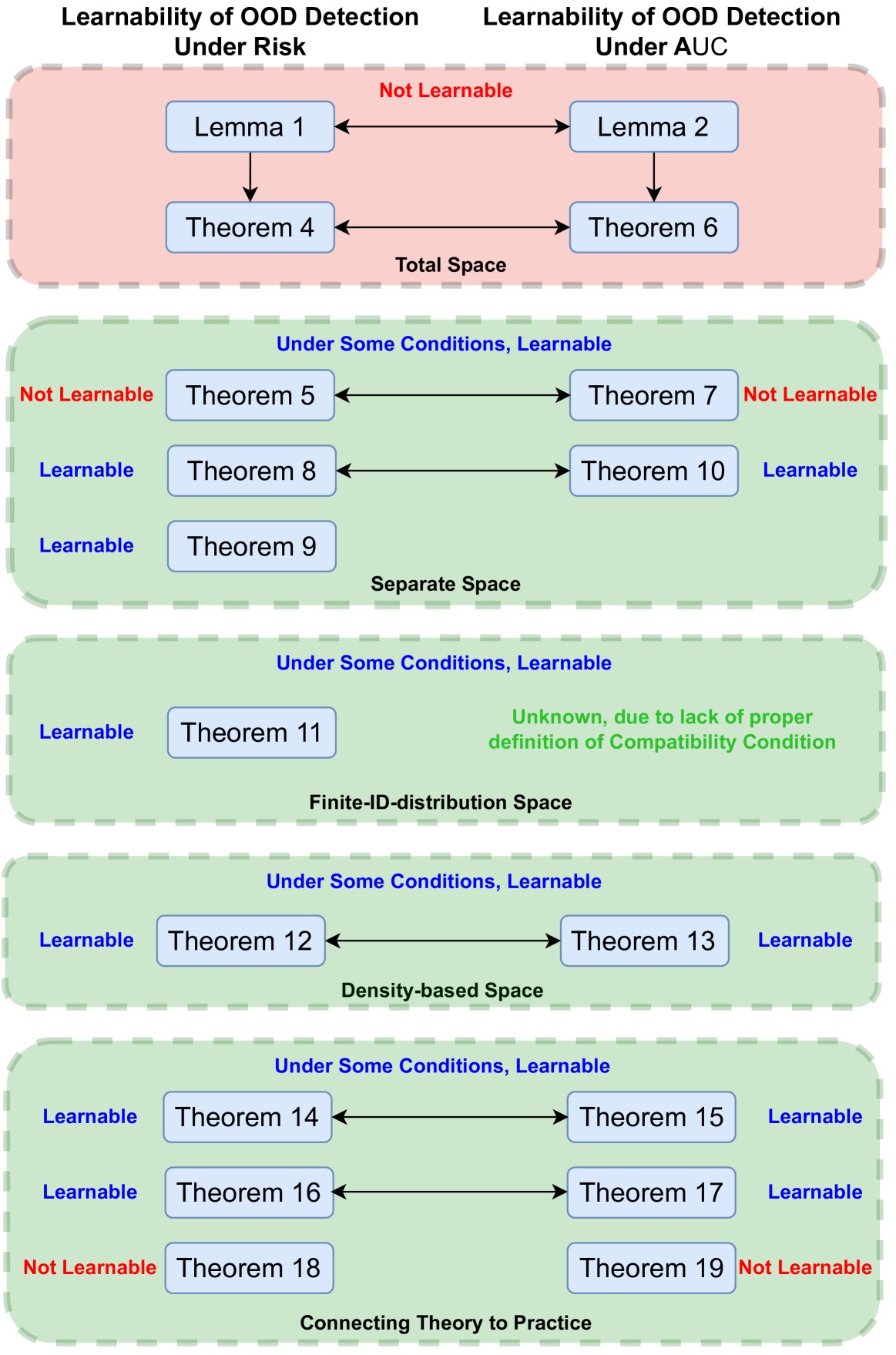
On the Learnability of Out-of-distribution Detection
Zhen Fang, Yixuan Li, Feng Liu, Bo Han, Jie Lu
0
0
Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms, and corresponding learning theory is still an open problem. To study the generalization of OOD detection, this paper investigates the probably approximately correct (PAC) learning theory of OOD detection that fits the commonly used evaluation metrics in the literature. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we offer theoretical support for representative OOD detection works based on our OOD theory.
4/9/2024
General Distribution Learning: A theoretical framework for Deep Learning
Binchuan Qi, Li Li, Wei Gong
0
0
There remain numerous unanswered research questions on deep learning (DL) within the classical learning theory framework. These include the remarkable generalization capabilities of overparametrized neural networks (NNs), the efficient optimization performance despite non-convexity of objectives, the mechanism of flat minima for generalization, and the exceptional performance of deep architectures in solving physical problems. This paper introduces General Distribution Learning (GD Learning), a novel theoretical learning framework designed to address a comprehensive range of machine learning and statistical tasks, including classification, regression and parameter estimation. Departing from traditional statistical machine learning, GD Learning focuses on the true underlying distribution. In GD Learning, learning error, corresponding to the expected error in classical statistical learning framework, is divided into fitting errors due to models and algorithms, as well as sampling errors introduced by limited sampling data. The framework significantly incorporates prior knowledge, especially in scenarios characterized by data scarcity, thereby enhancing performance. Within the GD Learning framework, we demonstrate that the global optimal solutions in non-convex optimization can be approached by minimizing the gradient norm and the non-uniformity of the eigenvalues of the model's Jacobian matrix. This insight leads to the development of the gradient structure control algorithm. GD Learning also offers fresh insights into the questions on deep learning, including overparameterization and non-convex optimization, bias-variance trade-off, and the mechanism of flat minima.
6/19/2024
Distributed Continual Learning
Long Le, Marcel Hussing, Eric Eaton
0
0
This work studies the intersection of continual and federated learning, in which independent agents face unique tasks in their environments and incrementally develop and share knowledge. We introduce a mathematical framework capturing the essential aspects of distributed continual learning, including agent model and statistical heterogeneity, continual distribution shift, network topology, and communication constraints. Operating on the thesis that distributed continual learning enhances individual agent performance over single-agent learning, we identify three modes of information exchange: data instances, full model parameters, and modular (partial) model parameters. We develop algorithms for each sharing mode and conduct extensive empirical investigations across various datasets, topology structures, and communication limits. Our findings reveal three key insights: sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.
5/29/2024
🧪
A View on Out-of-Distribution Identification from a Statistical Testing Theory Perspective
Alberto Caron, Chris Hicks, Vasilios Mavroudis
0
0
We study the problem of efficiently detecting Out-of-Distribution (OOD) samples at test time in supervised and unsupervised learning contexts. While ML models are typically trained under the assumption that training and test data stem from the same distribution, this is often not the case in realistic settings, thus reliably detecting distribution shifts is crucial at deployment. We re-formulate the OOD problem under the lenses of statistical testing and then discuss conditions that render the OOD problem identifiable in statistical terms. Building on this framework, we study convergence guarantees of an OOD test based on the Wasserstein distance, and provide a simple empirical evaluation.
5/13/2024