Generalizable Facial Expression Recognition

0

Sign in to get full access
Overview
- The research paper explores techniques for improving the generalization of facial expression recognition models to unseen data.
- Key ideas include using mask learning and zero-shot learning approaches to enable models to recognize expressions across diverse datasets and real-world conditions.
- The paper presents experimental results demonstrating the effectiveness of the proposed methods in boosting the performance of facial expression recognition in challenging, cross-domain settings.
Plain English Explanation
The research paper focuses on the challenge of facial expression recognition, which is the task of automatically identifying the emotional state of a person based on their facial features. While existing facial expression recognition models can work well on standardized datasets, they often struggle to generalize to real-world situations with diverse faces, lighting conditions, occlusions, and other variations.
To address this, the researchers explored two key techniques:
-
Mask learning: This involves training the model to focus on the most informative facial regions for expression recognition, rather than trying to process the entire face. By learning which parts of the face are most relevant, the model can become more robust to factors like occlusions or changes in facial features.
-
Zero-shot learning: This approach allows the model to recognize facial expressions that it has not been explicitly trained on. By leveraging semantic information about the different expressions, the model can learn to generalize its understanding to new, unseen types of expressions.
By combining these mask learning and zero-shot learning techniques, the researchers were able to develop facial expression recognition models that performed significantly better than existing approaches when tested on diverse, real-world datasets. This suggests that these methods could be valuable for building more practical and widely applicable facial expression recognition systems.
Technical Explanation
The paper presents a novel framework for generalizable facial expression recognition that incorporates two key components:
-
Mask Learning: The researchers introduced a mask learning module that learns to focus the model's attention on the most informative facial regions for expression recognition. This is achieved by training the model to predict a spatial attention mask that highlights the most relevant areas of the face. By selectively processing the important facial features, the model can become more robust to occlusions, variations in facial structure, and other real-world challenges.
-
Zero-Shot Learning: To enable the model to recognize expressions that it has not been explicitly trained on, the researchers employed a zero-shot learning approach. This involves learning a shared semantic embedding space that represents the relationships between different facial expressions. The model can then use this knowledge to generalize its expression recognition capabilities to new, unseen expression classes.
The researchers evaluated their S-Adapter framework on several challenging facial expression recognition datasets, including cross-dataset and cross-domain settings. The results demonstrated significant performance improvements over existing state-of-the-art methods, highlighting the effectiveness of the mask learning and zero-shot learning components in enabling more generalizable facial expression recognition.
Critical Analysis
The research paper presents a compelling approach to improving the generalization capabilities of facial expression recognition models. The use of mask learning to focus on the most informative facial regions is a clever way to increase robustness to real-world variations, while the zero-shot learning component allows the model to recognize a wider range of expressions without requiring exhaustive training data.
However, the paper does not fully address the potential limitations of these techniques. For example, the mask learning approach may struggle with highly occluded or partially obscured faces, where the relevant facial features are not easily discernible. Additionally, the zero-shot learning component relies on the availability of semantic information about the expression classes, which may not always be easy to obtain or represent accurately.
Further research could explore ways to adapt these techniques to more diverse facial expression datasets and real-world scenarios, such as incorporating more advanced computer vision and natural language processing methods to enhance the mask learning and zero-shot learning capabilities.
Conclusion
The research paper presents a promising approach to improving the generalization of facial expression recognition models, leveraging mask learning and zero-shot learning techniques. By focusing on the most informative facial regions and leveraging semantic knowledge about expressions, the proposed framework demonstrates significant performance gains over existing methods, particularly in challenging, cross-domain settings.
While the paper offers valuable insights, further research is needed to explore the limitations and potential extensions of these techniques to make facial expression recognition more robust and widely applicable in real-world applications. Nonetheless, this work represents an important step forward in the development of more generalizable facial expression recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalizable Facial Expression Recognition
Yuhang Zhang, Xiuqi Zheng, Chenyi Liang, Jiani Hu, Weihong Deng
SOTA facial expression recognition (FER) methods fail on test sets that have domain gaps with the train set. Recent domain adaptation FER methods need to acquire labeled or unlabeled samples of target domains to fine-tune the FER model, which might be infeasible in real-world deployment. In this paper, we aim to improve the zero-shot generalization ability of FER methods on different unseen test sets using only one train set. Inspired by how humans first detect faces and then select expression features, we propose a novel FER pipeline to extract expression-related features from any given face images. Our method is based on the generalizable face features extracted by large models like CLIP. However, it is non-trivial to adapt the general features of CLIP for specific tasks like FER. To preserve the generalization ability of CLIP and the high precision of the FER model, we design a novel approach that learns sigmoid masks based on the fixed CLIP face features to extract expression features. To further improve the generalization ability on unseen test sets, we separate the channels of the learned masked features according to the expression classes to directly generate logits and avoid using the FC layer to reduce overfitting. We also introduce a channel-diverse loss to make the learned masks separated. Extensive experiments on five different FER datasets verify that our method outperforms SOTA FER methods by large margins. Code is available in https://github.com/zyh-uaiaaaa/Generalizable-FER.
Read more8/21/2024
0
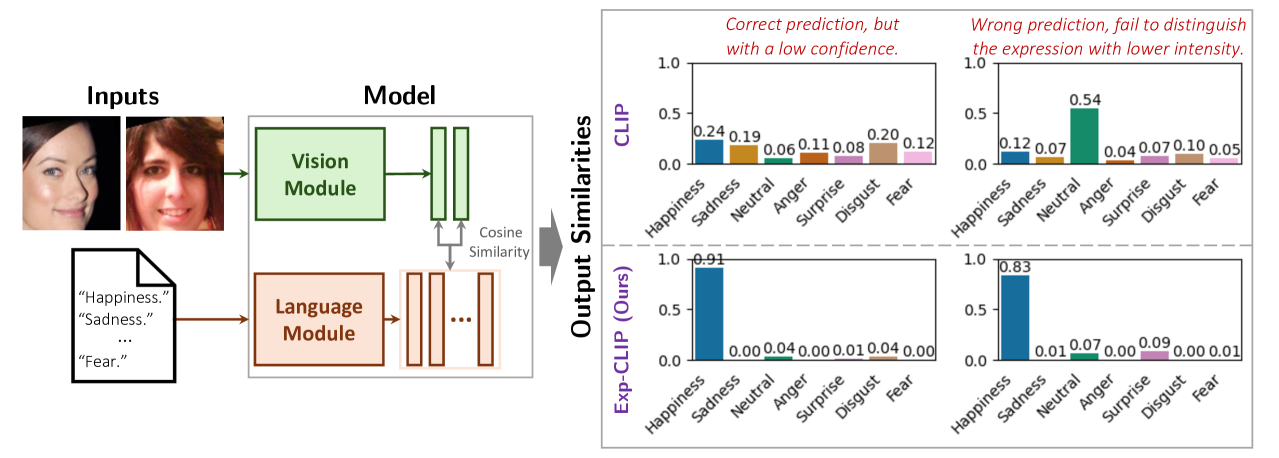
Enhancing Zero-Shot Facial Expression Recognition by LLM Knowledge Transfer
Zengqun Zhao, Yu Cao, Shaogang Gong, Ioannis Patras
Current facial expression recognition (FER) models are often designed in a supervised learning manner and thus are constrained by the lack of large-scale facial expression images with high-quality annotations. Consequently, these models often fail to generalize well, performing poorly on unseen images in inference. Vision-language-based zero-shot models demonstrate a promising potential for addressing such challenges. However, these models lack task-specific knowledge and therefore are not optimized for the nuances of recognizing facial expressions. To bridge this gap, this work proposes a novel method, Exp-CLIP, to enhance zero-shot FER by transferring the task knowledge from large language models (LLMs). Specifically, based on the pre-trained vision-language encoders, we incorporate a projection head designed to map the initial joint vision-language space into a space that captures representations of facial actions. To train this projection head for subsequent zero-shot predictions, we propose to align the projected visual representations with task-specific semantic meanings derived from the LLM encoder, and the text instruction-based strategy is employed to customize the LLM knowledge. Given unlabelled facial data and efficient training of the projection head, Exp-CLIP achieves superior zero-shot results to the CLIP models and several other large vision-language models (LVLMs) on seven in-the-wild FER datasets.
Read more6/19/2024
🖼️
0
Interpretable Image Emotion Recognition: A Domain Adaptation Approach Using Facial Expressions
Puneet Kumar, Balasubramanian Raman
This paper proposes a feature-based domain adaptation technique for identifying emotions in generic images, encompassing both facial and non-facial objects, as well as non-human components. This approach addresses the challenge of the limited availability of pre-trained models and well-annotated datasets for Image Emotion Recognition (IER). Initially, a deep-learning-based Facial Expression Recognition (FER) system is developed, classifying facial images into discrete emotion classes. Maintaining the same network architecture, this FER system is then adapted to recognize emotions in generic images through the application of discrepancy loss, enabling the model to effectively learn IER features while classifying emotions into categories such as 'happy,' 'sad,' 'hate,' and 'anger.' Additionally, a novel interpretability method, Divide and Conquer based Shap (DnCShap), is introduced to elucidate the visual features most relevant for emotion recognition. The proposed IER system demonstrated emotion classification accuracies of 60.98% for the IAPSa dataset, 58.86% for the ArtPhoto dataset, 69.13% for the FI dataset, and 58.06% for the EMOTIC dataset. The system effectively identifies the important visual features leading to specific emotion classifications and provides detailed embedding plots to explain the predictions, enhancing the understanding and trust in AI-driven emotion recognition systems.
Read more8/30/2024
👁️
0
Learning with Alignments: Tackling the Inter- and Intra-domain Shifts for Cross-multidomain Facial Expression Recognition
Yuxiang Yang, Lu Wen, Xinyi Zeng, Yuanyuan Xu, Xi Wu, Jiliu Zhou, Yan Wang
Facial Expression Recognition (FER) holds significant importance in human-computer interactions. Existing cross-domain FER methods often transfer knowledge solely from a single labeled source domain to an unlabeled target domain, neglecting the comprehensive information across multiple sources. Nevertheless, cross-multidomain FER (CMFER) is very challenging for (i) the inherent inter-domain shifts across multiple domains and (ii) the intra-domain shifts stemming from the ambiguous expressions and low inter-class distinctions. In this paper, we propose a novel Learning with Alignments CMFER framework, named LA-CMFER, to handle both inter- and intra-domain shifts. Specifically, LA-CMFER is constructed with a global branch and a local branch to extract features from the full images and local subtle expressions, respectively. Based on this, LA-CMFER presents a dual-level inter-domain alignment method to force the model to prioritize hard-to-align samples in knowledge transfer at a sample level while gradually generating a well-clustered feature space with the guidance of class attributes at a cluster level, thus narrowing the inter-domain shifts. To address the intra-domain shifts, LA-CMFER introduces a multi-view intra-domain alignment method with a multi-view clustering consistency constraint where a prediction similarity matrix is built to pursue consistency between the global and local views, thus refining pseudo labels and eliminating latent noise. Extensive experiments on six benchmark datasets have validated the superiority of our LA-CMFER.
Read more7/31/2024