Enhancing Zero-Shot Facial Expression Recognition by LLM Knowledge Transfer

0
Sign in to get full access
Overview
- This research paper explores a novel approach to enhancing zero-shot facial expression recognition using knowledge transfer from large language models (LLMs).
- The key idea is to leverage the rich semantic and commonsense knowledge captured by LLMs to improve the performance of facial expression recognition models in zero-shot settings, where the model needs to recognize expressions it has not been explicitly trained on.
- The proposed method involves a contrastive learning framework that aligns the facial expression representations with the corresponding semantic representations from LLMs.
Plain English Explanation
Recognizing facial expressions, such as happiness, sadness, or anger, is an important task in computer vision. However, training a model to recognize a wide range of expressions can be challenging, as it requires a lot of labeled data for each expression.
This research paper explores a way to address this problem using large language models (LLMs) like GPT-3. LLMs are powerful AI systems that have been trained on vast amounts of text data and can understand the meaning and relationships between different concepts.
The researchers hypothesized that the knowledge captured by LLMs could be used to help facial expression recognition models recognize expressions they haven't been explicitly trained on. They developed a method that aligns the facial expression representations with the corresponding semantic representations from LLMs using a technique called contrastive learning.
Essentially, the model is trained to recognize the connections between facial expressions and the language used to describe them. This allows the model to leverage the rich knowledge and understanding of expressions that LLMs have acquired from processing large amounts of text data.
This approach can be particularly useful in situations where there is limited labeled data for certain facial expressions, as the model can still recognize those expressions by drawing on the knowledge transferred from the LLM.
Technical Explanation
The key technical elements of the proposed approach are:
-
Contrastive Learning Framework: The researchers developed a contrastive learning framework that aligns the facial expression representations with the corresponding semantic representations from LLMs. This allows the model to learn the connections between facial expressions and the language used to describe them.
-
LLM Knowledge Transfer: The researchers leverage the rich semantic and commonsense knowledge captured by LLMs, such as GPT-3, to enhance the facial expression recognition model's performance in zero-shot settings.
-
Facial Expression Representation: The model learns a joint representation of facial expressions by processing the input images through a convolutional neural network (CNN) backbone, which is then aligned with the semantic representations from the LLM.
-
Cross-Modal Contrastive Loss: The researchers use a cross-modal contrastive loss function to ensure that the facial expression and semantic representations are well-aligned, allowing the model to leverage the knowledge from the LLM.
The experiments conducted in the paper demonstrate that the proposed approach outperforms state-of-the-art zero-shot facial expression recognition methods on several benchmark datasets. The researchers also show that the transferred knowledge from the LLM is particularly beneficial when the target domain has limited training data.
Critical Analysis
One of the key strengths of this research is the innovative use of LLMs to enhance the performance of facial expression recognition models in zero-shot settings. By aligning the facial expression representations with the semantic representations from LLMs, the model can effectively leverage the rich knowledge and understanding of expressions captured by these large language models.
However, the paper does not address some potential limitations and areas for further research:
-
Generalization to Other Domains: The evaluation of the proposed approach is primarily focused on facial expression recognition tasks. It would be interesting to see how well the method could transfer to other zero-shot learning problems, such as zero-shot video captioning or zero-shot concept generation in dermatology.
-
Interpretability and Explainability: The paper does not provide much insight into how the model is actually leveraging the knowledge from the LLM to improve its performance. A deeper analysis of the learned representations and the specific mechanisms underlying the knowledge transfer could help in understanding the model's decision-making processes.
-
Potential Biases and Limitations: As with any AI system, there is a risk of the model inheriting biases or limitations present in the data or the LLM. The paper does not discuss the potential ethical implications or mitigation strategies for these concerns.
-
Integration with Contextual Emotion Recognition: Facial expression recognition is closely related to emotion recognition, and it could be interesting to explore how the proposed approach could be combined with techniques for contextual emotion recognition using large vision-language models.
Overall, the research presents a promising approach for enhancing zero-shot facial expression recognition, and the findings could have significant implications for a wide range of applications that rely on understanding human emotions and expressions.
Conclusion
This research paper introduces a novel method for enhancing zero-shot facial expression recognition by leveraging the knowledge captured by large language models (LLMs). The key idea is to align the facial expression representations with the corresponding semantic representations from LLMs using a contrastive learning framework.
The proposed approach has been shown to outperform state-of-the-art zero-shot facial expression recognition methods, particularly in situations where the target domain has limited training data. This suggests that the rich knowledge and understanding of expressions captured by LLMs can be effectively transferred to improve the performance of facial expression recognition models in challenging, data-scarce scenarios.
While the research presents a promising direction, there are also several areas for further exploration, such as investigating the generalization of the method to other zero-shot learning problems, analyzing the interpretability and explainability of the model's decision-making, and addressing potential biases and ethical considerations. By continuing to build on these findings, researchers can further advance the field of facial expression recognition and unlock new possibilities for applications that rely on understanding human emotions and expressions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Zero-Shot Facial Expression Recognition by LLM Knowledge Transfer
Zengqun Zhao, Yu Cao, Shaogang Gong, Ioannis Patras
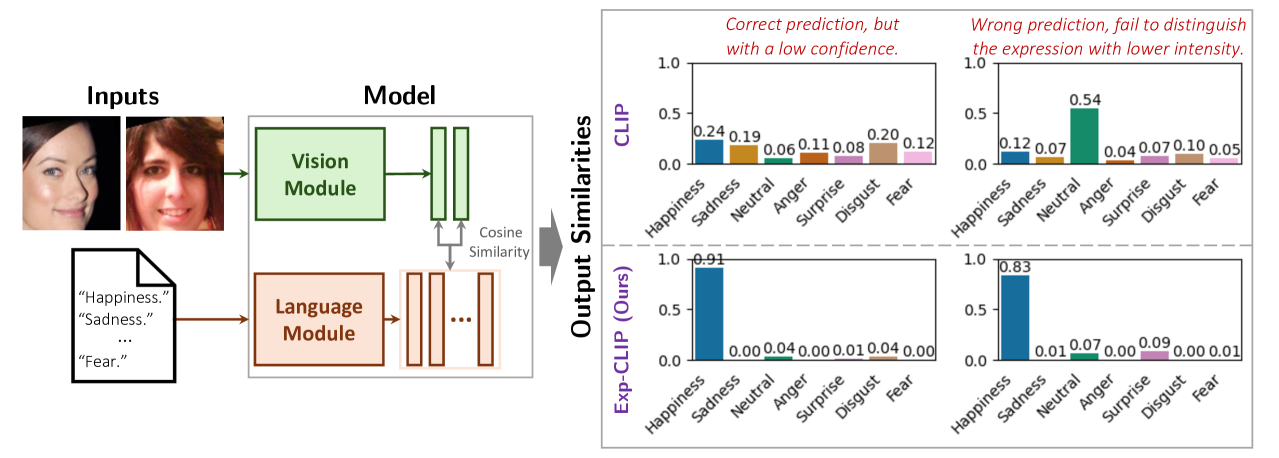
Current facial expression recognition (FER) models are often designed in a supervised learning manner and thus are constrained by the lack of large-scale facial expression images with high-quality annotations. Consequently, these models often fail to generalize well, performing poorly on unseen images in inference. Vision-language-based zero-shot models demonstrate a promising potential for addressing such challenges. However, these models lack task-specific knowledge and therefore are not optimized for the nuances of recognizing facial expressions. To bridge this gap, this work proposes a novel method, Exp-CLIP, to enhance zero-shot FER by transferring the task knowledge from large language models (LLMs). Specifically, based on the pre-trained vision-language encoders, we incorporate a projection head designed to map the initial joint vision-language space into a space that captures representations of facial actions. To train this projection head for subsequent zero-shot predictions, we propose to align the projected visual representations with task-specific semantic meanings derived from the LLM encoder, and the text instruction-based strategy is employed to customize the LLM knowledge. Given unlabelled facial data and efficient training of the projection head, Exp-CLIP achieves superior zero-shot results to the CLIP models and several other large vision-language models (LVLMs) on seven in-the-wild FER datasets.
Read more6/19/2024

0
Generalizable Facial Expression Recognition
Yuhang Zhang, Xiuqi Zheng, Chenyi Liang, Jiani Hu, Weihong Deng
SOTA facial expression recognition (FER) methods fail on test sets that have domain gaps with the train set. Recent domain adaptation FER methods need to acquire labeled or unlabeled samples of target domains to fine-tune the FER model, which might be infeasible in real-world deployment. In this paper, we aim to improve the zero-shot generalization ability of FER methods on different unseen test sets using only one train set. Inspired by how humans first detect faces and then select expression features, we propose a novel FER pipeline to extract expression-related features from any given face images. Our method is based on the generalizable face features extracted by large models like CLIP. However, it is non-trivial to adapt the general features of CLIP for specific tasks like FER. To preserve the generalization ability of CLIP and the high precision of the FER model, we design a novel approach that learns sigmoid masks based on the fixed CLIP face features to extract expression features. To further improve the generalization ability on unseen test sets, we separate the channels of the learned masked features according to the expression classes to directly generate logits and avoid using the FC layer to reduce overfitting. We also introduce a channel-diverse loss to make the learned masks separated. Extensive experiments on five different FER datasets verify that our method outperforms SOTA FER methods by large margins. Code is available in https://github.com/zyh-uaiaaaa/Generalizable-FER.
Read more8/21/2024

0
New!Knowledge-Enhanced Facial Expression Recognition with Emotional-to-Neutral Transformation
Hangyu Li, Yihan Xu, Jiangchao Yao, Nannan Wang, Xinbo Gao, Bo Han
Existing facial expression recognition (FER) methods typically fine-tune a pre-trained visual encoder using discrete labels. However, this form of supervision limits to specify the emotional concept of different facial expressions. In this paper, we observe that the rich knowledge in text embeddings, generated by vision-language models, is a promising alternative for learning discriminative facial expression representations. Inspired by this, we propose a novel knowledge-enhanced FER method with an emotional-to-neutral transformation. Specifically, we formulate the FER problem as a process to match the similarity between a facial expression representation and text embeddings. Then, we transform the facial expression representation to a neutral representation by simulating the difference in text embeddings from textual facial expression to textual neutral. Finally, a self-contrast objective is introduced to pull the facial expression representation closer to the textual facial expression, while pushing it farther from the neutral representation. We conduct evaluation with diverse pre-trained visual encoders including ResNet-18 and Swin-T on four challenging facial expression datasets. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art FER methods. The code will be publicly available.
Read more9/16/2024
🛸
0
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
Read more6/7/2024