Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting

0

Sign in to get full access
Overview
- Presents a new approach for open-set video-based facial expression recognition
- Leverages textual and visual prompting to improve performance on unseen expressions
- Introduces a novel human expression-sensitive prompting technique
Plain English Explanation
This paper describes a new method for recognizing facial expressions in videos, even when some of the expressions are not seen during training. The key idea is to use textual and visual "prompts" to help the model better understand and recognize facial expressions, including ones it hasn't seen before.
The researchers found that by providing the model with carefully-designed textual and visual cues about different expressions, they could significantly improve its ability to correctly classify facial expressions, even those it hadn't been trained on previously. This is an important advancement, as real-world applications of facial expression recognition often need to work with a wide range of expressions, not just a limited set.
The new "human expression-sensitive prompting" technique developed in this paper helps the model better understand the nuances and subtleties of different facial expressions. This allows the system to more accurately recognize expressions, which could have valuable applications in areas like human-computer interaction, emotion analysis, and surveillance.
Technical Explanation
The paper proposes an open-set video-based facial expression recognition framework that leverages textual and visual prompting to improve performance on unseen facial expressions. The key components include:
-
Textual Prompting: The model is provided with textual descriptions of different facial expressions, which helps it better understand the semantic meaning and visual characteristics of each expression.
-
Visual Prompting: In addition to textual cues, the model is also shown example images of each facial expression. This visual information further enhances the model's ability to recognize expressions, even those it has not been explicitly trained on.
-
Human Expression-Sensitive Prompting: The researchers develop a novel prompting technique that takes into account how humans perceive and describe facial expressions. This helps the model align its understanding of expressions with how people naturally think about and communicate them.
The researchers evaluate their approach on several benchmark datasets for open-set video-based facial expression recognition. They demonstrate significant improvements in classification accuracy compared to baseline methods, particularly for expressions that were not seen during training. This suggests the prompting techniques are effective at helping the model generalize to new, unseen facial expressions.
Critical Analysis
The paper presents a promising approach for addressing the challenge of open-set facial expression recognition. By incorporating textual and visual prompting, the model is able to better leverage human-centric knowledge about expressions, leading to improved performance.
However, the paper does not fully explore the limitations of this approach. For example, it's unclear how the method would scale to a very large number of facial expressions, or how sensitive the performance is to the quality and relevance of the prompts provided. Additionally, the paper does not address potential biases or fairness issues that could arise from the prompting techniques.
Further research is needed to better understand the strengths and weaknesses of this approach, as well as how it compares to other state-of-the-art methods for open-vocabulary facial expression recognition and unseen expression classification. Nonetheless, the core ideas presented in this paper represent an interesting and potentially impactful contribution to the field of facial expression recognition.
Conclusion
This paper introduces a novel approach for open-set video-based facial expression recognition that leverages textual and visual prompting, as well as a new human expression-sensitive prompting technique. The results demonstrate significant improvements in recognizing unseen facial expressions, which is an important capability for real-world applications of facial analysis technology.
While the paper does not fully explore the limitations of the proposed method, it presents a promising direction for enhancing the generalization and interpretability of facial expression recognition systems. Further research in this area could lead to more robust and inclusive emotion analysis tools, with potential applications in areas like human-computer interaction, mental health monitoring, and surveillance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting
Yuanyuan Liu, Yuxuan Huang, Shuyang Liu, Yibing Zhan, Zijing Chen, Zhe Chen
In Video-based Facial Expression Recognition (V-FER), models are typically trained on closed-set datasets with a fixed number of known classes. However, these models struggle with unknown classes common in real-world scenarios. In this paper, we introduce a challenging Open-set Video-based Facial Expression Recognition (OV-FER) task, aiming to identify both known and new, unseen facial expressions. While existing approaches use large-scale vision-language models like CLIP to identify unseen classes, we argue that these methods may not adequately capture the subtle human expressions needed for OV-FER. To address this limitation, we propose a novel Human Expression-Sensitive Prompting (HESP) mechanism to significantly enhance CLIP's ability to model video-based facial expression details effectively. Our proposed HESP comprises three components: 1) a textual prompting module with learnable prompts to enhance CLIP's textual representation of both known and unknown emotions, 2) a visual prompting module that encodes temporal emotional information from video frames using expression-sensitive attention, equipping CLIP with a new visual modeling ability to extract emotion-rich information, and 3) an open-set multi-task learning scheme that promotes interaction between the textual and visual modules, improving the understanding of novel human emotions in video sequences. Extensive experiments conducted on four OV-FER task settings demonstrate that HESP can significantly boost CLIP's performance (a relative improvement of 17.93% on AUROC and 106.18% on OSCR) and outperform other state-of-the-art open-set video understanding methods by a large margin. Code is available at https://github.com/cosinehuang/HESP.
Read more8/2/2024
0
Enhancing Zero-Shot Facial Expression Recognition by LLM Knowledge Transfer
Zengqun Zhao, Yu Cao, Shaogang Gong, Ioannis Patras
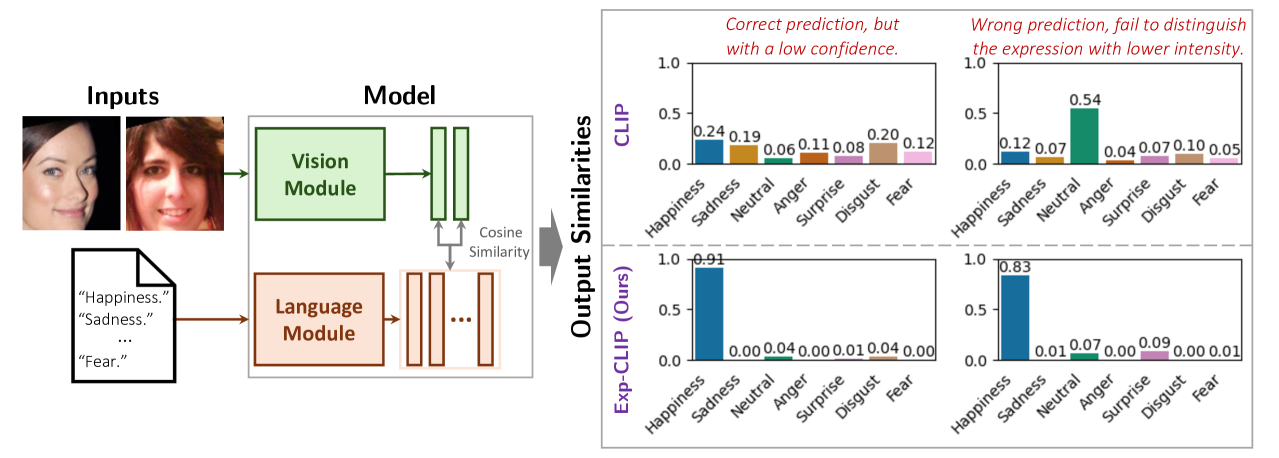
Current facial expression recognition (FER) models are often designed in a supervised learning manner and thus are constrained by the lack of large-scale facial expression images with high-quality annotations. Consequently, these models often fail to generalize well, performing poorly on unseen images in inference. Vision-language-based zero-shot models demonstrate a promising potential for addressing such challenges. However, these models lack task-specific knowledge and therefore are not optimized for the nuances of recognizing facial expressions. To bridge this gap, this work proposes a novel method, Exp-CLIP, to enhance zero-shot FER by transferring the task knowledge from large language models (LLMs). Specifically, based on the pre-trained vision-language encoders, we incorporate a projection head designed to map the initial joint vision-language space into a space that captures representations of facial actions. To train this projection head for subsequent zero-shot predictions, we propose to align the projected visual representations with task-specific semantic meanings derived from the LLM encoder, and the text instruction-based strategy is employed to customize the LLM knowledge. Given unlabelled facial data and efficient training of the projection head, Exp-CLIP achieves superior zero-shot results to the CLIP models and several other large vision-language models (LVLMs) on seven in-the-wild FER datasets.
Read more6/19/2024

0
New!Knowledge-Enhanced Facial Expression Recognition with Emotional-to-Neutral Transformation
Hangyu Li, Yihan Xu, Jiangchao Yao, Nannan Wang, Xinbo Gao, Bo Han
Existing facial expression recognition (FER) methods typically fine-tune a pre-trained visual encoder using discrete labels. However, this form of supervision limits to specify the emotional concept of different facial expressions. In this paper, we observe that the rich knowledge in text embeddings, generated by vision-language models, is a promising alternative for learning discriminative facial expression representations. Inspired by this, we propose a novel knowledge-enhanced FER method with an emotional-to-neutral transformation. Specifically, we formulate the FER problem as a process to match the similarity between a facial expression representation and text embeddings. Then, we transform the facial expression representation to a neutral representation by simulating the difference in text embeddings from textual facial expression to textual neutral. Finally, a self-contrast objective is introduced to pull the facial expression representation closer to the textual facial expression, while pushing it farther from the neutral representation. We conduct evaluation with diverse pre-trained visual encoders including ResNet-18 and Swin-T on four challenging facial expression datasets. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art FER methods. The code will be publicly available.
Read more9/16/2024
👁️
0
Rethinking the Learning Paradigm for Facial Expression Recognition
Weijie Wang, Nicu Sebe, Bruno Lepri
Due to the subjective crowdsourcing annotations and the inherent inter-class similarity of facial expressions, the real-world Facial Expression Recognition (FER) datasets usually exhibit ambiguous annotation. To simplify the learning paradigm, most previous methods convert ambiguous annotation results into precise one-hot annotations and train FER models in an end-to-end supervised manner. In this paper, we rethink the existing training paradigm and propose that it is better to use weakly supervised strategies to train FER models with original ambiguous annotation.
Read more9/4/2024