Generalization bounds for regression and classification on adaptive covering input domains

0
Sign in to get full access
Overview
- Examines generalization bounds for regression and classification tasks on adaptive covering input domains
- Proposes a new framework for analyzing model generalization in complex input spaces
- Derives tighter bounds on sample complexity and model complexity to improve out-of-sample performance
Plain English Explanation
This research paper introduces a new approach for analyzing the generalization performance of machine learning models, particularly for regression and classification tasks in complex input domains. The key idea is to consider how the complexity of the input space, as captured by an "adaptive covering" of the domain, affects the model's ability to generalize beyond the training data.
The authors derive tighter theoretical bounds on the sample complexity and model complexity required to achieve a given level of generalization error. This provides important insights into the factors that influence a model's out-of-sample performance, going beyond simpler notions of model capacity or dataset size.
The adaptive covering framework allows the authors to capture the intricate structure of complex real-world input domains, which may exhibit varying degrees of complexity in different regions. This is in contrast to simpler assumptions, such as a uniform distribution over a fixed, bounded input space.
By incorporating this more nuanced view of the input domain, the researchers are able to derive generalization bounds that are tighter and more informative than previous results. This can help guide the design of more effective machine learning systems, especially in domains where the input space has a complex, heterogeneous structure.
Technical Explanation
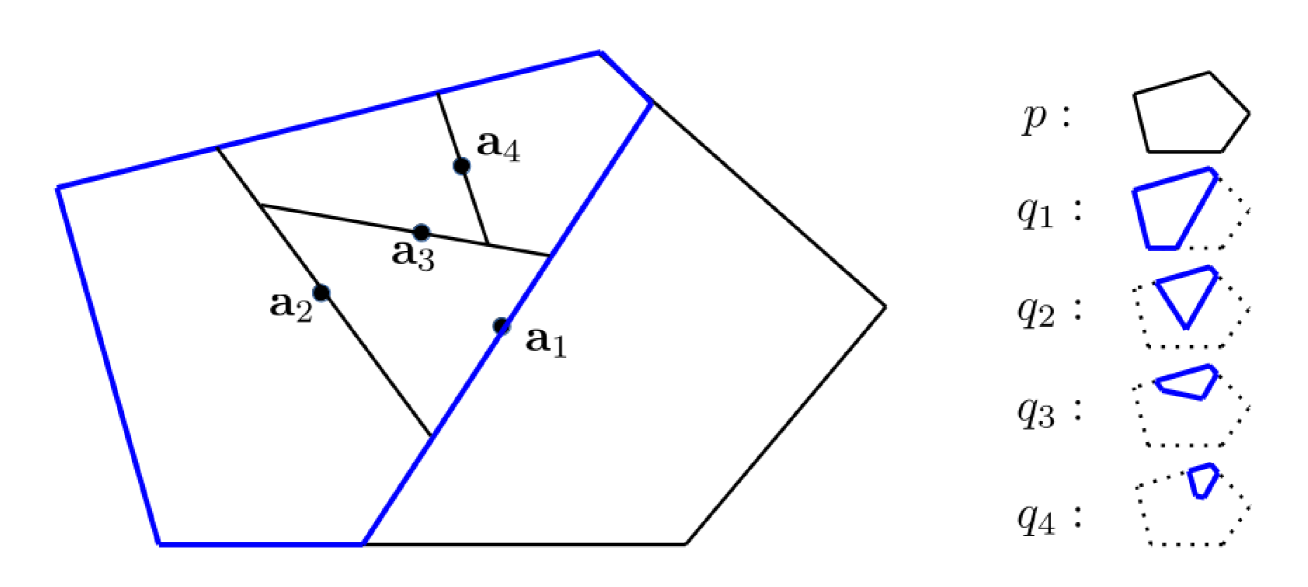
The paper introduces a novel framework for analyzing the generalization performance of regression and classification models on adaptive covering input domains. The key idea is to capture the complexity of the input space using an "adaptive covering" - a partition of the input domain into regions of varying complexity, as measured by the Lipschitz constant of the target function within each region.
This adaptive covering approach allows the authors to derive tighter bounds on the sample complexity (the number of training examples required) and the model complexity (the capacity of the function class) needed to achieve a given level of generalization error. These bounds incorporate the inherent complexity of the input domain, going beyond simpler notions of model capacity or dataset size.
The authors prove that the sample complexity and model complexity required for good generalization scale with the covering number of the input domain, which encodes the complexity of the adaptive covering. This provides important insights into the factors that influence a model's out-of-sample performance, especially in domains with heterogeneous input spaces.
The adaptive covering framework allows the authors to capture the intricate structure of complex real-world input domains, where the complexity of the target function may vary across different regions of the input space. This is in contrast to simpler assumptions, such as a uniform distribution over a fixed, bounded input space.
By incorporating this more nuanced view of the input domain, the researchers are able to derive generalization bounds that are tighter and more informative than previous results. This can help guide the design of more effective machine learning systems, especially in domains where the input space has a complex, heterogeneous structure.
Critical Analysis
The paper presents a compelling theoretical framework for analyzing generalization in machine learning, with a focus on regression and classification tasks. The key strength of the approach is its ability to capture the inherent complexity of the input domain, which is an important factor that is often overlooked in simpler generalization analyses.
One potential limitation is that the adaptive covering framework may be challenging to apply in practice, as it requires a detailed understanding of the input domain and the Lipschitz continuity of the target function. The authors acknowledge this challenge and suggest that further research is needed to develop practical techniques for constructing adaptive coverings in real-world scenarios.
Additionally, the paper does not address the implications of the adaptive covering framework for specific application domains or the development of practical algorithms. While the theoretical insights are valuable, it would be interesting to see how this approach could be applied to solve concrete machine learning problems and how it compares to other state-of-the-art techniques.
Overall, the research represents an important step forward in our understanding of generalization in complex input spaces. The adaptive covering framework provides a promising direction for future work on improving the robustness and reliability of machine learning systems.
Conclusion
This paper introduces a novel framework for analyzing the generalization performance of machine learning models on complex input domains. By considering the adaptive covering of the input space, the authors derive tighter bounds on sample complexity and model complexity, providing valuable insights into the factors that influence out-of-sample performance.
The adaptive covering approach allows the researchers to capture the intricate structure of real-world input spaces, where the complexity of the target function may vary across different regions. This is a significant advancement over simpler assumptions about the input domain, and the theoretical results can help guide the design of more effective machine learning systems.
While the practical application of the adaptive covering framework may present some challenges, the insights from this research represent an important step forward in our understanding of generalization in complex environments. Further work is needed to explore the implementation of these ideas and their impact on specific machine learning tasks and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalization bounds for regression and classification on adaptive covering input domains
Wen-Liang Hwang
Our main focus is on the generalization bound, which serves as an upper limit for the generalization error. Our analysis delves into regression and classification tasks separately to ensure a thorough examination. We assume the target function is real-valued and Lipschitz continuous for regression tasks. We use the 2-norm and a root-mean-square-error (RMSE) variant to measure the disparities between predictions and actual values. In the case of classification tasks, we treat the target function as a one-hot classifier, representing a piece-wise constant function, and employ 0/1 loss for error measurement. Our analysis underscores the differing sample complexity required to achieve a concentration inequality of generalization bounds, highlighting the variation in learning efficiency for regression and classification tasks. Furthermore, we demonstrate that the generalization bounds for regression and classification functions are inversely proportional to a polynomial of the number of parameters in a network, with the degree depending on the hypothesis class and the network architecture. These findings emphasize the advantages of over-parameterized networks and elucidate the conditions for benign overfitting in such systems.
Read more7/30/2024
0
Generalization Bounds for Causal Regression: Insights, Guarantees and Sensitivity Analysis
Daniel Csillag, Claudio Jos'e Struchiner, Guilherme Tegoni Goedert
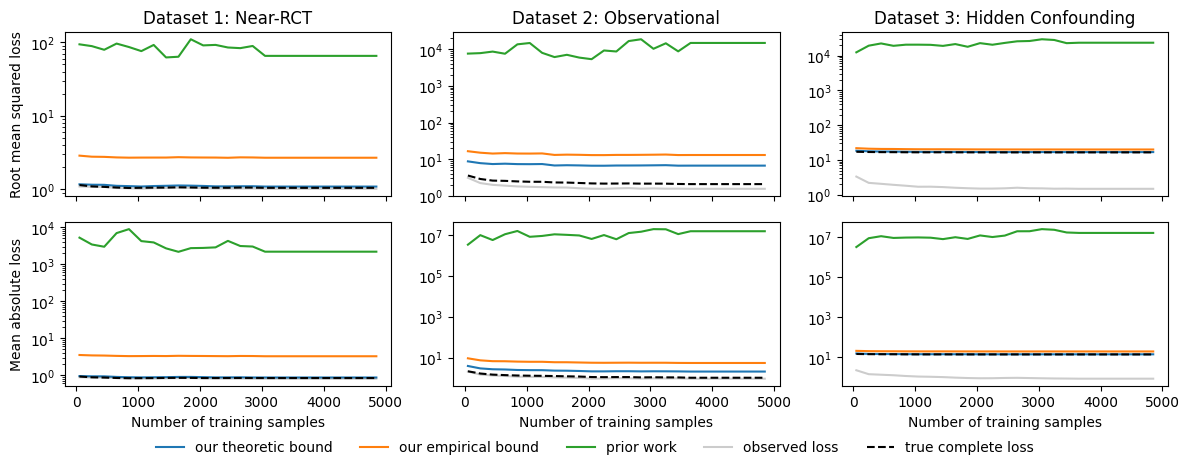
Many algorithms have been recently proposed for causal machine learning. Yet, there is little to no theory on their quality, especially considering finite samples. In this work, we propose a theory based on generalization bounds that provides such guarantees. By introducing a novel change-of-measure inequality, we are able to tightly bound the model loss in terms of the deviation of the treatment propensities over the population, which we show can be empirically limited. Our theory is fully rigorous and holds even in the face of hidden confounding and violations of positivity. We demonstrate our bounds on semi-synthetic and real data, showcasing their remarkable tightness and practical utility.
Read more5/16/2024
0
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
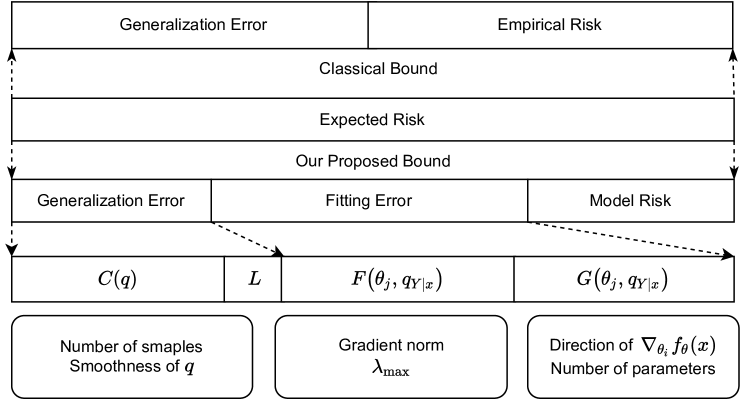
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
Read more6/28/2024
🤯
0
On the Limitations of General Purpose Domain Generalisation Methods
Henry Gouk, Ondrej Bohdal, Da Li, Timothy Hospedales
We investigate the fundamental performance limitations of learning algorithms in several Domain Generalisation (DG) settings. Motivated by the difficulty with which previously proposed methods have in reliably outperforming Empirical Risk Minimisation (ERM), we derive upper bounds on the excess risk of ERM, and lower bounds on the minimax excess risk. Our findings show that in all the DG settings we consider, it is not possible to significantly outperform ERM. Our conclusions are limited not only to the standard covariate shift setting, but also two other settings with additional restrictions on how domains can differ. The first constrains all domains to have a non-trivial bound on pairwise distances, as measured by a broad class of integral probability metrics. The second alternate setting considers a restricted class of DG problems where all domains have the same underlying support. Our analysis also suggests how different strategies can be used to optimise the performance of ERM in each of these DG setting. We also experimentally explore hypotheses suggested by our theoretical analysis.
Read more5/24/2024