Global Rewards in Multi-Agent Deep Reinforcement Learning for Autonomous Mobility on Demand Systems
2312.08884
0
0
🤿
Abstract
We study vehicle dispatching in autonomous mobility on demand (AMoD) systems, where a central operator assigns vehicles to customer requests or rejects these with the aim of maximizing its total profit. Recent approaches use multi-agent deep reinforcement learning (MADRL) to realize scalable yet performant algorithms, but train agents based on local rewards, which distorts the reward signal with respect to the system-wide profit, leading to lower performance. We therefore propose a novel global-rewards-based MADRL algorithm for vehicle dispatching in AMoD systems, which resolves so far existing goal conflicts between the trained agents and the operator by assigning rewards to agents leveraging a counterfactual baseline. Our algorithm shows statistically significant improvements across various settings on real-world data compared to state-of-the-art MADRL algorithms with local rewards. We further provide a structural analysis which shows that the utilization of global rewards can improve implicit vehicle balancing and demand forecasting abilities. Our code is available at https://github.com/tumBAIS/GR-MADRL-AMoD.
Create account to get full access
Overview
- The paper focuses on vehicle dispatching in autonomous mobility on demand (AMoD) systems, where a central operator assigns vehicles to customer requests or rejects them to maximize profit.
- The researchers propose a novel global-rewards-based multi-agent deep reinforcement learning (MADRL) algorithm for vehicle dispatching in AMoD systems.
- The algorithm resolves conflicts between the trained agents and the operator's goal of maximizing system-wide profit by assigning rewards to agents based on a counterfactual baseline.
- The proposed algorithm shows statistically significant improvements over state-of-the-art MADRL algorithms that use local rewards.
- The researchers provide a structural analysis demonstrating that using global rewards can improve implicit vehicle balancing and demand forecasting abilities.
Plain English Explanation
In autonomous mobility on demand (AMoD) systems, a central operator assigns vehicles to customer requests with the goal of maximizing the system's overall profit. Recent approaches have used multi-agent deep reinforcement learning (MADRL) to create scalable and effective algorithms for this task, but the agents are typically trained based on local rewards, which can lead to them making decisions that conflict with the operator's goal of maximizing profit.
To address this issue, the researchers in this paper propose a new MADRL algorithm that uses global rewards instead of local rewards. The global rewards are calculated using a counterfactual baseline, which helps align the agents' goals with the operator's goal of maximizing profit. This resolves the goal conflicts that can arise when using local rewards.
The researchers tested their algorithm on real-world data and found that it significantly outperforms state-of-the-art MADRL algorithms that use local rewards. They also provide an analysis showing that the use of global rewards can improve the agents' ability to balance the vehicles across the system and forecast demand, which are important capabilities for effective vehicle dispatching.
Technical Explanation
The paper proposes a novel global-rewards-based MADRL algorithm for vehicle dispatching in AMoD systems. The key innovation is the use of a counterfactual baseline to calculate global rewards for the agents, which helps to align their objectives with the system-wide goal of maximizing profit.
The researchers conducted experiments on real-world data and found that their algorithm significantly outperforms existing MADRL approaches that use local rewards. They attribute this improved performance to the algorithm's ability to better balance vehicles and forecast demand, which are critical for effective vehicle dispatching.
The paper provides a detailed technical description of the algorithm, including the reward function, agent architecture, and training procedure. The researchers also present a structural analysis that sheds light on the mechanisms underlying the algorithm's improved performance, such as its impact on implicit vehicle balancing and demand forecasting.
Critical Analysis
The paper presents a well-designed and well-executed study that addresses an important problem in the field of AMoD systems. The use of global rewards to align the agents' objectives with the system-wide goal is a novel and promising approach, and the researchers have provided strong empirical evidence of its effectiveness.
One potential limitation of the study is the reliance on a single real-world dataset. It would be valuable to validate the algorithm's performance on additional datasets to ensure its generalizability. Additionally, the paper does not explore the algorithm's sensitivity to various hyperparameters or environmental conditions, which could be an area for further investigation.
Furthermore, the researchers acknowledge that their approach may be more computationally intensive than some existing MADRL algorithms due to the need to calculate the counterfactual baseline. This could be a concern for real-time applications, and the researchers may want to explore ways to optimize the algorithm's efficiency.
Overall, the paper presents a compelling and well-executed piece of research that contributes to the ongoing efforts to develop effective vehicle dispatching algorithms for AMoD systems. The use of global rewards is a promising direction, and the researchers' insights into the algorithm's impact on vehicle balancing and demand forecasting are valuable contributions to the field.
Conclusion
This paper introduces a novel global-rewards-based MADRL algorithm for vehicle dispatching in AMoD systems. By aligning the agents' objectives with the system-wide goal of maximizing profit through the use of a counterfactual baseline, the algorithm is able to significantly outperform existing MADRL approaches that rely on local rewards.
The researchers' findings demonstrate the importance of considering the system-wide impact of the agents' decisions in multi-agent reinforcement learning for AMoD applications. The insights into the algorithm's effect on vehicle balancing and demand forecasting also provide valuable guidance for the design of future vehicle dispatching systems.
While the paper presents a promising solution, further research is needed to explore the algorithm's broader applicability and computational efficiency. Nonetheless, this work represents an important step forward in the development of scalable and effective vehicle dispatching algorithms for the increasingly important field of autonomous mobility on demand.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Real-time Control of Electric Autonomous Mobility-on-Demand Systems via Graph Reinforcement Learning
Aaryan Singhal, Daniele Gammelli, Justin Luke, Karthik Gopalakrishnan, Dominik Helmreich, Marco Pavone
0
0
Operators of Electric Autonomous Mobility-on-Demand (E-AMoD) fleets need to make several real-time decisions such as matching available vehicles to ride requests, rebalancing idle vehicles to areas of high demand, and charging vehicles to ensure sufficient range. While this problem can be posed as a linear program that optimizes flows over a space-charge-time graph, the size of the resulting optimization problem does not allow for real-time implementation in realistic settings. In this work, we present the E-AMoD control problem through the lens of reinforcement learning and propose a graph network-based framework to achieve drastically improved scalability and superior performance over heuristics. Specifically, we adopt a bi-level formulation where we (1) leverage a graph network-based RL agent to specify a desired next state in the space-charge graph, and (2) solve more tractable linear programs to best achieve the desired state while ensuring feasibility. Experiments using real-world data from San Francisco and New York City show that our approach achieves up to 89% of the profits of the theoretically-optimal solution while achieving more than a 100x speedup in computational time. We further highlight promising zero-shot transfer capabilities of our learned policy on tasks such as inter-city generalization and service area expansion, thus showing the utility, scalability, and flexibility of our framework. Finally, our approach outperforms the best domain-specific heuristics with comparable runtimes, with an increase in profits by up to 3.2x.
4/5/2024
📈
Multi-Agent Soft Actor-Critic with Global Loss for Autonomous Mobility-on-Demand Fleet Control
Zeno Woywood, Jasper I. Wiltfang, Julius Luy, Tobias Enders, Maximilian Schiffer
0
0
We study a sequential decision-making problem for a profit-maximizing operator of an Autonomous Mobility-on-Demand system. Optimizing a central operator's vehicle-to-request dispatching policy requires efficient and effective fleet control strategies. To this end, we employ a multi-agent Soft Actor-Critic algorithm combined with weighted bipartite matching. We propose a novel vehicle-based algorithm architecture and adapt the critic's loss function to appropriately consider global actions. Furthermore, we extend our algorithm to incorporate rebalancing capabilities. Through numerical experiments, we show that our approach outperforms state-of-the-art benchmarks by up to 12.9% for dispatching and up to 38.9% with integrated rebalancing.
4/11/2024

Multi-Task Lane-Free Driving Strategy for Connected and Automated Vehicles: A Multi-Agent Deep Reinforcement Learning Approach
Mehran Berahman, Majid Rostami-Shahrbabaki, Klaus Bogenberger
0
0
Deep reinforcement learning has shown promise in various engineering applications, including vehicular traffic control. The non-stationary nature of traffic, especially in the lane-free environment with more degrees of freedom in vehicle behaviors, poses challenges for decision-making since a wrong action might lead to a catastrophic failure. In this paper, we propose a novel driving strategy for Connected and Automated Vehicles (CAVs) based on a competitive Multi-Agent Deep Deterministic Policy Gradient approach. The developed multi-agent deep reinforcement learning algorithm creates a dynamic and non-stationary scenario, mirroring real-world traffic complexities and making trained agents more robust. The algorithm's reward function is strategically and uniquely formulated to cover multiple vehicle control tasks, including maintaining desired speeds, overtaking, collision avoidance, and merging and diverging maneuvers. Moreover, additional considerations for both lateral and longitudinal passenger comfort and safety criteria are taken into account. We employed inter-vehicle forces, known as nudging and repulsive forces, to manage the maneuvers of CAVs in a lane-free traffic environment. The proposed driving algorithm is trained and evaluated on lane-free roads using the Simulation of Urban Mobility platform. Experimental results demonstrate the algorithm's efficacy in handling different objectives, highlighting its potential to enhance safety and efficiency in autonomous driving within lane-free traffic environments.
6/24/2024
Urban-Focused Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing
Xinbo Zhao, Yingxue Zhang, Xin Zhang, Yu Yang, Yiqun Xie, Yanhua Li, Jun Luo
0
0
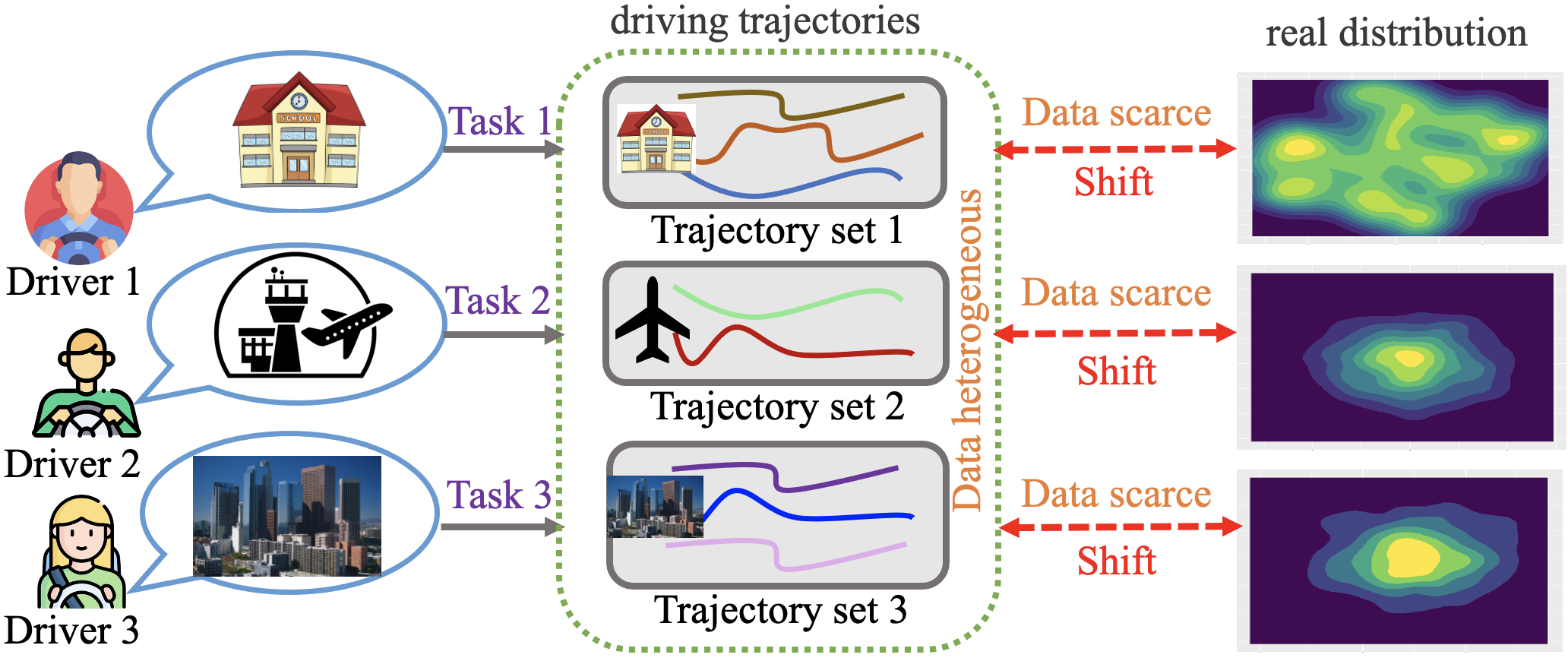
Enhancing diverse human decision-making processes in an urban environment is a critical issue across various applications, including ride-sharing vehicle dispatching, public transportation management, and autonomous driving. Offline reinforcement learning (RL) is a promising approach to learn and optimize human urban strategies (or policies) from pre-collected human-generated spatial-temporal urban data. However, standard offline RL faces two significant challenges: (1) data scarcity and data heterogeneity, and (2) distributional shift. In this paper, we introduce MODA -- a Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing approach. MODA addresses the challenges of data scarcity and heterogeneity in a multi-task urban setting through Contrastive Data Sharing among tasks. This technique involves extracting latent representations of human behaviors by contrasting positive and negative data pairs. It then shares data presenting similar representations with the target task, facilitating data augmentation for each task. Moreover, MODA develops a novel model-based multi-task offline RL algorithm. This algorithm constructs a robust Markov Decision Process (MDP) by integrating a dynamics model with a Generative Adversarial Network (GAN). Once the robust MDP is established, any online RL or planning algorithm can be applied. Extensive experiments conducted in a real-world multi-task urban setting validate the effectiveness of MODA. The results demonstrate that MODA exhibits significant improvements compared to state-of-the-art baselines, showcasing its capability in advancing urban decision-making processes. We also made our code available to the research community.
6/21/2024