Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning

0

Sign in to get full access
Overview
- This paper proposes a plug-and-play approach for generalizing deepfake video detection.
- Key ideas include video-level blending and spatiotemporal adapter tuning.
- The goal is to improve the performance and generalization of deepfake detection models.
Plain English Explanation
The paper focuses on improving the ability to detect deepfake videos - videos that have been digitally manipulated to depict events or people that did not actually occur. Current deepfake detection models can struggle to generalize well to new types of deepfakes.
The researchers introduce two main techniques to address this:
-
Video-Level Blending: They blend real and fake video frames together during training to create more realistic and diverse examples for the detection model to learn from. This helps the model become more robust to different types of deepfakes.
-
Spatiotemporal Adapter Tuning: They add small neural network "adapters" that can be quickly tuned on new datasets, allowing the core detection model to be reused and adapted to different domains without requiring a full retraining.
These innovations allow the detection model to more effectively generalize to various deepfake scenarios, rather than being limited to a specific set of training data. This makes the approach more plug-and-play - it can be more easily applied to new deepfake detection challenges.
Technical Explanation
The paper proposes a Generalizable Deepfake Video Detector (GDVD) framework that incorporates two key components:
-
Video-Level Blending: The researchers create blended training examples by seamlessly combining real and fake video frames. This introduces more diversity and realism into the training data, helping the model learn more general cues for detecting deepfakes.
-
Spatiotemporal Adapter Tuning: The core detection model is augmented with small, learnable "adapter" modules that can be quickly fine-tuned on new datasets. This allows the model to be adapted to different domains without the need for full retraining, improving its generalization capabilities.
The paper evaluates GDVD on several deepfake detection benchmarks, demonstrating improved performance and generalization compared to prior approaches. The modular design and adaptability of the framework are highlighted as key advantages.
Critical Analysis
The paper presents a well-designed and principled approach to improving the generalization of deepfake video detection models. The ideas of video-level blending and adapter tuning are novel and seem promising based on the experimental results.
However, there are a few potential limitations and areas for further research:
-
Scalability: While the adapter tuning approach aims to improve generalization, the need to fine-tune on new datasets may still require significant effort and compute resources, limiting the true "plug-and-play" nature of the system.
-
Robustness Evaluation: The paper focuses on improving overall detection performance, but does not provide a thorough analysis of the model's robustness to adversarial attacks or other evasion techniques that deepfake creators may employ.
-
Real-World Deployment: The experiments are conducted on existing deepfake datasets, which may not fully capture the diversity and complexity of deepfakes encountered in the real world. Further validation on more diverse and evolving deepfake scenarios would be beneficial.
Overall, the proposed GDVD framework represents an important step forward in making deepfake detection more generalizable and practical. Addressing the potential limitations through further research could lead to even more robust and widely applicable solutions.
Conclusion
This paper introduces a plug-and-play approach for generalizing deepfake video detection, with two key innovations: video-level blending to create more diverse training data, and spatiotemporal adapter tuning to enable efficient adaptation to new domains.
The experimental results demonstrate improved performance and generalization compared to prior work, suggesting that the GDVD framework could be a valuable tool for addressing the growing challenge of deepfake detection. While there are some limitations to address, this research represents an important advancement in the field of media forensics and the fight against the spread of misinformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning
Zhiyuan Yan, Yandan Zhao, Shen Chen, Xinghe Fu, Taiping Yao, Shouhong Ding, Li Yuan
Three key challenges hinder the development of current deepfake video detection: (1) Temporal features can be complex and diverse: how can we identify general temporal artifacts to enhance model generalization? (2) Spatiotemporal models often lean heavily on one type of artifact and ignore the other: how can we ensure balanced learning from both? (3) Videos are naturally resource-intensive: how can we tackle efficiency without compromising accuracy? This paper attempts to tackle the three challenges jointly. First, inspired by the notable generality of using image-level blending data for image forgery detection, we investigate whether and how video-level blending can be effective in video. We then perform a thorough analysis and identify a previously underexplored temporal forgery artifact: Facial Feature Drift (FFD), which commonly exists across different forgeries. To reproduce FFD, we then propose a novel Video-level Blending data (VB), where VB is implemented by blending the original image and its warped version frame-by-frame, serving as a hard negative sample to mine more general artifacts. Second, we carefully design a lightweight Spatiotemporal Adapter (StA) to equip a pretrained image model (both ViTs and CNNs) with the ability to capture both spatial and temporal features jointly and efficiently. StA is designed with two-stream 3D-Conv with varying kernel sizes, allowing it to process spatial and temporal features separately. Extensive experiments validate the effectiveness of the proposed methods; and show our approach can generalize well to previously unseen forgery videos, even the just-released (in 2024) SoTAs. We release our code and pretrained weights at url{https://github.com/YZY-stack/StA4Deepfake}.
Read more9/2/2024
🔎
0
Compressed Deepfake Video Detection Based on 3D Spatiotemporal Trajectories
Zongmei Chen, Xin Liao, Xiaoshuai Wu, Yanxiang Chen
The misuse of deepfake technology by malicious actors poses a potential threat to nations, societies, and individuals. However, existing methods for detecting deepfakes primarily focus on uncompressed videos, such as noise characteristics, local textures, or frequency statistics. When applied to compressed videos, these methods experience a decrease in detection performance and are less suitable for real-world scenarios. In this paper, we propose a deepfake video detection method based on 3D spatiotemporal trajectories. Specifically, we utilize a robust 3D model to construct spatiotemporal motion features, integrating feature details from both 2D and 3D frames to mitigate the influence of large head rotation angles or insufficient lighting within frames. Furthermore, we separate facial expressions from head movements and design a sequential analysis method based on phase space motion trajectories to explore the feature differences between genuine and fake faces in deepfake videos. We conduct extensive experiments to validate the performance of our proposed method on several compressed deepfake benchmarks. The robustness of the well-designed features is verified by calculating the consistent distribution of facial landmarks before and after video compression.Our method yields satisfactory results and showcases its potential for practical applications.
Read more4/30/2024
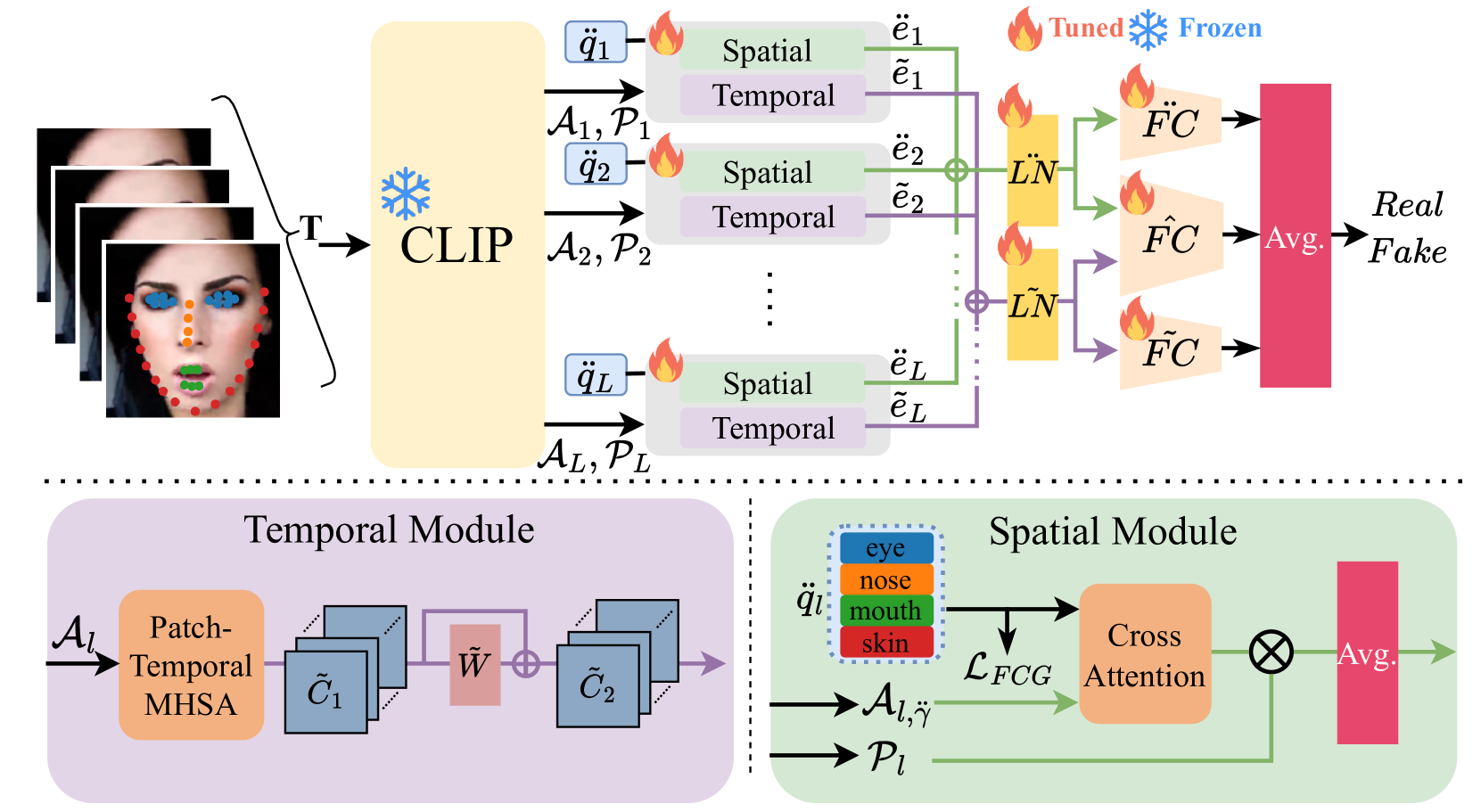
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024

0
UniForensics: Face Forgery Detection via General Facial Representation
Ziyuan Fang, Hanqing Zhao, Tianyi Wei, Wenbo Zhou, Ming Wan, Zhanyi Wang, Weiming Zhang, Nenghai Yu
Previous deepfake detection methods mostly depend on low-level textural features vulnerable to perturbations and fall short of detecting unseen forgery methods. In contrast, high-level semantic features are less susceptible to perturbations and not limited to forgery-specific artifacts, thus having stronger generalization. Motivated by this, we propose a detection method that utilizes high-level semantic features of faces to identify inconsistencies in temporal domain. We introduce UniForensics, a novel deepfake detection framework that leverages a transformer-based video classification network, initialized with a meta-functional face encoder for enriched facial representation. In this way, we can take advantage of both the powerful spatio-temporal model and the high-level semantic information of faces. Furthermore, to leverage easily accessible real face data and guide the model in focusing on spatio-temporal features, we design a Dynamic Video Self-Blending (DVSB) method to efficiently generate training samples with diverse spatio-temporal forgery traces using real facial videos. Based on this, we advance our framework with a two-stage training approach: The first stage employs a novel self-supervised contrastive learning, where we encourage the network to focus on forgery traces by impelling videos generated by the same forgery process to have similar representations. On the basis of the representation learned in the first stage, the second stage involves fine-tuning on face forgery detection dataset to build a deepfake detector. Extensive experiments validates that UniForensics outperforms existing face forgery methods in generalization ability and robustness. In particular, our method achieves 95.3% and 77.2% cross dataset AUC on the challenging Celeb-DFv2 and DFDC respectively.
Read more7/30/2024