Detecting Audio-Visual Deepfakes with Fine-Grained Inconsistencies

0

Sign in to get full access
Overview
- This research paper proposes a method for detecting audio-visual deepfakes using fine-grained inconsistencies.
- Deepfakes are synthetic media where a person's face or voice is replaced with someone else's, often for malicious purposes.
- The researchers develop a model that can identify subtle visual and audio cues that indicate a deepfake, going beyond previous approaches.
Plain English Explanation
The paper describes a new way to detect deepfakes, which are videos or audio recordings that have been manipulated to make it seem like someone is saying or doing something they didn't. Deepfakes can be used to spread misinformation or create embarrassing content, so being able to spot them is important.
The researchers' approach looks for small inconsistencies in the video and audio that suggest it has been tampered with. For example, the lip movements might not perfectly match the words being spoken, or there could be subtle differences in skin texture or lighting that give away the fact that it's not real.
Previous detection methods have focused on broader, high-level cues, but this new system is designed to pick up on much more granular details. By analyzing the video and audio at a very fine level, it can often catch deepfakes that other techniques would miss.
The paper shows that this fine-grained approach is more effective at detecting deepfakes than older methods. It's an important advance in the ongoing battle against this type of digital deception.
Technical Explanation
The researchers develop a multi-stream fusion model that combines visual and audio features to detect deepfakes. The visual stream analyzes things like facial landmarks, head pose, and micro-expressions, while the audio stream looks at spectrograms and other low-level audio cues.
These individual streams are then fused together using a cross-modal attention mechanism to identify inconsistencies between the video and audio that are indicative of a deepfake. The model is trained in a zero-shot learning setup, meaning it can detect deepfakes without having seen examples of the specific individuals or manipulation techniques during training.
Experiments on standard deepfake datasets show that this fine-grained, multi-modal approach outperforms previous state-of-the-art deepfake detection methods. The researchers attribute this to the model's ability to capture subtle inconsistencies that other detectors miss.
Critical Analysis
The paper makes a compelling case for the value of analyzing low-level visual and audio features to detect deepfakes. By going beyond high-level cues, the model is able to uncover manipulations that might slip past other detectors.
However, the researchers acknowledge that their approach has some limitations. The model still struggles with certain types of deepfakes, especially those that are very high quality or use advanced techniques to obscure inconsistencies. There is also the potential for deepfake creators to adapt and find ways to fool this detection method over time.
Additionally, the zero-shot learning setup is an interesting approach, but it's unclear how well the model would generalize to detecting completely new types of deepfakes that differ significantly from the training data. Further research may be needed to fully understand the strengths and weaknesses of this technique.
Overall, this paper represents an important advancement in the rapidly evolving field of deepfake detection. While no approach is perfect, the use of fine-grained inconsistencies is a promising direction that deserves further exploration and refinement.
Conclusion
This research proposes a novel deepfake detection method that looks for subtle inconsistencies between the visual and audio components of a video. By analyzing low-level features in both modalities, the model can often identify manipulations that are missed by other detectors.
While not a silver bullet, this fine-grained, multi-modal approach represents a significant step forward in the ongoing battle against digital deception. As deepfake technology continues to advance, techniques like this will be crucial for maintaining trust in online media and protecting against the spread of misinformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Detecting Audio-Visual Deepfakes with Fine-Grained Inconsistencies
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
Existing methods on audio-visual deepfake detection mainly focus on high-level features for modeling inconsistencies between audio and visual data. As a result, these approaches usually overlook finer audio-visual artifacts, which are inherent to deepfakes. Herein, we propose the introduction of fine-grained mechanisms for detecting subtle artifacts in both spatial and temporal domains. First, we introduce a local audio-visual model capable of capturing small spatial regions that are prone to inconsistencies with audio. For that purpose, a fine-grained mechanism based on a spatially-local distance coupled with an attention module is adopted. Second, we introduce a temporally-local pseudo-fake augmentation to include samples incorporating subtle temporal inconsistencies in our training set. Experiments on the DFDC and the FakeAVCeleb datasets demonstrate the superiority of the proposed method in terms of generalization as compared to the state-of-the-art under both in-dataset and cross-dataset settings.
Read more8/15/2024

0
Statistics-aware Audio-visual Deepfake Detector
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
In this paper, we propose an enhanced audio-visual deep detection method. Recent methods in audio-visual deepfake detection mostly assess the synchronization between audio and visual features. Although they have shown promising results, they are based on the maximization/minimization of isolated feature distances without considering feature statistics. Moreover, they rely on cumbersome deep learning architectures and are heavily dependent on empirically fixed hyperparameters. Herein, to overcome these limitations, we propose: (1) a statistical feature loss to enhance the discrimination capability of the model, instead of relying solely on feature distances; (2) using the waveform for describing the audio as a replacement of frequency-based representations; (3) a post-processing normalization of the fakeness score; (4) the use of shallower network for reducing the computational complexity. Experiments on the DFDC and FakeAVCeleb datasets demonstrate the relevance of the proposed method.
Read more7/18/2024
0
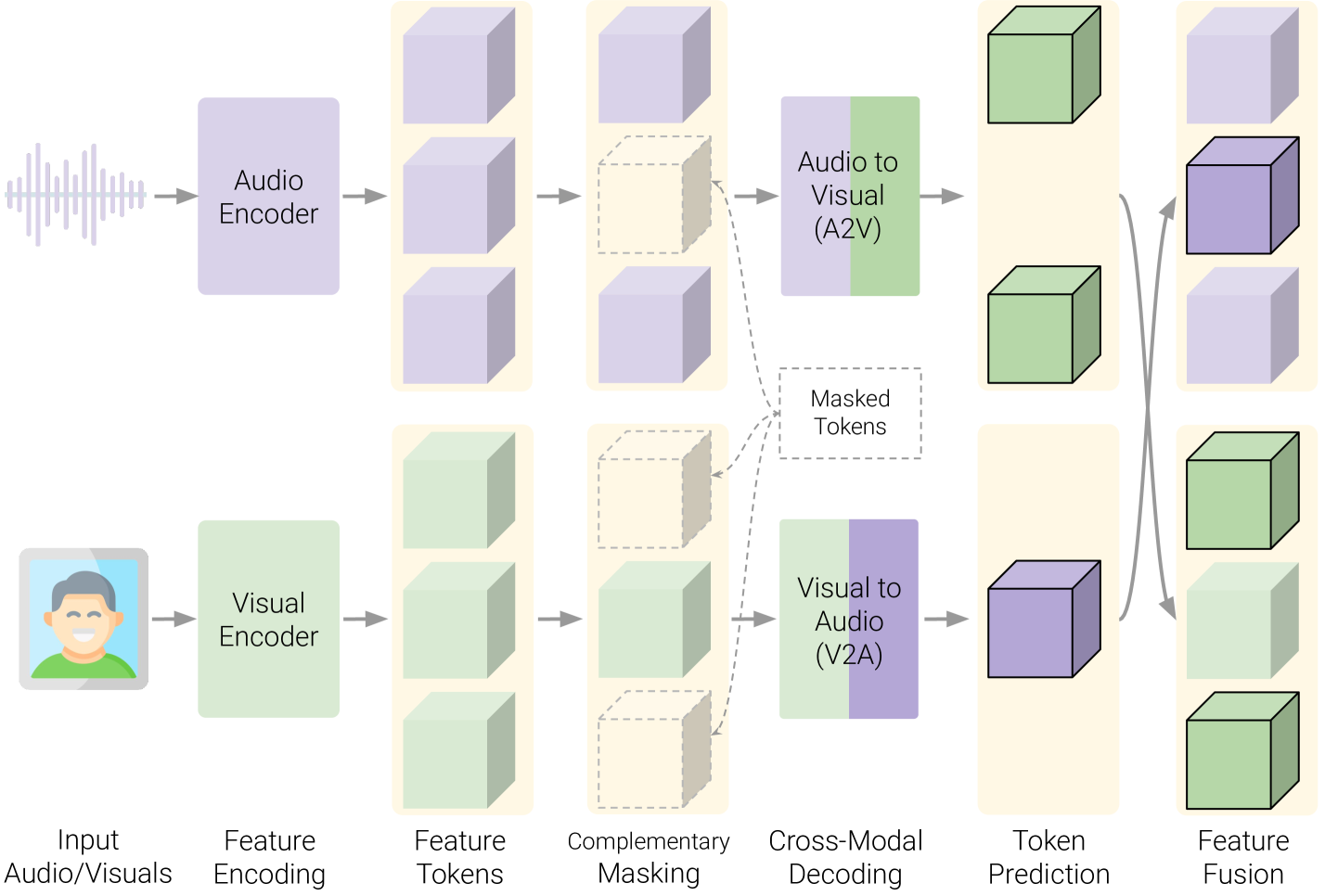
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
Read more6/6/2024
0
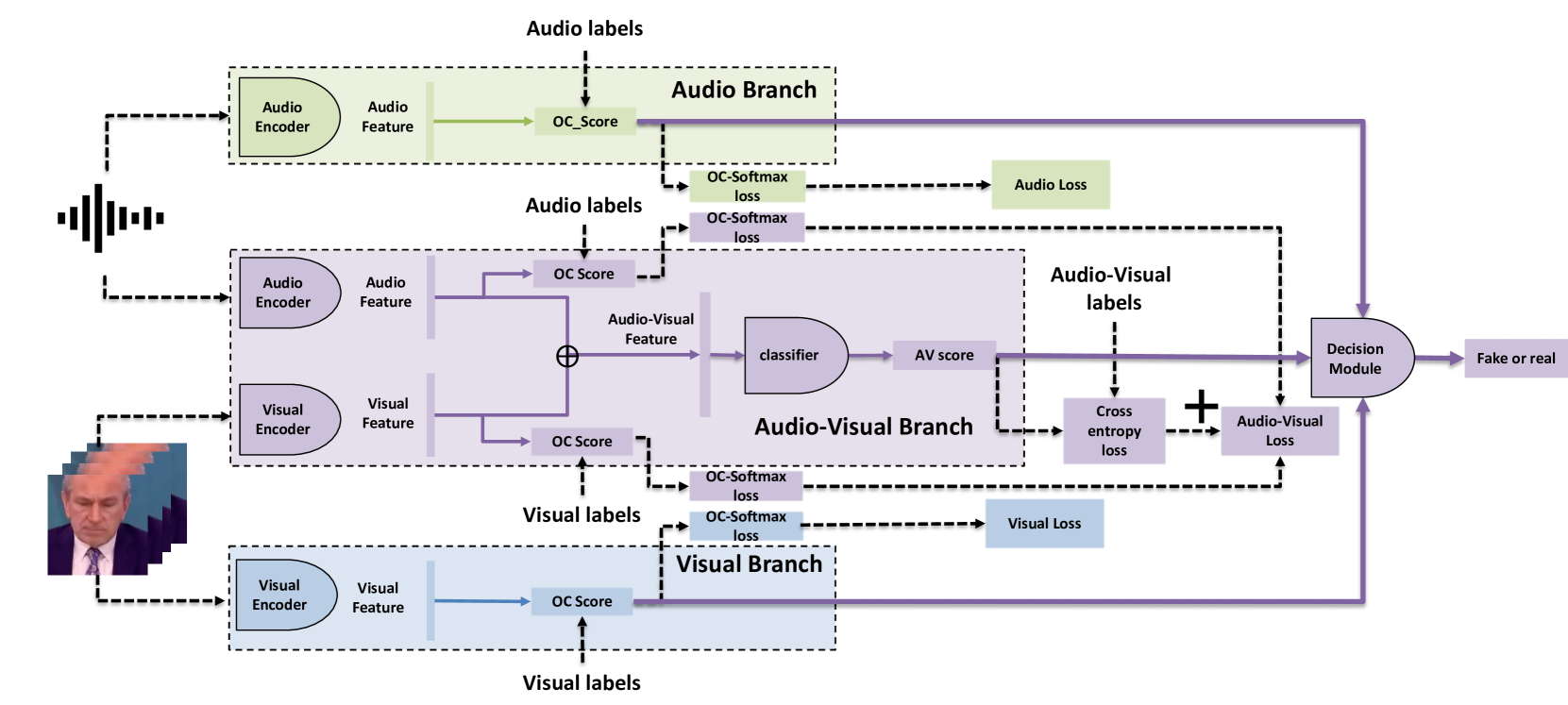
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024