Generating Analytic Specifications for Data Visualization from Natural Language Queries using Large Language Models

0

Sign in to get full access
Overview
- This paper presents NL4DV-LLM, a system that uses large language models (LLMs) to generate analytic specifications for data visualization from natural language queries.
- The key components are a prompt engineering approach and a prompt-based fine-tuning strategy to adapt LLMs for the data visualization task.
- The system is evaluated on a dataset of natural language queries and shows promising results in translating the queries into analytic specifications.
Plain English Explanation
The research paper describes a system called NL4DV-LLM that allows users to generate data visualizations from natural language queries using large language models (LLMs) like GPT-3. Large language models are AI models trained on massive amounts of text data, which enables them to understand and generate human-like language.
The key idea behind NL4DV-LLM is to leverage the language understanding capabilities of LLMs to translate natural language queries into the specific technical requirements needed to generate data visualizations. For example, if a user asks "Show me a bar chart of sales by product category," the system should be able to understand the intent and generate the necessary analytic specifications, like the data fields to use, the chart type, and the visual encoding.
The researchers developed a prompt engineering approach and a prompt-based fine-tuning strategy to adapt LLMs for this data visualization task. Prompt engineering involves carefully designing the input prompts given to the LLM to guide it towards the desired output. The fine-tuning process further tailors the LLM's capabilities to the specific domain of data visualization.
The system is evaluated on a dataset of natural language queries, and the results suggest that NL4DV-LLM can effectively translate the queries into analytic specifications for data visualization. This could make it easier for non-technical users to explore and analyze data without needing to understand the underlying technical details.
Technical Explanation
The core of the NL4DV-LLM system is a prompt engineering approach that aims to guide large language models (LLMs) to generate analytic specifications for data visualization from natural language queries. The prompt includes several key components:
- Task Description: Clearly defines the goal of translating natural language queries into analytic specifications for data visualization.
- Input Format: Specifies the format of the natural language query as the input to the system.
- Output Format: Outlines the expected format of the analytic specification as the desired output.
- Examples: Provides a few example natural language queries and their corresponding analytic specifications to help the LLM learn the mapping.
- Instructions: Gives detailed instructions to the LLM on how to approach the task, such as considering the data schema, visualization types, and visual encodings.
The researchers also propose a prompt-based fine-tuning strategy to further adapt the LLM to the data visualization domain. This involves fine-tuning the pre-trained LLM on a curated dataset of natural language queries and their analytic specifications, allowing the model to learn the task-specific patterns and capabilities.
To evaluate the system, the researchers used a dataset of natural language queries related to data visualization and compared the analytic specifications generated by NL4DV-LLM to ground truth specifications. The results show that the system can effectively translate natural language queries into appropriate analytic specifications, demonstrating the potential of using LLMs for this task.
Critical Analysis
The research presented in this paper is a promising step towards making data visualization more accessible to non-technical users through natural language interfaces. The key strengths of the NL4DV-LLM system are its ability to leverage the language understanding capabilities of large language models and the use of prompt engineering and fine-tuning to adapt these models to the specific task of data visualization.
However, the paper also acknowledges several limitations and areas for further research. One limitation is the reliance on a relatively small dataset of natural language queries, which may not fully capture the diversity of real-world queries users might have. Expanding the dataset and evaluating the system's performance on a larger and more representative set of queries would be an important next step.
Additionally, the paper does not address the potential challenges of handling complex data structures, dynamic data sources, or user-specific preferences in the generated analytic specifications. Extending the system to handle these more advanced scenarios would be an interesting direction for future work.
Another area for improvement could be the interpretability and explainability of the system's outputs. While the paper demonstrates the overall effectiveness of NL4DV-LLM, it does not provide insights into how the system arrives at its analytic specifications or how users can understand and validate the results. Incorporating explainable AI techniques could enhance the system's transparency and user trust.
Overall, this research represents a valuable contribution to the field of natural language interfaces for data visualization. By leveraging the power of large language models, the NL4DV-LLM system shows promise in bridging the gap between natural language and the technical requirements of data visualization. Further advancements in this area could greatly empower non-technical users to explore and analyze data more effectively.
Conclusion
The paper presents NL4DV-LLM, a system that uses large language models to generate analytic specifications for data visualization from natural language queries. The key innovations include a prompt engineering approach and a prompt-based fine-tuning strategy to adapt LLMs for this task.
The evaluation results demonstrate the system's effectiveness in translating natural language queries into appropriate analytic specifications, suggesting that this technology could make data visualization more accessible to a broader audience. While the research has some limitations, it represents an exciting step forward in the field of natural language interfaces for data exploration and analysis.
As LLMs continue to advance and the techniques for adapting them to specific domains improve, systems like NL4DV-LLM could play an increasingly important role in democratizing data-driven decision-making and empowering non-technical users to gain insights from complex data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generating Analytic Specifications for Data Visualization from Natural Language Queries using Large Language Models
Subham Sah, Rishab Mitra, Arpit Narechania, Alex Endert, John Stasko, Wenwen Dou
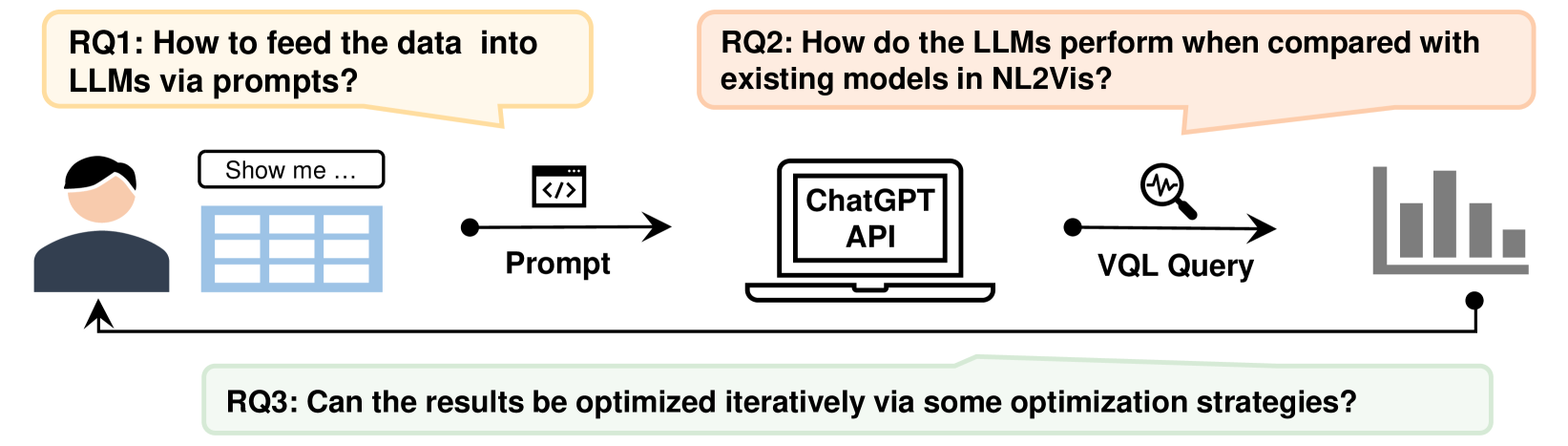
Recently, large language models (LLMs) have shown great promise in translating natural language (NL) queries into visualizations, but their black-box nature often limits explainability and debuggability. In response, we present a comprehensive text prompt that, given a tabular dataset and an NL query about the dataset, generates an analytic specification including (detected) data attributes, (inferred) analytic tasks, and (recommended) visualizations. This specification captures key aspects of the query translation process, affording both explainability and debuggability. For instance, it provides mappings from the detected entities to the corresponding phrases in the input query, as well as the specific visual design principles that determined the visualization recommendations. Moreover, unlike prior LLM-based approaches, our prompt supports conversational interaction and ambiguity detection capabilities. In this paper, we detail the iterative process of curating our prompt, present a preliminary performance evaluation using GPT-4, and discuss the strengths and limitations of LLMs at various stages of query translation. The prompt is open-source and integrated into NL4DV, a popular Python-based natural language toolkit for visualization, which can be accessed at https://nl4dv.github.io.
Read more8/28/2024
0
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Yang Wu, Yao Wan, Hongyu Zhang, Yulei Sui, Wucai Wei, Wei Zhao, Guandong Xu, Hai Jin
The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
Read more4/29/2024

0
Evaluating the Semantic Profiling Abilities of LLMs for Natural Language Utterances in Data Visualization
Hannah K. Bako, Arshnoor Bhutani, Xinyi Liu, Kwesi A. Cobbina, Zhicheng Liu
Automatically generating data visualizations in response to human utterances on datasets necessitates a deep semantic understanding of the data utterance, including implicit and explicit references to data attributes, visualization tasks, and necessary data preparation steps. Natural Language Interfaces (NLIs) for data visualization have explored ways to infer such information, yet challenges persist due to inherent uncertainty in human speech. Recent advances in Large Language Models (LLMs) provide an avenue to address these challenges, but their ability to extract the relevant semantic information remains unexplored. In this study, we evaluate four publicly available LLMs (GPT-4, Gemini-Pro, Llama3, and Mixtral), investigating their ability to comprehend utterances even in the presence of uncertainty and identify the relevant data context and visual tasks. Our findings reveal that LLMs are sensitive to uncertainties in utterances. Despite this sensitivity, they are able to extract the relevant data context. However, LLMs struggle with inferring visualization tasks. Based on these results, we highlight future research directions on using LLMs for visualization generation.
Read more7/10/2024

0
Can LLMs Generate Visualizations with Dataless Prompts?
Darius Coelho, Harshit Barot, Naitik Rathod, Klaus Mueller
Recent advancements in large language models have revolutionized information access, as these models harness data available on the web to address complex queries, becoming the preferred information source for many users. In certain cases, queries are about publicly available data, which can be effectively answered with data visualizations. In this paper, we investigate the ability of large language models to provide accurate data and relevant visualizations in response to such queries. Specifically, we investigate the ability of GPT-3 and GPT-4 to generate visualizations with dataless prompts, where no data accompanies the query. We evaluate the results of the models by comparing them to visualization cheat sheets created by visualization experts.
Read more6/27/2024