Can LLMs Generate Visualizations with Dataless Prompts?

0

Sign in to get full access
Overview
- This paper investigates whether large language models (LLMs) can generate visualizations from "dataless" prompts - prompts that do not include any data or information to be visualized.
- The researchers conducted experiments using popular LLMs like GPT-3 and DALL-E to assess their ability to generate relevant and accurate visualizations based solely on text-based prompts.
- The findings have implications for the potential of LLMs to assist in data visualization tasks without requiring structured data inputs, which could expand their applicability in various domains.
Plain English Explanation
In this study, the researchers wanted to see if large language models (LLMs) - powerful AI systems that can understand and generate human-like text - could create visual representations, like graphs or charts, just by using words as input, without needing any actual data or numbers.
Normally, to make a good data visualization, you'd need to have the underlying facts and figures. But the researchers were curious if these advanced language models could look at a simple text prompt and then automatically generate an appropriate visual that matches the meaning of the words.
For example, could an LLM take a prompt like "Trends in bicycle sales over the past 5 years" and then produce a line graph showing those sales numbers, even without being given the actual sales data? That's the kind of capability the researchers set out to explore.
They tested out popular LLMs like GPT-3 and DALL-E, giving them all sorts of different textual prompts and seeing what kinds of visualizations the models would create in response. The results provide insight into the potential for LLMs to assist with data visualization tasks in the future, without requiring the same level of structured data that is typically needed today.
Technical Explanation
The researchers conducted a series of experiments to evaluate whether large language models (LLMs) like GPT-3 and DALL-E could generate relevant and accurate data visualizations based solely on "dataless" textual prompts, without access to any underlying data or information.
They curated a diverse set of prompts covering a wide range of topics, including business, science, and social issues. These prompts did not contain any numerical data or quantitative information, but rather described scenarios or concepts in natural language.
The researchers then used the LLMs to generate images in response to these prompts, assessing the quality, relevance, and accuracy of the resulting visualizations through both human evaluation and automated metrics. They also explored different prompt engineering techniques to optimize the LLMs' performance on this task.
The findings suggest that while current LLMs can produce relevant and aesthetically pleasing visualizations from dataless prompts, they still struggle to generate visualizations that accurately reflect the intended meaning and data represented in the prompt. The models tend to produce visualizations that are plausible but not necessarily truthful or aligned with the prompt.
The researchers discuss the implications of these results for the potential of LLMs to assist in data visualization tasks, noting that while the technology shows promise, further advancements are needed to reliably produce visualizations that faithfully represent the underlying data and concepts described in the input prompt.
Critical Analysis
The research presented in this paper represents an interesting and valuable exploration of the capabilities of large language models (LLMs) in the domain of data visualization. By testing the models' ability to generate relevant visualizations from "dataless" prompts, the researchers have shed light on both the potential and the limitations of this approach.
One key strength of the study is its comprehensive and diverse set of prompts, which cover a wide range of topics and scenarios. This helps to evaluate the LLMs' performance in a broad context, rather than focusing on a narrow or specialized domain.
However, the researchers acknowledge that the models still struggle to produce visualizations that accurately reflect the intended meaning and data represented in the prompts. This suggests that while LLMs may be able to generate plausible-looking visualizations, they often fail to capture the nuances and specifics of the underlying concepts.
Additionally, the paper does not delve deeply into the potential reasons for these limitations, such as the models' understanding of data structures, their ability to reason about quantitative relationships, or their knowledge of visualization best practices. Further research in these areas could help identify the key bottlenecks and guide future improvements.
It's also worth considering the potential biases and limitations of the human evaluation process used in the study. While the researchers employed multiple raters and metrics, the subjective nature of visual perception and interpretation could still introduce some bias or inconsistency into the assessments.
Overall, this paper represents an important step in exploring the potential of LLMs to assist with data visualization tasks. While the current results highlight the limitations of this approach, the researchers have laid the groundwork for future investigations that could uncover more advanced techniques and capabilities in this domain.
Conclusion
This study explored the ability of large language models (LLMs) to generate relevant and accurate data visualizations based solely on textual prompts, without access to any underlying data or information. The researchers found that while current LLMs can produce visually pleasing and plausible-looking visualizations, they still struggle to generate representations that faithfully reflect the intended meaning and data described in the prompts.
The findings suggest that while LLMs show promise in assisting with data visualization tasks, further advancements are needed to reliably produce visualizations that align with the actual concepts and information conveyed in the input prompts. As the researchers note, this could have important implications for expanding the applicability of LLMs in various domains, where the ability to generate relevant and truthful visualizations from textual descriptions could be highly valuable.
Overall, this study represents an important step in exploring the potential and limitations of LLMs in the field of data visualization, and it lays the groundwork for future research that could uncover more advanced techniques and capabilities in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can LLMs Generate Visualizations with Dataless Prompts?
Darius Coelho, Harshit Barot, Naitik Rathod, Klaus Mueller
Recent advancements in large language models have revolutionized information access, as these models harness data available on the web to address complex queries, becoming the preferred information source for many users. In certain cases, queries are about publicly available data, which can be effectively answered with data visualizations. In this paper, we investigate the ability of large language models to provide accurate data and relevant visualizations in response to such queries. Specifically, we investigate the ability of GPT-3 and GPT-4 to generate visualizations with dataless prompts, where no data accompanies the query. We evaluate the results of the models by comparing them to visualization cheat sheets created by visualization experts.
Read more6/27/2024

0
Generating Analytic Specifications for Data Visualization from Natural Language Queries using Large Language Models
Subham Sah, Rishab Mitra, Arpit Narechania, Alex Endert, John Stasko, Wenwen Dou
Recently, large language models (LLMs) have shown great promise in translating natural language (NL) queries into visualizations, but their black-box nature often limits explainability and debuggability. In response, we present a comprehensive text prompt that, given a tabular dataset and an NL query about the dataset, generates an analytic specification including (detected) data attributes, (inferred) analytic tasks, and (recommended) visualizations. This specification captures key aspects of the query translation process, affording both explainability and debuggability. For instance, it provides mappings from the detected entities to the corresponding phrases in the input query, as well as the specific visual design principles that determined the visualization recommendations. Moreover, unlike prior LLM-based approaches, our prompt supports conversational interaction and ambiguity detection capabilities. In this paper, we detail the iterative process of curating our prompt, present a preliminary performance evaluation using GPT-4, and discuss the strengths and limitations of LLMs at various stages of query translation. The prompt is open-source and integrated into NL4DV, a popular Python-based natural language toolkit for visualization, which can be accessed at https://nl4dv.github.io.
Read more8/28/2024

0
Evaluating the Semantic Profiling Abilities of LLMs for Natural Language Utterances in Data Visualization
Hannah K. Bako, Arshnoor Bhutani, Xinyi Liu, Kwesi A. Cobbina, Zhicheng Liu
Automatically generating data visualizations in response to human utterances on datasets necessitates a deep semantic understanding of the data utterance, including implicit and explicit references to data attributes, visualization tasks, and necessary data preparation steps. Natural Language Interfaces (NLIs) for data visualization have explored ways to infer such information, yet challenges persist due to inherent uncertainty in human speech. Recent advances in Large Language Models (LLMs) provide an avenue to address these challenges, but their ability to extract the relevant semantic information remains unexplored. In this study, we evaluate four publicly available LLMs (GPT-4, Gemini-Pro, Llama3, and Mixtral), investigating their ability to comprehend utterances even in the presence of uncertainty and identify the relevant data context and visual tasks. Our findings reveal that LLMs are sensitive to uncertainties in utterances. Despite this sensitivity, they are able to extract the relevant data context. However, LLMs struggle with inferring visualization tasks. Based on these results, we highlight future research directions on using LLMs for visualization generation.
Read more7/10/2024
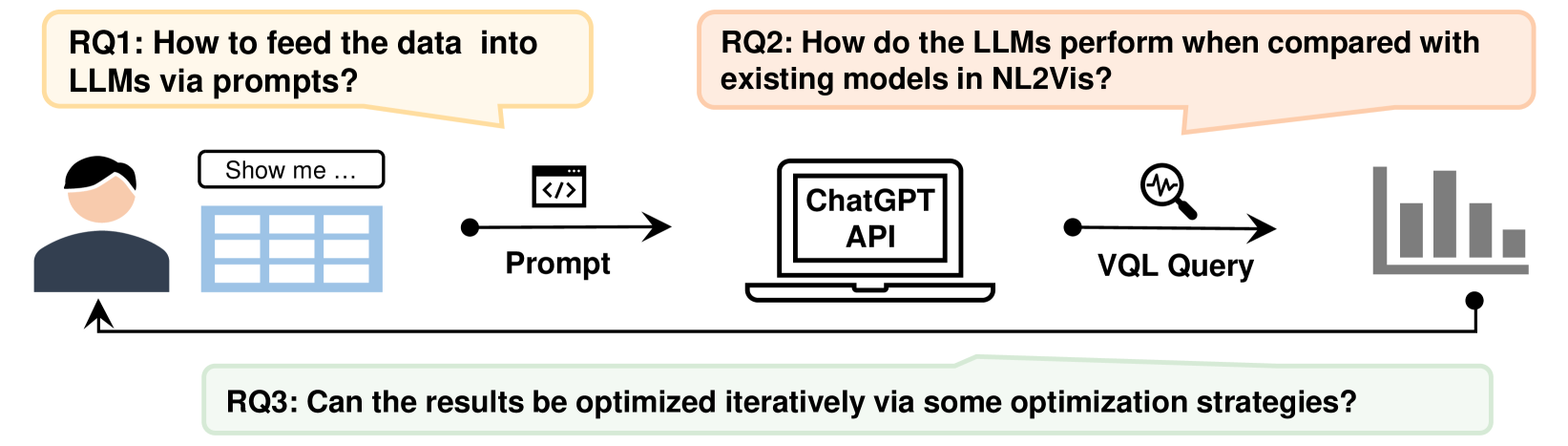
0
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Yang Wu, Yao Wan, Hongyu Zhang, Yulei Sui, Wucai Wei, Wei Zhao, Guandong Xu, Hai Jin
The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
Read more4/29/2024