Generating Binary Species Range Maps

0

Sign in to get full access
Overview
- This paper proposes a method for generating binary species range maps from species occurrence data.
- The method involves using a thresholding algorithm to convert probability maps into binary range maps.
- The authors evaluate their approach on several datasets and compare it to existing methods.
Plain English Explanation
The paper is about creating maps that show where different species of plants or animals live. To do this, the researchers start with data about where those species have been observed. They then use a special algorithm to turn that data into a map that clearly shows the likely range or habitat of each species.
The key steps are:
- Taking the raw observation data and using it to create a probability map that shows the likelihood of finding the species in different areas.
- Applying a thresholding process to the probability map to convert it into a simple binary map that just shows whether the species is present or absent in each location.
This binary map represents the estimated range or habitat of the species. The researchers tested their method on several different datasets and compared the results to other approaches for creating species range maps.
Technical Explanation
The core of the paper's method is a thresholding algorithm that converts probability maps into binary range maps. The authors start with species occurrence data, which they use to generate a continuous probability map indicating the likelihood of finding the species in different locations.
They then apply a thresholding algorithm to this probability map to create a binary map that simply shows whether the species is present or absent in each grid cell. This binary map represents the estimated habitat or range of the species.
The authors experiment with different thresholding approaches, including fixed thresholds and adaptive thresholds that adjust based on characteristics of the probability map. They evaluate their method on several real-world datasets and compare the results to existing techniques for generating species range maps.
Critical Analysis
The paper provides a straightforward and practical approach for converting species observation data into binary range maps. The thresholding method is intuitive and the authors demonstrate its effectiveness on multiple datasets.
However, the paper does not address some potential limitations or caveats of the approach. For example, the binary maps may oversimplify the true habitat, which could vary in suitability across the range. The authors also do not discuss how their method might perform on sparse or noisy observation data, which is common in many real-world scenarios.
Additionally, the paper focuses solely on evaluating the range maps themselves, without considering how these maps might be used in downstream applications like conservation planning or ecological modeling. Further research could explore the utility of these binary range maps in practice.
Conclusion
This paper presents a straightforward algorithm for generating binary species range maps from observation data. While the approach has some limitations, it provides a useful tool for quickly and easily visualizing the likely habitats of different species. The binary maps produced by this method could support a variety of ecological applications, from identifying priority conservation areas to modeling species interactions and responses to environmental change.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generating Binary Species Range Maps
Filip Dorm, Christian Lange, Scott Loarie, Oisin Mac Aodha
Accurately predicting the geographic ranges of species is crucial for assisting conservation efforts. Traditionally, range maps were manually created by experts. However, species distribution models (SDMs) and, more recently, deep learning-based variants offer a potential automated alternative. Deep learning-based SDMs generate a continuous probability representing the predicted presence of a species at a given location, which must be binarized by setting per-species thresholds to obtain binary range maps. However, selecting appropriate per-species thresholds to binarize these predictions is non-trivial as different species can require distinct thresholds. In this work, we evaluate different approaches for automatically identifying the best thresholds for binarizing range maps using presence-only data. This includes approaches that require the generation of additional pseudo-absence data, along with ones that only require presence data. We also propose an extension of an existing presence-only technique that is more robust to outliers. We perform a detailed evaluation of different thresholding techniques on the tasks of binary range estimation and large-scale fine-grained visual classification, and we demonstrate improved performance over existing pseudo-absence free approaches using our method.
Read more8/29/2024

0
GeoPlant: Spatial Plant Species Prediction Dataset
Lukas Picek, Christophe Botella, Maximilien Servajean, C'esar Leblanc, R'emi Palard, Th'eo Larcher, Benjamin Deneu, Diego Marcos, Pierre Bonnet, Alexis Joly
The difficulty of monitoring biodiversity at fine scales and over large areas limits ecological knowledge and conservation efforts. To fill this gap, Species Distribution Models (SDMs) predict species across space from spatially explicit features. Yet, they face the challenge of integrating the rich but heterogeneous data made available over the past decade, notably millions of opportunistic species observations and standardized surveys, as well as multi-modal remote sensing data. In light of that, we have designed and developed a new European-scale dataset for SDMs at high spatial resolution (10-50 m), including more than 10k species (i.e., most of the European flora). The dataset comprises 5M heterogeneous Presence-Only records and 90k exhaustive Presence-Absence survey records, all accompanied by diverse environmental rasters (e.g., elevation, human footprint, and soil) that are traditionally used in SDMs. In addition, it provides Sentinel-2 RGB and NIR satellite images with 10 m resolution, a 20-year time-series of climatic variables, and satellite time-series from the Landsat program. In addition to the data, we provide an openly accessible SDM benchmark (hosted on Kaggle), which has already attracted an active community and a set of strong baselines for single predictor/modality and multimodal approaches. All resources, e.g., the dataset, pre-trained models, and baseline methods (in the form of notebooks), are available on Kaggle, allowing one to start with our dataset literally with two mouse clicks.
Read more8/27/2024

0
Machine Learning Models for Improved Tracking from Range-Doppler Map Images
Elizabeth Hou, Ross Greenwood, Piyush Kumar
Statistical tracking filters depend on accurate target measurements and uncertainty estimates for good tracking performance. In this work, we propose novel machine learning models for target detection and uncertainty estimation in range-Doppler map (RDM) images for Ground Moving Target Indicator (GMTI) radars. We show that by using the outputs of these models, we can significantly improve the performance of a multiple hypothesis tracker for complex multi-target air-to-ground tracking scenarios.
Read more7/4/2024
0
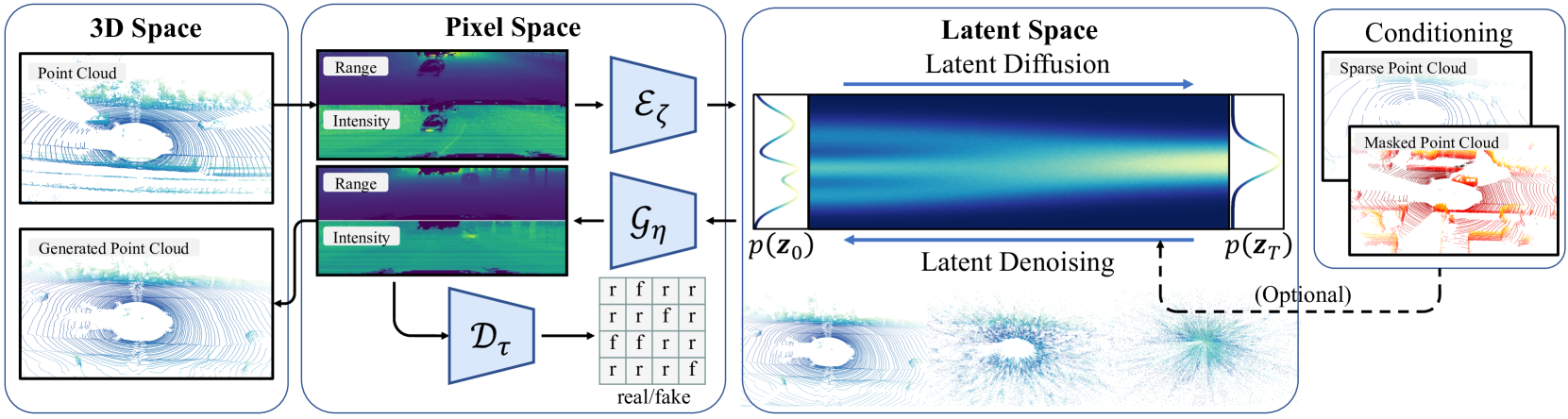
RangeLDM: Fast Realistic LiDAR Point Cloud Generation
Qianjiang Hu, Zhimin Zhang, Wei Hu
Autonomous driving demands high-quality LiDAR data, yet the cost of physical LiDAR sensors presents a significant scaling-up challenge. While recent efforts have explored deep generative models to address this issue, they often consume substantial computational resources with slow generation speeds while suffering from a lack of realism. To address these limitations, we introduce RangeLDM, a novel approach for rapidly generating high-quality range-view LiDAR point clouds via latent diffusion models. We achieve this by correcting range-view data distribution for accurate projection from point clouds to range images via Hough voting, which has a critical impact on generative learning. We then compress the range images into a latent space with a variational autoencoder, and leverage a diffusion model to enhance expressivity. Additionally, we instruct the model to preserve 3D structural fidelity by devising a range-guided discriminator. Experimental results on KITTI-360 and nuScenes datasets demonstrate both the robust expressiveness and fast speed of our LiDAR point cloud generation.
Read more9/11/2024