On Subjective Uncertainty Quantification and Calibration in Natural Language Generation
2406.05213
0
0
Abstract
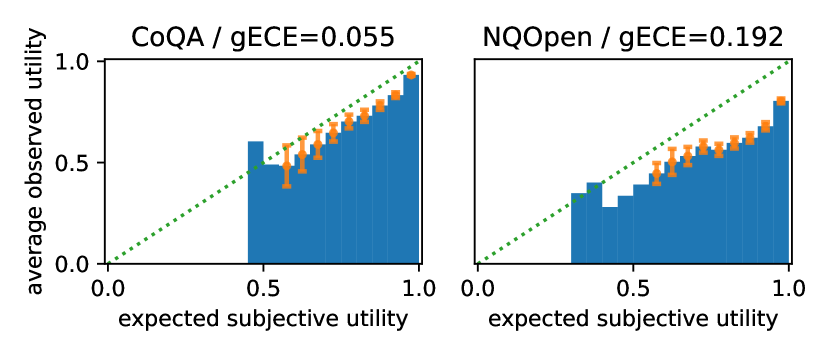
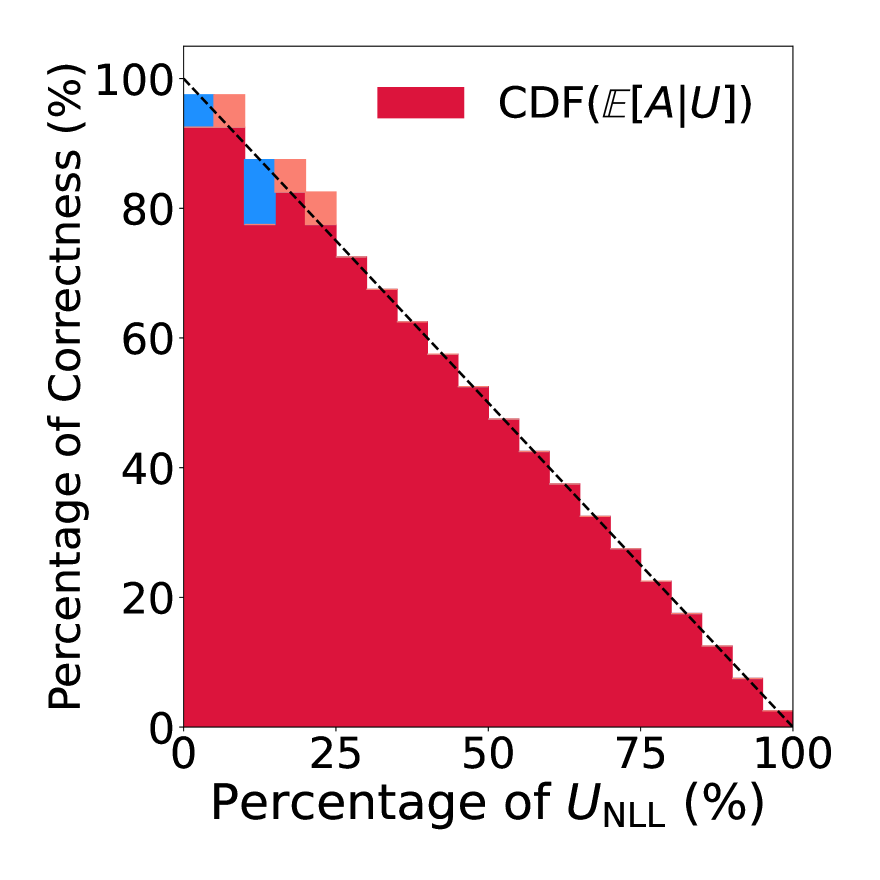
Applications of large language models often involve the generation of free-form responses, in which case uncertainty quantification becomes challenging. This is due to the need to identify task-specific uncertainties (e.g., about the semantics) which appears difficult to define in general cases. This work addresses these challenges from a perspective of Bayesian decision theory, starting from the assumption that our utility is characterized by a similarity measure that compares a generated response with a hypothetical true response. We discuss how this assumption enables principled quantification of the model's subjective uncertainty and its calibration. We further derive a measure for epistemic uncertainty, based on a missing data perspective and its characterization as an excess risk. The proposed measures can be applied to black-box language models. We demonstrate the proposed methods on question answering and machine translation tasks, where they extract broadly meaningful uncertainty estimates from GPT and Gemini models and quantify their calibration.
Create account to get full access
Overview
- This paper explores the challenge of quantifying and calibrating subjective uncertainty in natural language generation (NLG) models.
- It investigates techniques to assess the reliability and trustworthiness of the uncertainty estimates produced by these models.
- The research aims to improve the transparency and interpretability of NLG systems, which is crucial for their safe and effective deployment.
Plain English Explanation
Natural language generation (NLG) models are AI systems that can produce human-like text, such as summaries, stories, or answers to questions. However, these models don't always know how confident they are in the text they generate. <a href="https://aimodels.fyi/papers/arxiv/generating-confidence-uncertainty-quantification-black-box-large">This can lead to issues if the model's output is used for important decisions without understanding its reliability</a>.
The researchers in this paper looked at ways to quantify and "calibrate" the uncertainty of NLG models. Calibration means ensuring that the model's estimated uncertainty matches the actual accuracy of its predictions. For example, if the model says it's 80% confident in its output, the output should be correct 80% of the time.
By developing better ways to measure and calibrate uncertainty, the researchers aim to make NLG systems more transparent and trustworthy. <a href="https://aimodels.fyi/papers/arxiv/to-believe-or-not-to-believe-your">This is crucial as these models are increasingly used in high-stakes applications like medical diagnosis or financial planning</a>, where it's important to understand the model's limitations and confidence levels.
Technical Explanation
The researchers explored several techniques to quantify and calibrate the subjective uncertainty in NLG models:
-
Uncertainty Quantification: They investigated different metrics, such as <a href="https://aimodels.fyi/papers/arxiv/uncertainty-language-models-assessment-through-rank-calibration">rank calibration</a> and <a href="https://aimodels.fyi/papers/arxiv/semantic-density-uncertainty-quantification-semantic-space-large">semantic density</a>, to measure the model's uncertainty in its generated text.
-
Uncertainty Calibration: The researchers explored techniques to adjust the model's uncertainty estimates to match the actual accuracy of its predictions. This involved methods like temperature scaling and Platt scaling.
-
Evaluation: The researchers designed experiments to assess the effectiveness of their uncertainty quantification and calibration approaches. They used both automatic metrics and human evaluations to gauge the reliability and interpretability of the models' uncertainty estimates.
Critical Analysis
The paper provides a thorough investigation of the challenges in quantifying and calibrating subjective uncertainty in NLG models. The researchers acknowledge that their techniques are not perfect and that further research is needed, especially in <a href="https://aimodels.fyi/papers/arxiv/epistemic-uncertainty-quantification-pre-trained-neural-network">addressing the epistemic uncertainty</a> (uncertainty about the model's own knowledge) in these systems.
One potential limitation is that the experiments were conducted on a relatively narrow set of NLG tasks and datasets. Expanding the evaluation to a wider range of applications and scenarios could provide a more comprehensive understanding of the strengths and weaknesses of the proposed methods.
Additionally, the paper focuses on improving the transparency and interpretability of uncertainty estimates, but it does not delve into the potential ethical implications of deploying these calibrated NLG systems in high-stakes decision-making contexts. Further research on the societal impact and responsible use of these technologies would be valuable.
Conclusion
This paper makes important contributions to the field of uncertainty quantification and calibration in natural language generation. By developing techniques to better measure and adjust the subjective uncertainty of NLG models, the researchers are helping to improve the transparency and trustworthiness of these systems.
As NLG models become more widely adopted, especially in safety-critical applications, the ability to understand and communicate their limitations is crucial. The insights from this research can pave the way for more reliable and interpretable natural language generation, with significant implications for the responsible development and deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024

To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
0
0
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
6/5/2024
Uncertainty in Language Models: Assessment through Rank-Calibration
Xinmeng Huang, Shuo Li, Mengxin Yu, Matteo Sesia, Hamed Hassani, Insup Lee, Osbert Bastani, Edgar Dobriban
0
0
Language Models (LMs) have shown promising performance in natural language generation. However, as LMs often generate incorrect or hallucinated responses, it is crucial to correctly quantify their uncertainty in responding to given inputs. In addition to verbalized confidence elicited via prompting, many uncertainty measures ($e.g.$, semantic entropy and affinity-graph-based measures) have been proposed. However, these measures can differ greatly, and it is unclear how to compare them, partly because they take values over different ranges ($e.g.$, $[0,infty)$ or $[0,1]$). In this work, we address this issue by developing a novel and practical framework, termed $Rank$-$Calibration$, to assess uncertainty and confidence measures for LMs. Our key tenet is that higher uncertainty (or lower confidence) should imply lower generation quality, on average. Rank-calibration quantifies deviations from this ideal relationship in a principled manner, without requiring ad hoc binary thresholding of the correctness score ($e.g.$, ROUGE or METEOR). The broad applicability and the granular interpretability of our methods are demonstrated empirically.
4/5/2024
💬
Semantic Density: Uncertainty Quantification in Semantic Space for Large Language Models
Xin Qiu, Risto Miikkulainen
0
0
With the widespread application of Large Language Models (LLMs) to various domains, concerns regarding the trustworthiness of LLMs in safety-critical scenarios have been raised, due to their unpredictable tendency to hallucinate and generate misinformation. Existing LLMs do not have an inherent functionality to provide the users with an uncertainty metric for each response it generates, making it difficult to evaluate trustworthiness. Although a number of works aim to develop uncertainty quantification methods for LLMs, they have fundamental limitations, such as being restricted to classification tasks, requiring additional training and data, considering only lexical instead of semantic information, and being prompt-wise but not response-wise. A new framework is proposed in this paper to address these issues. Semantic density extracts uncertainty information for each response from a probability distribution perspective in semantic space. It has no restriction on task types and is off-the-shelf for new models and tasks. Experiments on seven state-of-the-art LLMs, including the latest Llama 3 and Mixtral-8x22B models, on four free-form question-answering benchmarks demonstrate the superior performance and robustness of semantic density compared to prior approaches.
5/28/2024