Seeing Is Believing: Black-Box Membership Inference Attacks Against Retrieval Augmented Generation

0
Sign in to get full access
Overview
- This paper explores "black-box membership inference attacks" against retrieval-augmented language models, which are AI systems that combine a large language model with a retrieval component to improve their performance.
- The researchers demonstrate how an attacker can determine whether a specific input was used to train the retrieval component, even if the attacker has no access to the training data or model architecture.
- This type of attack raises privacy concerns, as it could allow attackers to infer sensitive information about the data used to train language models.
Plain English Explanation
The paper discusses a security vulnerability in retrieval-augmented language models, which are AI systems that combine a large language model with a retrieval component. These models are designed to improve their performance by accessing additional information from a database or knowledge base.
The researchers show that even if an attacker doesn't have access to the training data or the inner workings of the model, they can still determine whether a specific input was used to train the retrieval component. This is known as a "black-box membership inference attack."
Imagine you have a friend who is really good at trivia. They can quickly provide accurate answers to your questions by accessing a huge database of information. An attacker could try to figure out which specific pieces of information your friend has access to, even without seeing the database itself. This is similar to what the researchers demonstrate in the paper.
This type of attack raises privacy concerns, as it could allow attackers to infer sensitive information about the data used to train language models. For example, if the model was trained on a dataset containing personal information, an attacker might be able to determine which individuals were included in the dataset.
Technical Explanation
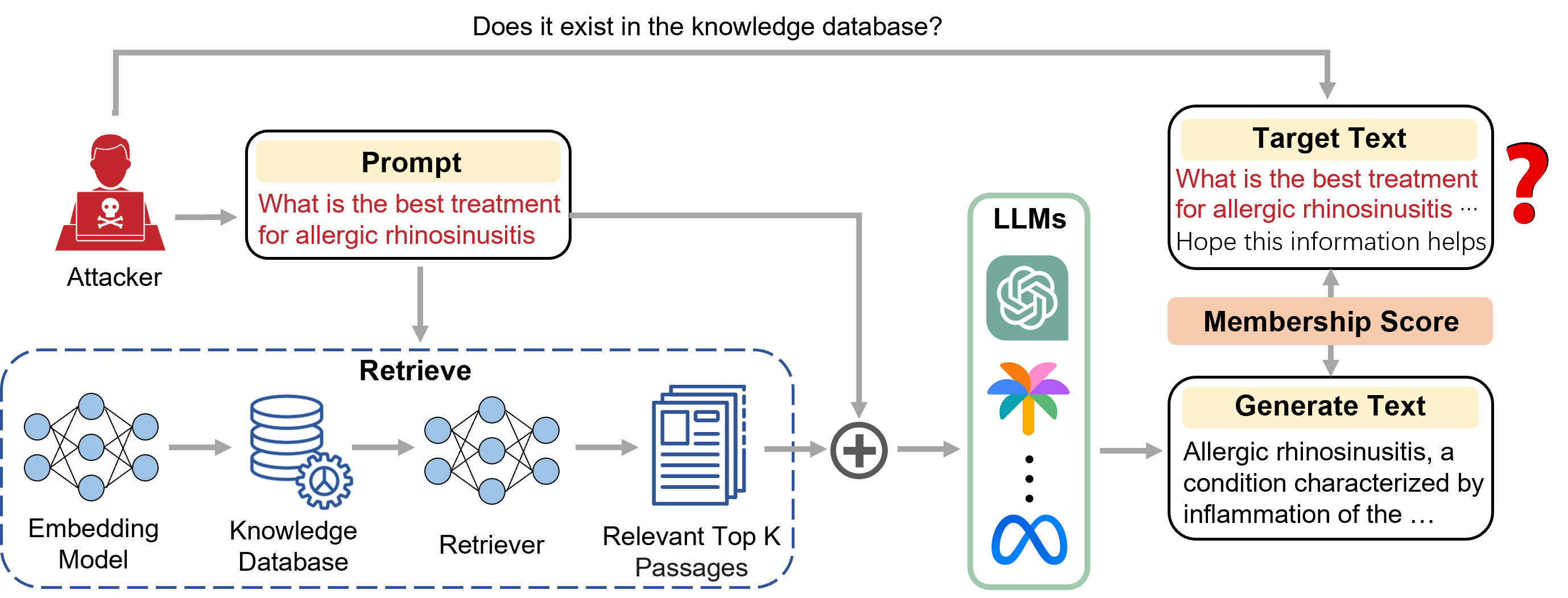
The paper presents a black-box membership inference attack against retrieval-augmented generation (RAG) models, which combine a large language model with a retrieval component to improve their performance on various tasks.
The researchers develop a novel attack framework that leverages the distinctive patterns in the model's outputs to infer whether a given input was part of the training data for the retrieval component. The attack works even when the attacker has no access to the model's architecture, training data, or internal parameters.
The attack involves two key steps:
- Generating Candidate Inputs: The attacker generates a set of candidate inputs, some of which may have been used to train the retrieval component.
- Membership Inference: The attacker then queries the target RAG model with the candidate inputs and analyzes the model's outputs to determine which inputs are more likely to have been part of the training data.
The researchers evaluate their attack on several RAG model variants and demonstrate its effectiveness in correctly identifying membership for a significant portion of the tested inputs.
The paper also discusses potential countermeasures, such as differentially private training of the retrieval component, that could help mitigate the impact of these attacks.
Critical Analysis
The paper provides a thorough and well-designed study of black-box membership inference attacks against retrieval-augmented generation models. The researchers have demonstrated a novel and effective attack that raises important privacy concerns for these types of AI systems.
One potential limitation of the study is that it focuses on a specific type of retrieval-augmented model (RAG) and may not generalize to other architectures or ways of integrating retrieval components. Additionally, the researchers only evaluated their attack on a single dataset, and it would be valuable to see how it performs on a wider range of data and model configurations.
Further research could also explore the effectiveness of the proposed countermeasures, such as differentially private training, in mitigating these types of attacks. It would be interesting to see how these defenses impact the overall performance and utility of the retrieval-augmented models.
Overall, this paper makes a valuable contribution to the understanding of privacy risks in retrieval-augmented language models and highlights the importance of continued research in this area to ensure the responsible development and deployment of these technologies.
Conclusion
This paper presents a concerning security vulnerability in retrieval-augmented language models, demonstrating how an attacker can infer whether a specific input was used to train the retrieval component, even without access to the model's architecture or training data.
The findings raise important privacy concerns, as these attacks could allow attackers to uncover sensitive information about the data used to train language models. The paper also discusses potential countermeasures, such as differentially private training, that could help mitigate the impact of these attacks.
As retrieval-augmented models become more widely adopted, it will be crucial for researchers and developers to continue exploring these types of privacy and security challenges to ensure the responsible and ethical deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Seeing Is Believing: Black-Box Membership Inference Attacks Against Retrieval Augmented Generation
Yuying Li, Gaoyang Liu, Chen Wang, Yang Yang
Retrieval-Augmented Generation (RAG) is a state-of-the-art technique that mitigates issues such as hallucinations and knowledge staleness in Large Language Models (LLMs) by retrieving relevant knowledge from an external database to assist in content generation. Existing research has demonstrated potential privacy risks associated with the LLMs of RAG. However, the privacy risks posed by the integration of an external database, which often contains sensitive data such as medical records or personal identities, have remained largely unexplored. In this paper, we aim to bridge this gap by focusing on membership privacy of RAG's external database, with the aim of determining whether a given sample is part of the RAG's database. Our basic idea is that if a sample is in the external database, it will exhibit a high degree of semantic similarity to the text generated by the RAG system. We present S$^2$MIA, a underline{M}embership underline{I}nference underline{A}ttack that utilizes the underline{S}emantic underline{S}imilarity between a given sample and the content generated by the RAG system. With our proposed S$^2$MIA, we demonstrate the potential to breach the membership privacy of the RAG database. Extensive experiment results demonstrate that S$^2$MIA can achieve a strong inference performance compared with five existing MIAs, and is able to escape from the protection of three representative defenses.
Read more9/27/2024

0
Is My Data in Your Retrieval Database? Membership Inference Attacks Against Retrieval Augmented Generation
Maya Anderson, Guy Amit, Abigail Goldsteen
Retrieval Augmented Generation (RAG) systems have shown great promise in natural language processing. However, their reliance on data stored in a retrieval database, which may contain proprietary or sensitive information, introduces new privacy concerns. Specifically, an attacker may be able to infer whether a certain text passage appears in the retrieval database by observing the outputs of the RAG system, an attack known as a Membership Inference Attack (MIA). Despite the significance of this threat, MIAs against RAG systems have yet remained under-explored. This study addresses this gap by introducing an efficient and easy-to-use method for conducting MIA against RAG systems. We demonstrate the effectiveness of our attack using two benchmark datasets and multiple generative models, showing that the membership of a document in the retrieval database can be efficiently determined through the creation of an appropriate prompt in both black-box and gray-box settings. Moreover, we introduce an initial defense strategy based on adding instructions to the RAG template, which shows high effectiveness for some datasets and models. Our findings highlight the importance of implementing security countermeasures in deployed RAG systems and developing more advanced defenses to protect the privacy and security of retrieval databases.
Read more6/10/2024

0
Black-Box Opinion Manipulation Attacks to Retrieval-Augmented Generation of Large Language Models
Zhuo Chen, Jiawei Liu, Haotan Liu, Qikai Cheng, Fan Zhang, Wei Lu, Xiaozhong Liu
Retrieval-Augmented Generation (RAG) is applied to solve hallucination problems and real-time constraints of large language models, but it also induces vulnerabilities against retrieval corruption attacks. Existing research mainly explores the unreliability of RAG in white-box and closed-domain QA tasks. In this paper, we aim to reveal the vulnerabilities of Retrieval-Enhanced Generative (RAG) models when faced with black-box attacks for opinion manipulation. We explore the impact of such attacks on user cognition and decision-making, providing new insight to enhance the reliability and security of RAG models. We manipulate the ranking results of the retrieval model in RAG with instruction and use these results as data to train a surrogate model. By employing adversarial retrieval attack methods to the surrogate model, black-box transfer attacks on RAG are further realized. Experiments conducted on opinion datasets across multiple topics show that the proposed attack strategy can significantly alter the opinion polarity of the content generated by RAG. This demonstrates the model's vulnerability and, more importantly, reveals the potential negative impact on user cognition and decision-making, making it easier to mislead users into accepting incorrect or biased information.
Read more7/19/2024

0
BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models
Jiaqi Xue, Mengxin Zheng, Yebowen Hu, Fei Liu, Xun Chen, Qian Lou
Large Language Models (LLMs) are constrained by outdated information and a tendency to generate incorrect data, commonly referred to as hallucinations. Retrieval-Augmented Generation (RAG) addresses these limitations by combining the strengths of retrieval-based methods and generative models. This approach involves retrieving relevant information from a large, up-to-date dataset and using it to enhance the generation process, leading to more accurate and contextually appropriate responses. Despite its benefits, RAG introduces a new attack surface for LLMs, particularly because RAG databases are often sourced from public data, such as the web. In this paper, we propose TrojRAG{} to identify the vulnerabilities and attacks on retrieval parts (RAG database) and their indirect attacks on generative parts (LLMs). Specifically, we identify that poisoning several customized content passages could achieve a retrieval backdoor, where the retrieval works well for clean queries but always returns customized poisoned adversarial queries. Triggers and poisoned passages can be highly customized to implement various attacks. For example, a trigger could be a semantic group like The Republican Party, Donald Trump, etc. Adversarial passages can be tailored to different contents, not only linked to the triggers but also used to indirectly attack generative LLMs without modifying them. These attacks can include denial-of-service attacks on RAG and semantic steering attacks on LLM generations conditioned by the triggers. Our experiments demonstrate that by just poisoning 10 adversarial passages can induce 98.2% success rate to retrieve the adversarial passages. Then, these passages can increase the reject ratio of RAG-based GPT-4 from 0.01% to 74.6% or increase the rate of negative responses from 0.22% to 72% for targeted queries.
Read more6/7/2024