Black-Box Opinion Manipulation Attacks to Retrieval-Augmented Generation of Large Language Models

0

Sign in to get full access
Overview
- This paper explores how attackers can manipulate the opinions of large language models (LLMs) that use retrieval-augmented generation (RAG) techniques.
- The researchers develop a black-box attack method that can subtly shift the model's opinions on sensitive topics without being detected.
- The paper demonstrates the vulnerability of RAG-based LLMs to these types of attacks, which could have significant real-world consequences.
Plain English Explanation
Large language models (LLMs) have become incredibly powerful at generating human-like text on a wide range of topics. Many of these models, like GPT-3, use a technique called retrieval-augmented generation (RAG) to enhance their capabilities.
RAG-based LLMs work by not only generating original text, but also retrieving and incorporating relevant information from a knowledge base. This allows them to provide more detailed and informed responses. However, this added capability also introduces new vulnerabilities that malicious actors can exploit.
In this paper, the researchers develop a "black-box" attack method that can subtly manipulate the opinions of RAG-based LLMs on sensitive topics, such as politics or social issues. By carefully crafting prompts, the attackers can nudge the model's outputs in a desired direction without the model's users being aware of the manipulation.
This type of attack could have serious real-world consequences, as it could allow bad actors to sway public opinion, spread misinformation, or undermine trust in important institutions. The findings of this paper highlight the need for continued research into the security and robustness of large language models, especially as they become more widely adopted in high-stakes applications.
Technical Explanation
The researchers propose a black-box attack method that exploits the vulnerabilities of retrieval-augmented generation (RAG) in large language models (LLMs). RAG-based LLMs, such as those described in the Retrieval-Augmented Generation for Natural Language Processing survey, combine language generation with information retrieval to enhance the quality and coherence of their outputs.
The key insight of the attack is that the retrieval component of RAG-based LLMs can be manipulated to subtly shift the model's opinions on sensitive topics. By crafting prompts that trigger the retrieval of specific information, the attackers can nudge the model's outputs in a desired direction without being detected.
The researchers demonstrate the effectiveness of their attack through a series of experiments on the GPT-3 and RETRO models. They show that their black-box attack can successfully manipulate the models' opinions on topics such as politics and social issues, even when the models are trained to be robust to adversarial attacks.
The implications of this research are significant, as it highlights the potential for malicious actors to exploit the vulnerabilities of RAG-based LLMs to sway public opinion, spread misinformation, or undermine trust in important institutions. The findings of this paper are particularly relevant in light of the growing use of LLMs in high-stakes applications, such as content moderation and decision-making systems.
Critical Analysis
The researchers in this paper provide a compelling demonstration of the vulnerabilities of retrieval-augmented generation (RAG) in large language models (LLMs). Their black-box attack method is a significant contribution to the ongoing research on the security and robustness of these models.
However, it's important to note that the paper does not address the potential countermeasures or mitigation strategies that could be employed to defend against such attacks. The authors acknowledge this limitation and suggest that future work should focus on developing more robust techniques for securing RAG-based LLMs.
Additionally, the paper's experiments are limited to a few specific models and topics, and it's unclear how the attack would perform on a wider range of LLMs or in more diverse real-world scenarios. Further research is needed to understand the broader implications and applicability of the attack method.
Despite these caveats, the research presented in this paper is a valuable contribution to the field of AI security and robustness. It highlights the need for continued vigilance and innovation in developing secure and trustworthy large language models, especially as these technologies become more ubiquitous in our daily lives.
Conclusion
This paper explores a novel black-box attack method that can manipulate the opinions of retrieval-augmented generation (RAG) large language models (LLMs) on sensitive topics. The researchers demonstrate the effectiveness of their attack through experiments on prominent LLMs, showing how malicious actors could exploit the vulnerabilities of RAG-based models to sway public opinion, spread misinformation, or undermine trust in important institutions.
The findings of this paper underscore the pressing need for further research into the security and robustness of large language models, particularly as they become more widely adopted in high-stakes applications. By addressing these challenges, the AI community can work towards developing more secure and trustworthy language models that can be relied upon to provide accurate and unbiased information to the public.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Black-Box Opinion Manipulation Attacks to Retrieval-Augmented Generation of Large Language Models
Zhuo Chen, Jiawei Liu, Haotan Liu, Qikai Cheng, Fan Zhang, Wei Lu, Xiaozhong Liu
Retrieval-Augmented Generation (RAG) is applied to solve hallucination problems and real-time constraints of large language models, but it also induces vulnerabilities against retrieval corruption attacks. Existing research mainly explores the unreliability of RAG in white-box and closed-domain QA tasks. In this paper, we aim to reveal the vulnerabilities of Retrieval-Enhanced Generative (RAG) models when faced with black-box attacks for opinion manipulation. We explore the impact of such attacks on user cognition and decision-making, providing new insight to enhance the reliability and security of RAG models. We manipulate the ranking results of the retrieval model in RAG with instruction and use these results as data to train a surrogate model. By employing adversarial retrieval attack methods to the surrogate model, black-box transfer attacks on RAG are further realized. Experiments conducted on opinion datasets across multiple topics show that the proposed attack strategy can significantly alter the opinion polarity of the content generated by RAG. This demonstrates the model's vulnerability and, more importantly, reveals the potential negative impact on user cognition and decision-making, making it easier to mislead users into accepting incorrect or biased information.
Read more7/19/2024

0
BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models
Jiaqi Xue, Mengxin Zheng, Yebowen Hu, Fei Liu, Xun Chen, Qian Lou
Large Language Models (LLMs) are constrained by outdated information and a tendency to generate incorrect data, commonly referred to as hallucinations. Retrieval-Augmented Generation (RAG) addresses these limitations by combining the strengths of retrieval-based methods and generative models. This approach involves retrieving relevant information from a large, up-to-date dataset and using it to enhance the generation process, leading to more accurate and contextually appropriate responses. Despite its benefits, RAG introduces a new attack surface for LLMs, particularly because RAG databases are often sourced from public data, such as the web. In this paper, we propose TrojRAG{} to identify the vulnerabilities and attacks on retrieval parts (RAG database) and their indirect attacks on generative parts (LLMs). Specifically, we identify that poisoning several customized content passages could achieve a retrieval backdoor, where the retrieval works well for clean queries but always returns customized poisoned adversarial queries. Triggers and poisoned passages can be highly customized to implement various attacks. For example, a trigger could be a semantic group like The Republican Party, Donald Trump, etc. Adversarial passages can be tailored to different contents, not only linked to the triggers but also used to indirectly attack generative LLMs without modifying them. These attacks can include denial-of-service attacks on RAG and semantic steering attacks on LLM generations conditioned by the triggers. Our experiments demonstrate that by just poisoning 10 adversarial passages can induce 98.2% success rate to retrieve the adversarial passages. Then, these passages can increase the reject ratio of RAG-based GPT-4 from 0.01% to 74.6% or increase the rate of negative responses from 0.22% to 72% for targeted queries.
Read more6/7/2024

0
PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models
Wei Zou, Runpeng Geng, Binghui Wang, Jinyuan Jia
Large language models (LLMs) have achieved remarkable success due to their exceptional generative capabilities. Despite their success, they also have inherent limitations such as a lack of up-to-date knowledge and hallucination. Retrieval-Augmented Generation (RAG) is a state-of-the-art technique to mitigate these limitations. The key idea of RAG is to ground the answer generation of an LLM on external knowledge retrieved from a knowledge database. Existing studies mainly focus on improving the accuracy or efficiency of RAG, leaving its security largely unexplored. We aim to bridge the gap in this work. We find that the knowledge database in a RAG system introduces a new and practical attack surface. Based on this attack surface, we propose PoisonedRAG, the first knowledge corruption attack to RAG, where an attacker could inject a few malicious texts into the knowledge database of a RAG system to induce an LLM to generate an attacker-chosen target answer for an attacker-chosen target question. We formulate knowledge corruption attacks as an optimization problem, whose solution is a set of malicious texts. Depending on the background knowledge (e.g., black-box and white-box settings) of an attacker on a RAG system, we propose two solutions to solve the optimization problem, respectively. Our results show PoisonedRAG could achieve a 90% attack success rate when injecting five malicious texts for each target question into a knowledge database with millions of texts. We also evaluate several defenses and our results show they are insufficient to defend against PoisonedRAG, highlighting the need for new defenses.
Read more8/14/2024
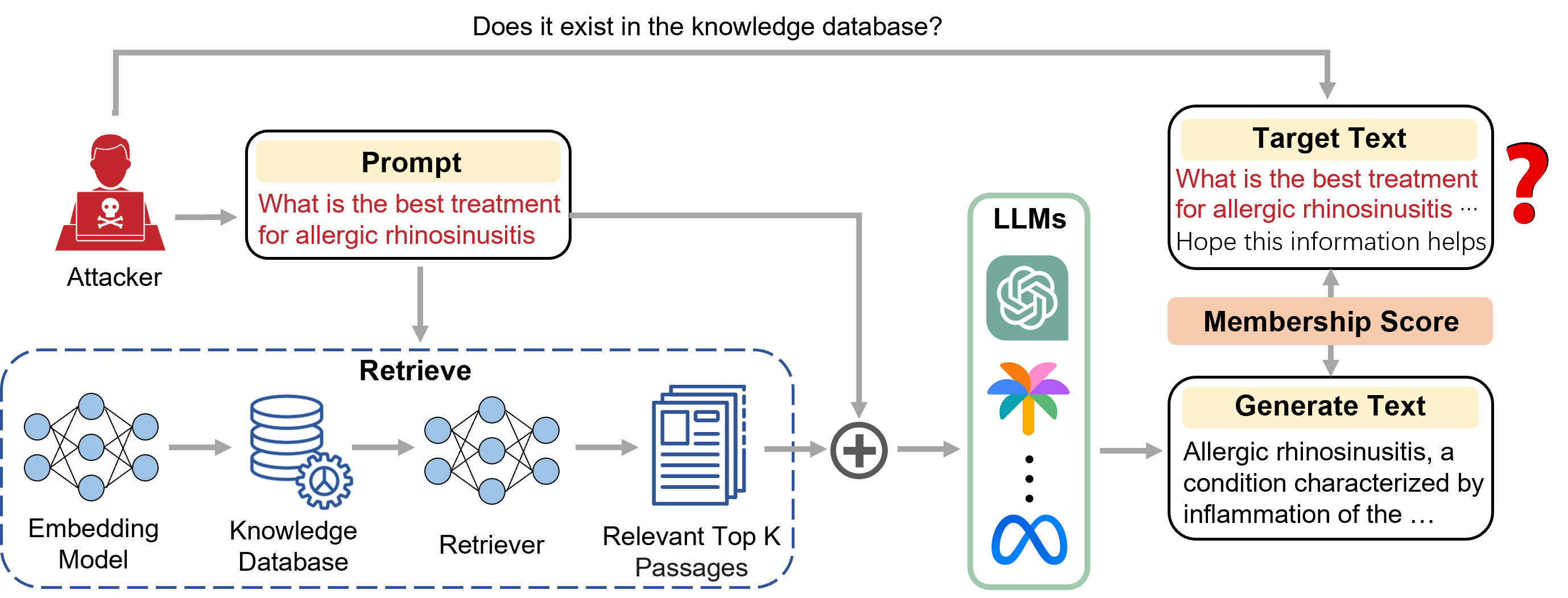
0
Seeing Is Believing: Black-Box Membership Inference Attacks Against Retrieval Augmented Generation
Yuying Li, Gaoyang Liu, Yang Yang, Chen Wang
Retrieval-Augmented Generation (RAG) is a state-of-the-art technique that enhances Large Language Models (LLMs) by retrieving relevant knowledge from an external, non-parametric database. This approach aims to mitigate common LLM issues such as hallucinations and outdated knowledge. Although existing research has demonstrated security and privacy vulnerabilities within RAG systems, making them susceptible to attacks like jailbreaks and prompt injections, the security of the RAG system's external databases remains largely underexplored. In this paper, we employ Membership Inference Attacks (MIA) to determine whether a sample is part of the knowledge database of a RAG system, using only black-box API access. Our core hypothesis posits that if a sample is a member, it will exhibit significant similarity to the text generated by the RAG system. To test this, we compute the cosine similarity and the model's perplexity to establish a membership score, thereby building robust features. We then introduce two novel attack strategies: a Threshold-based Attack and a Machine Learning-based Attack, designed to accurately identify membership. Experimental validation of our methods has achieved a ROC AUC of 82%.
Read more6/28/2024