Generation Constraint Scaling Can Mitigate Hallucination

0

Sign in to get full access
Overview
- Generation Constraint Scaling Can Mitigate Hallucination is a research paper that explores techniques to address the issue of hallucination in large language models.
- Hallucination refers to the generation of content that is factually incorrect or ungrounded in the input data.
- The paper introduces two approaches, Larimar and GRACE, that aim to mitigate hallucination through constraint-based generation.
Plain English Explanation
Large language models are powerful tools that can generate human-like text, but they can sometimes produce content that is not factually accurate, known as hallucination. This paper proposes two methods to help address this problem.
The first approach, called Larimar, works by adding constraints to the language model during the generation process. These constraints help guide the model to produce text that is more closely aligned with the input data, reducing the likelihood of hallucination.
The second approach, called GRACE, takes a different angle. It trains the model to be more aware of what it does and does not know, allowing it to recognize when it is unsure about something and avoid generating potentially inaccurate content.
By incorporating these constraint-based techniques, the researchers found that the language models were better able to avoid hallucination while still maintaining their ability to generate coherent and natural-sounding text.
Technical Explanation
The paper introduces two approaches to mitigate hallucination in large language models:
Larimar is a constraint-based generation technique that applies a series of filters to the model's output during the generation process. These filters ensure that the generated text aligns with the input data and relevant knowledge, reducing the likelihood of hallucination.
GRACE (Grounded Representation and Awareness for Coherent Estimation) is a training approach that encourages the model to be more aware of its own knowledge and uncertainty. By learning to recognize when it is unsure about something, the model can avoid generating potentially inaccurate content.
The researchers conducted extensive experiments to evaluate the effectiveness of these approaches, comparing them to baseline language models and other hallucination mitigation techniques. Their results demonstrate that Larimar and GRACE can significantly reduce hallucination while maintaining the models' overall performance in tasks like question answering and text generation.
Critical Analysis
The paper provides a comprehensive and well-designed study on mitigating hallucination in large language models. The researchers have thoughtfully addressed a crucial challenge in the field of natural language processing.
One potential limitation of the study is the specific datasets and models used in the experiments. While the researchers have tried to cover a range of scenarios, the effectiveness of Larimar and GRACE may vary depending on the domain, language, and architecture of the language model being used.
Additionally, the paper does not explore the computational and resource costs associated with implementing these hallucination mitigation techniques. Integrating these approaches into real-world applications may require careful consideration of the trade-offs between accuracy and efficiency.
Further research could investigate the generalizability of these techniques to other language tasks, such as open-ended dialogue or multi-modal applications. Exploring the long-term impacts of these approaches on the reliability and trustworthiness of language models would also be a valuable area of study.
Conclusion
This research paper presents two innovative approaches, Larimar and GRACE, to address the problem of hallucination in large language models. By incorporating constraint-based generation and improved awareness of model uncertainty, these techniques demonstrate the potential to enhance the reliability and trustworthiness of language AI systems.
As the field of natural language processing continues to evolve, addressing challenges like hallucination will be crucial for developing language models that can be safely and effectively deployed in real-world applications. The insights and methods presented in this paper contribute to this important goal and pave the way for further advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generation Constraint Scaling Can Mitigate Hallucination
Georgios Kollias, Payel Das, Subhajit Chaudhury
Addressing the issue of hallucinations in large language models (LLMs) is a critical challenge. As the cognitive mechanisms of hallucination have been related to memory, here we explore hallucination for LLM that is enabled with explicit memory mechanisms. We empirically demonstrate that by simply scaling the readout vector that constrains generation in a memory-augmented LLM decoder, hallucination mitigation can be achieved in a training-free manner. Our method is geometry-inspired and outperforms a state-of-the-art LLM editing method on the task of generation of Wikipedia-like biography entries both in terms of generation quality and runtime complexity.
Read more7/25/2024
0
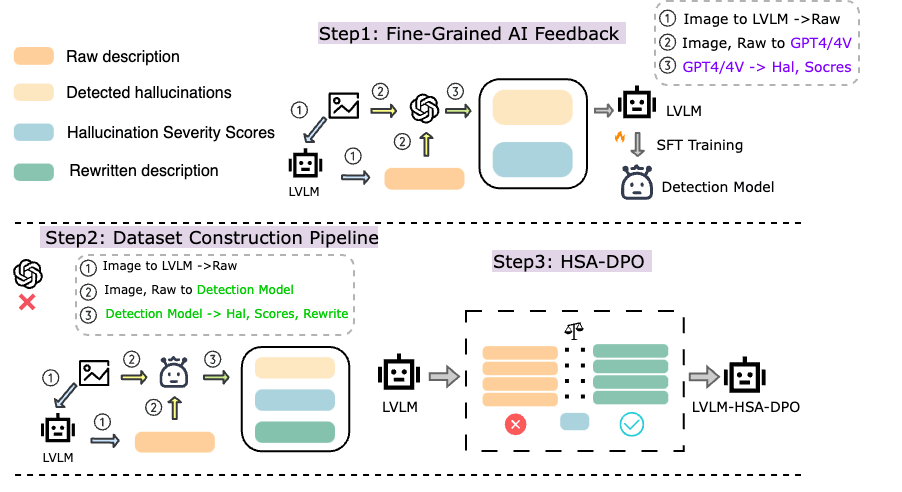
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024

0
Mitigating Multilingual Hallucination in Large Vision-Language Models
Xiaoye Qu, Mingyang Song, Wei Wei, Jianfeng Dong, Yu Cheng
While Large Vision-Language Models (LVLMs) have exhibited remarkable capabilities across a wide range of tasks, they suffer from hallucination problems, where models generate plausible yet incorrect answers given the input image-query pair. This hallucination phenomenon is even more severe when querying the image in non-English languages, while existing methods for mitigating hallucinations in LVLMs only consider the English scenarios. In this paper, we make the first attempt to mitigate this important multilingual hallucination in LVLMs. With thorough experiment analysis, we found that multilingual hallucination in LVLMs is a systemic problem that could arise from deficiencies in multilingual capabilities or inadequate multimodal abilities. To this end, we propose a two-stage Multilingual Hallucination Removal (MHR) framework for LVLMs, aiming to improve resistance to hallucination for both high-resource and low-resource languages. Instead of relying on the intricate manual annotations of multilingual resources, we fully leverage the inherent capabilities of the LVLM and propose a novel cross-lingual alignment method, which generates multiple responses for each image-query input and then identifies the hallucination-aware pairs for each language. These data pairs are finally used for direct preference optimization to prompt the LVLMs to favor non-hallucinating responses. Experimental results show that our MHR achieves a substantial reduction in hallucination generation for LVLMs. Notably, on our extended multilingual POPE benchmark, our framework delivers an average increase of 19.0% in accuracy across 13 different languages. Our code and model weights are available at https://github.com/ssmisya/MHR
Read more8/2/2024

0
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Jiri Hron, Laura Culp, Gamaleldin Elsayed, Rosanne Liu, Ben Adlam, Maxwell Bileschi, Bernd Bohnet, JD Co-Reyes, Noah Fiedel, C. Daniel Freeman, Izzeddin Gur, Kathleen Kenealy, Jaehoon Lee, Peter J. Liu, Gaurav Mishra, Igor Mordatch, Azade Nova, Roman Novak, Aaron Parisi, Jeffrey Pennington, Alex Rizkowsky, Isabelle Simpson, Hanie Sedghi, Jascha Sohl-dickstein, Kevin Swersky, Sharad Vikram, Tris Warkentin, Lechao Xiao, Kelvin Xu, Jasper Snoek, Simon Kornblith
While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Read more8/16/2024