Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability

0

Sign in to get full access
Overview
- Explores training language models (LMs) on knowledge graphs to control what they know and reduce hallucinations
- Provides insights on the detectability of hallucinations in LMs trained this way
- Investigates how the structure of knowledge graphs can help detect hallucinations
Plain English Explanation
When training large language models (LMs), there is a risk that the model will "hallucinate" or generate information that is not factually correct. This paper explores how training LMs on knowledge graphs can help control what the model knows and reduce hallucinations.
The key idea is that by grounding the LM's knowledge in a structured knowledge graph, the model will be less likely to generate information that is not supported by the facts in the graph. The researchers also investigate how the structure of the knowledge graph can be leveraged to detect hallucinations when they do occur.
This is an important area of research, as hallucinations in large language models can lead to the spread of misinformation and undermine the reliability of these models. By better controlling what LMs know and detecting hallucinations, this work aims to enhance summarization and other applications that rely on accurate language generation.
Technical Explanation
The paper begins by discussing the challenge of controlling what language models (LMs) know, and the risk of hallucinations - the generation of factually incorrect information. To address this, the researchers propose training LMs on knowledge graphs, which provide a structured representation of factual knowledge.
They explore different strategies for incorporating knowledge graphs into the LM training process, including directly embedding the graph structure and introducing specialized loss functions to encourage the model to respect the graph's constraints. Experiments on standard benchmarks show that this approach can indeed reduce hallucinations compared to standard LM training.
The paper also investigates the detectability of hallucinations in these knowledge-graph-trained LMs. The researchers leverage the structured nature of the knowledge graph to develop techniques for identifying when the model's outputs deviate from the facts encoded in the graph. This includes analyzing the model's confidence in its outputs and comparing them to the certainty of the corresponding knowledge graph facts.
The insights from this work have important implications for enhancing the reliability and trustworthiness of large language models, particularly in applications where factual accuracy is critical, such as summarization and question-answering.
Critical Analysis
The paper presents a thoughtful approach to addressing the challenge of hallucinations in language models, but there are a few potential limitations and areas for further research:
-
The experiments focus on relatively small knowledge graphs, and it's unclear how well the techniques would scale to the larger, more complex knowledge graphs needed for real-world applications.
-
The proposed methods for detecting hallucinations rely on the availability of a comprehensive, high-quality knowledge graph. In practice, knowledge graphs may be incomplete or contain errors, which could impact the effectiveness of the hallucination detection.
-
The paper does not address the trade-offs between the level of control exerted over the LM's knowledge and its flexibility or creativity. Overly constraining the model to the knowledge graph could potentially limit its ability to generate novel, useful information.
Further research could explore ways to balance the benefits of knowledge-graph-based training with maintaining the versatility and generative capabilities of language models. Additionally, investigating the transferability of these techniques to different domains and applications would be valuable.
Conclusion
This paper presents an innovative approach to training language models on knowledge graphs, with the goal of better controlling what the models know and reducing hallucinations. The insights around leveraging the structure of knowledge graphs to detect hallucinations are particularly promising, as they could enhance the reliability and trustworthiness of these powerful language models.
While the research has some limitations, it represents an important step forward in addressing a critical challenge in the development of large language models. As these models become increasingly ubiquitous in various applications, ensuring their factual accuracy and reliability will be crucial for maintaining user trust and preventing the spread of misinformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Jiri Hron, Laura Culp, Gamaleldin Elsayed, Rosanne Liu, Ben Adlam, Maxwell Bileschi, Bernd Bohnet, JD Co-Reyes, Noah Fiedel, C. Daniel Freeman, Izzeddin Gur, Kathleen Kenealy, Jaehoon Lee, Peter J. Liu, Gaurav Mishra, Igor Mordatch, Azade Nova, Roman Novak, Aaron Parisi, Jeffrey Pennington, Alex Rizkowsky, Isabelle Simpson, Hanie Sedghi, Jascha Sohl-dickstein, Kevin Swersky, Sharad Vikram, Tris Warkentin, Lechao Xiao, Kelvin Xu, Jasper Snoek, Simon Kornblith
While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Read more8/16/2024
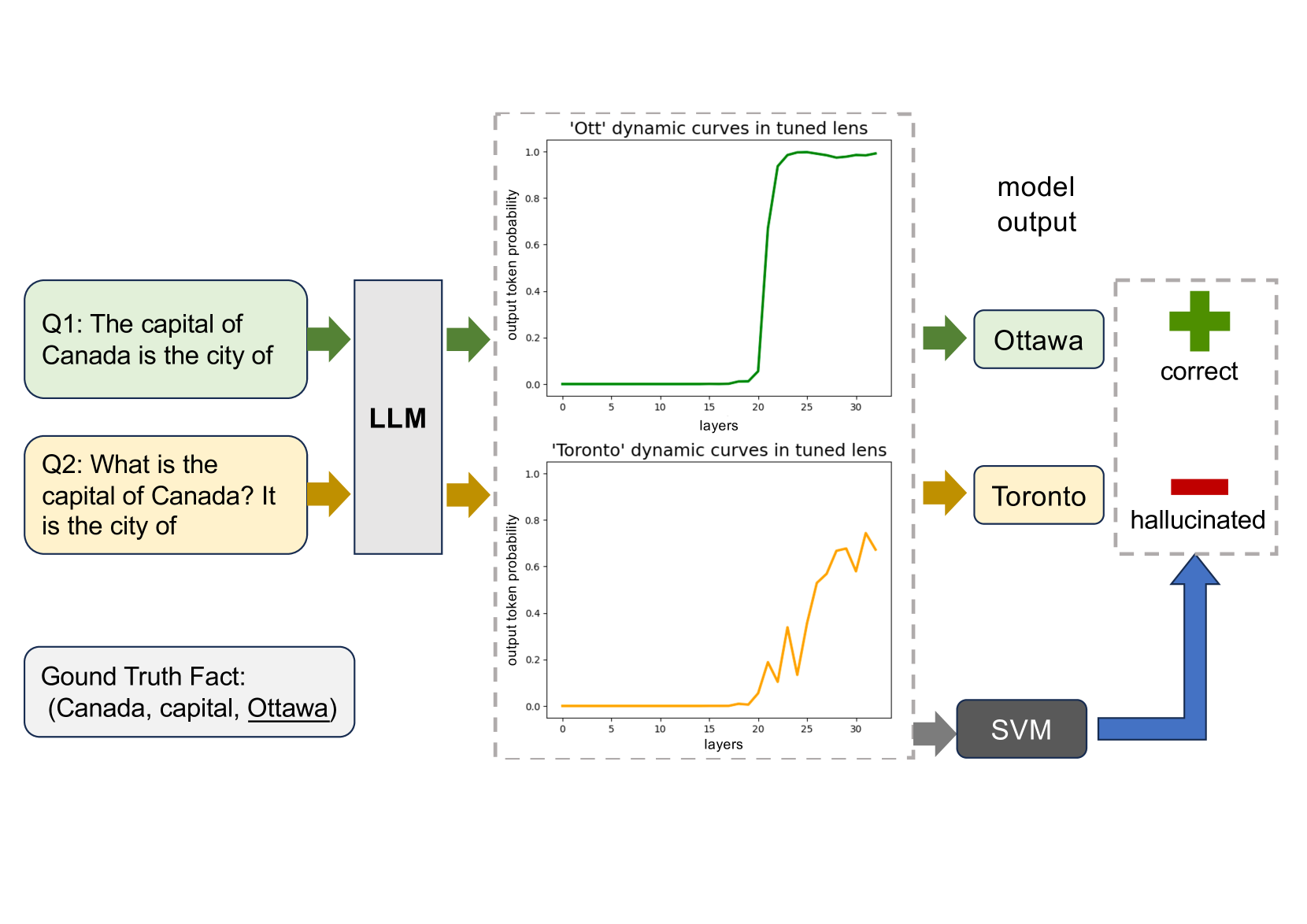
0
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Read more4/1/2024

0
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Read more5/7/2024

0
Leveraging Graph Structures to Detect Hallucinations in Large Language Models
Noa Nonkes, Sergei Agaronian, Evangelos Kanoulas, Roxana Petcu
Large language models are extensively applied across a wide range of tasks, such as customer support, content creation, educational tutoring, and providing financial guidance. However, a well-known drawback is their predisposition to generate hallucinations. This damages the trustworthiness of the information these models provide, impacting decision-making and user confidence. We propose a method to detect hallucinations by looking at the structure of the latent space and finding associations within hallucinated and non-hallucinated generations. We create a graph structure that connects generations that lie closely in the embedding space. Moreover, we employ a Graph Attention Network which utilizes message passing to aggregate information from neighboring nodes and assigns varying degrees of importance to each neighbor based on their relevance. Our findings show that 1) there exists a structure in the latent space that differentiates between hallucinated and non-hallucinated generations, 2) Graph Attention Networks can learn this structure and generalize it to unseen generations, and 3) the robustness of our method is enhanced when incorporating contrastive learning. When evaluated against evidence-based benchmarks, our model performs similarly without access to search-based methods.
Read more7/8/2024