Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning

0

Sign in to get full access
Overview
- This paper introduces a novel method called "Render and Diffuse" for aligning image and action spaces to enable diffusion-based behavior cloning.
- The approach combines differentiable rendering and diffusion models to learn a mapping between visual observations and actions.
- The system is designed to work in a variety of environments, including simulated and real-world settings.
Plain English Explanation
The paper presents a new technique called "Render and Diffuse" that helps computers learn how to perform tasks by watching demonstrations. Typically, it's challenging for computers to understand the connection between what they see in images and the actions they need to take. This method tries to bridge that gap by using a combination of two powerful machine learning tools: differentiable rendering and diffusion models.
Differentiable rendering allows the system to generate realistic images from 3D scene representations, similar to how a movie or video game engine works. The diffusion model then learns to map these synthetic images to the corresponding actions that were taken during the demonstrations. By aligning the image and action spaces in this way, the system can more effectively learn how to perform the desired behaviors.
The key advantage of this approach is that it should work across a wide range of environments, from simulated settings to the real world. This flexibility is important because it means the method can potentially be applied to a variety of robotic and AI applications, not just a specific task or domain.
Technical Explanation
The core of the "Render and Diffuse" method is the use of differentiable rendering and diffusion models to bridge the gap between visual observations and actions.
The differentiable renderer takes a 3D representation of the environment, including object poses and other relevant scene information, and generates a corresponding image. This allows the system to create synthetic observations that match the demonstrations the model is trained on.
The diffusion model then learns to map these rendered images to the action sequences performed in the demonstrations. Diffusion models are well-suited for this task because they can capture the complex, multi-modal relationship between visual inputs and actions.
By aligning the image and action spaces in this way, the "Render and Diffuse" approach aims to enable more robust and generalizable behavior cloning compared to previous methods. The authors demonstrate the effectiveness of their technique in both simulated and real-world environments, showing its potential for a wide range of applications, from robotic manipulation to perspective-taking.
Critical Analysis
The "Render and Diffuse" method presents a promising approach to aligning image and action spaces for behavior cloning, but it does have some potential limitations that are worth considering.
One key concern is the reliance on accurate 3D scene representations, which may not always be available, especially in real-world environments. The authors acknowledge this challenge and suggest that the method could potentially be extended to work with less structured visual inputs, but further research would be needed to validate this.
Additionally, the use of diffusion models, while powerful, can be computationally expensive and may require significant training data to achieve good performance. The authors do not provide a detailed analysis of the sample efficiency or training time requirements of their approach, which could be important considerations for practical applications.
It's also worth noting that the paper focuses on demonstrating the feasibility of the "Render and Diffuse" approach, but does not explore its potential limitations or failure modes in depth. Further research and testing would be needed to fully understand the strengths and weaknesses of this method, especially when deployed in complex, real-world scenarios.
Conclusion
The "Render and Diffuse" method introduced in this paper represents an innovative approach to bridging the gap between visual observations and actions for behavior cloning. By combining differentiable rendering and diffusion models, the system can learn to map images to the corresponding actions, potentially enabling more robust and generalizable learning across a variety of environments.
While the paper demonstrates promising results, there are still some open challenges and areas for further research. Nonetheless, this work is an important step forward in the field of AI and robotics, and its core ideas could have far-reaching implications for tasks like manipulation, navigation, and even perspective-taking. As the field continues to evolve, techniques like "Render and Diffuse" may play a crucial role in enabling more capable and adaptable autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning
Vitalis Vosylius, Younggyo Seo, Jafar Uruc{c}, Stephen James
In the field of Robot Learning, the complex mapping between high-dimensional observations such as RGB images and low-level robotic actions, two inherently very different spaces, constitutes a complex learning problem, especially with limited amounts of data. In this work, we introduce Render and Diffuse (R&D) a method that unifies low-level robot actions and RGB observations within the image space using virtual renders of the 3D model of the robot. Using this joint observation-action representation it computes low-level robot actions using a learnt diffusion process that iteratively updates the virtual renders of the robot. This space unification simplifies the learning problem and introduces inductive biases that are crucial for sample efficiency and spatial generalisation. We thoroughly evaluate several variants of R&D in simulation and showcase their applicability on six everyday tasks in the real world. Our results show that R&D exhibits strong spatial generalisation capabilities and is more sample efficient than more common image-to-action methods.
Read more5/29/2024
0
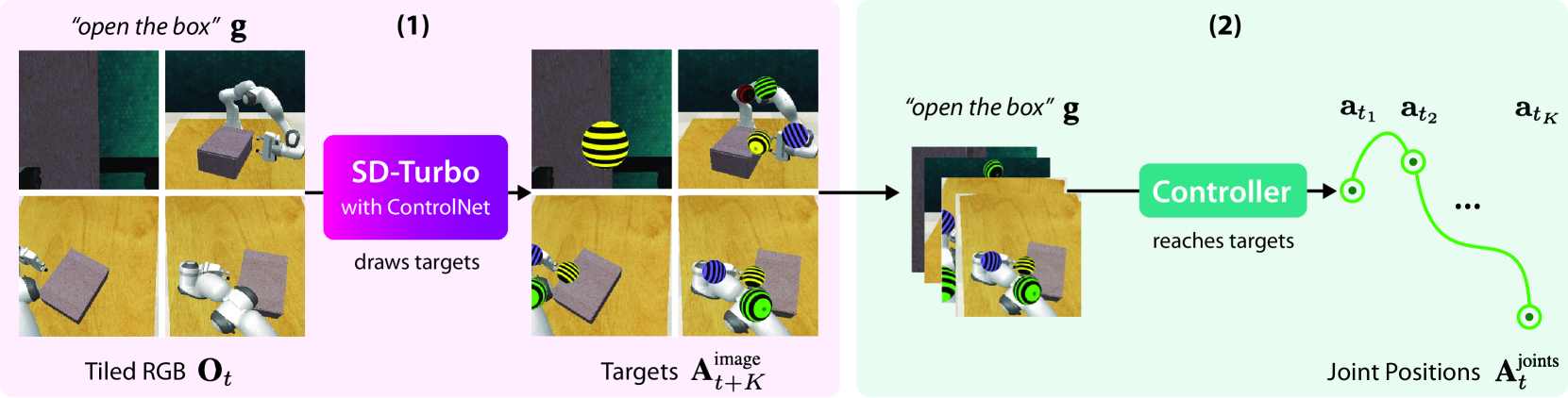
Generative Image as Action Models
Mohit Shridhar, Yat Long Lo, Stephen James
Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
Read more7/11/2024
👨🏫
0
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke, Nikolaos Gkanatsios, Katerina Fragkiadaki
Diffusion policies are conditional diffusion models that learn robot action distributions conditioned on the robot and environment state. They have recently shown to outperform both deterministic and alternative action distribution learning formulations. 3D robot policies use 3D scene feature representations aggregated from a single or multiple camera views using sensed depth. They have shown to generalize better than their 2D counterparts across camera viewpoints. We unify these two lines of work and present 3D Diffuser Actor, a neural policy equipped with a novel 3D denoising transformer that fuses information from the 3D visual scene, a language instruction and proprioception to predict the noise in noised 3D robot pose trajectories. 3D Diffuser Actor sets a new state-of-the-art on RLBench with an absolute performance gain of 18.1% over the current SOTA on a multi-view setup and an absolute gain of 13.1% on a single-view setup. On the CALVIN benchmark, it improves over the current SOTA by a 9% relative increase. It also learns to control a robot manipulator in the real world from a handful of demonstrations. Through thorough comparisons with the current SOTA policies and ablations of our model, we show 3D Diffuser Actor's design choices dramatically outperform 2D representations, regression and classification objectives, absolute attentions, and holistic non-tokenized 3D scene embeddings.
Read more7/26/2024

0
DORSal: Diffusion for Object-centric Representations of Scenes et al
Allan Jabri, Sjoerd van Steenkiste, Emiel Hoogeboom, Mehdi S. M. Sajjadi, Thomas Kipf
Recent progress in 3D scene understanding enables scalable learning of representations across large datasets of diverse scenes. As a consequence, generalization to unseen scenes and objects, rendering novel views from just a single or a handful of input images, and controllable scene generation that supports editing, is now possible. However, training jointly on a large number of scenes typically compromises rendering quality when compared to single-scene optimized models such as NeRFs. In this paper, we leverage recent progress in diffusion models to equip 3D scene representation learning models with the ability to render high-fidelity novel views, while retaining benefits such as object-level scene editing to a large degree. In particular, we propose DORSal, which adapts a video diffusion architecture for 3D scene generation conditioned on frozen object-centric slot-based representations of scenes. On both complex synthetic multi-object scenes and on the real-world large-scale Street View dataset, we show that DORSal enables scalable neural rendering of 3D scenes with object-level editing and improves upon existing approaches.
Read more5/6/2024