GenFormer -- Generated Images are All You Need to Improve Robustness of Transformers on Small Datasets

0

Sign in to get full access
Overview
- GenFormer is a novel approach that leverages generated images to improve the robustness of Transformer models on small datasets.
- The key idea is to use a generative model to create synthetic images that complement the limited real-world data, enhancing the model's ability to learn robust features.
- This technique can be particularly beneficial for applications with scarce labeled data, where traditional fine-tuning approaches may struggle.
Plain English Explanation
The paper presents a technique called GenFormer that aims to make Transformer models more robust when working with small datasets. The core concept is to use a generative model, such as a Generative Adversarial Network (GAN), to create synthetic images that can supplement the limited real-world data available. By combining the real and generated images, the Transformer model can learn more robust features, improving its performance on tasks like image classification, even with a small dataset.
This approach can be particularly useful in scenarios where labeled data is scarce, such as in medical imaging or specialized domains. Traditional fine-tuning techniques may not work well in these cases, as the model can overfit to the limited real-world data. By incorporating the generated images, the GenFormer approach aims to address this issue and make Transformer models more versatile and reliable, even when working with small datasets.
Technical Explanation
The key components of the GenFormer approach are:
- A generative model, such as a Vision Transformer-based GAN, which is trained to generate synthetic images that resemble the real-world data.
- A Transformer-based classification model, which is the main target of the robustness improvement.
- A training process that combines the real and generated images to fine-tune the Transformer model, leveraging the complementary information provided by the synthetic data.
The authors demonstrate the effectiveness of the GenFormer approach through extensive experiments on various small-scale datasets, showing significant improvements in the Transformer model's classification accuracy and robustness compared to traditional fine-tuning methods.
Critical Analysis
The GenFormer approach presents a promising direction for improving the robustness of Transformer models on small datasets. However, a few potential limitations and areas for further research are worth considering:
- The performance of the GenFormer approach may be dependent on the quality and fidelity of the generated synthetic images. If the generative model produces images that do not capture the essential features of the real-world data, the benefits of the GenFormer approach may be limited.
- The study focuses on relatively simple image classification tasks, and it would be valuable to explore the GenFormer approach in more complex computer vision applications, such as object detection or segmentation, to assess its broader applicability.
- The authors do not provide a detailed analysis of the types of visual features that the GenFormer approach helps the Transformer model to learn. Understanding these learned features could provide valuable insights for further improving the approach.
Conclusion
The GenFormer technique presented in this paper offers a promising solution for enhancing the robustness of Transformer models on small datasets. By leveraging generated images to complement the limited real-world data, the GenFormer approach helps Transformer models learn more robust visual features, leading to improved classification performance. This technique can be particularly valuable in domains with scarce labeled data, where traditional fine-tuning methods may struggle. While the paper provides a solid foundation, further research is needed to explore the broader applicability of the GenFormer approach and address potential limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GenFormer -- Generated Images are All You Need to Improve Robustness of Transformers on Small Datasets
Sven Oehri, Nikolas Ebert, Ahmed Abdullah, Didier Stricker, Oliver Wasenmuller
Recent studies showcase the competitive accuracy of Vision Transformers (ViTs) in relation to Convolutional Neural Networks (CNNs), along with their remarkable robustness. However, ViTs demand a large amount of data to achieve adequate performance, which makes their application to small datasets challenging, falling behind CNNs. To overcome this, we propose GenFormer, a data augmentation strategy utilizing generated images, thereby improving transformer accuracy and robustness on small-scale image classification tasks. In our comprehensive evaluation we propose Tiny ImageNetV2, -R, and -A as new test set variants of Tiny ImageNet by transferring established ImageNet generalization and robustness benchmarks to the small-scale data domain. Similarly, we introduce MedMNIST-C and EuroSAT-C as corrupted test set variants of established fine-grained datasets in the medical and aerial domain. Through a series of experiments conducted on small datasets of various domains, including Tiny ImageNet, CIFAR, EuroSAT and MedMNIST datasets, we demonstrate the synergistic power of our method, in particular when combined with common train and test time augmentations, knowledge distillation, and architectural design choices. Additionally, we prove the effectiveness of our approach under challenging conditions with limited training data, demonstrating significant improvements in both accuracy and robustness, bridging the gap between CNNs and ViTs in the small-scale dataset domain.
Read more8/28/2024
🏋️
0
ViTGAN: Training GANs with Vision Transformers
Kwonjoon Lee, Huiwen Chang, Lu Jiang, Han Zhang, Zhuowen Tu, Ce Liu
Recently, Vision Transformers (ViTs) have shown competitive performance on image recognition while requiring less vision-specific inductive biases. In this paper, we investigate if such performance can be extended to image generation. To this end, we integrate the ViT architecture into generative adversarial networks (GANs). For ViT discriminators, we observe that existing regularization methods for GANs interact poorly with self-attention, causing serious instability during training. To resolve this issue, we introduce several novel regularization techniques for training GANs with ViTs. For ViT generators, we examine architectural choices for latent and pixel mapping layers to facilitate convergence. Empirically, our approach, named ViTGAN, achieves comparable performance to the leading CNN-based GAN models on three datasets: CIFAR-10, CelebA, and LSUN bedroom.
Read more5/30/2024

0
Self-supervised Vision Transformer are Scalable Generative Models for Domain Generalization
Sebastian Doerrich, Francesco Di Salvo, Christian Ledig
Despite notable advancements, the integration of deep learning (DL) techniques into impactful clinical applications, particularly in the realm of digital histopathology, has been hindered by challenges associated with achieving robust generalization across diverse imaging domains and characteristics. Traditional mitigation strategies in this field such as data augmentation and stain color normalization have proven insufficient in addressing this limitation, necessitating the exploration of alternative methodologies. To this end, we propose a novel generative method for domain generalization in histopathology images. Our method employs a generative, self-supervised Vision Transformer to dynamically extract characteristics of image patches and seamlessly infuse them into the original images, thereby creating novel, synthetic images with diverse attributes. By enriching the dataset with such synthesized images, we aim to enhance its holistic nature, facilitating improved generalization of DL models to unseen domains. Extensive experiments conducted on two distinct histopathology datasets demonstrate the effectiveness of our proposed approach, outperforming the state of the art substantially, on the Camelyon17-wilds challenge dataset (+2%) and on a second epithelium-stroma dataset (+26%). Furthermore, we emphasize our method's ability to readily scale with increasingly available unlabeled data samples and more complex, higher parametric architectures. Source code is available at https://github.com/sdoerrich97/vits-are-generative-models .
Read more7/4/2024
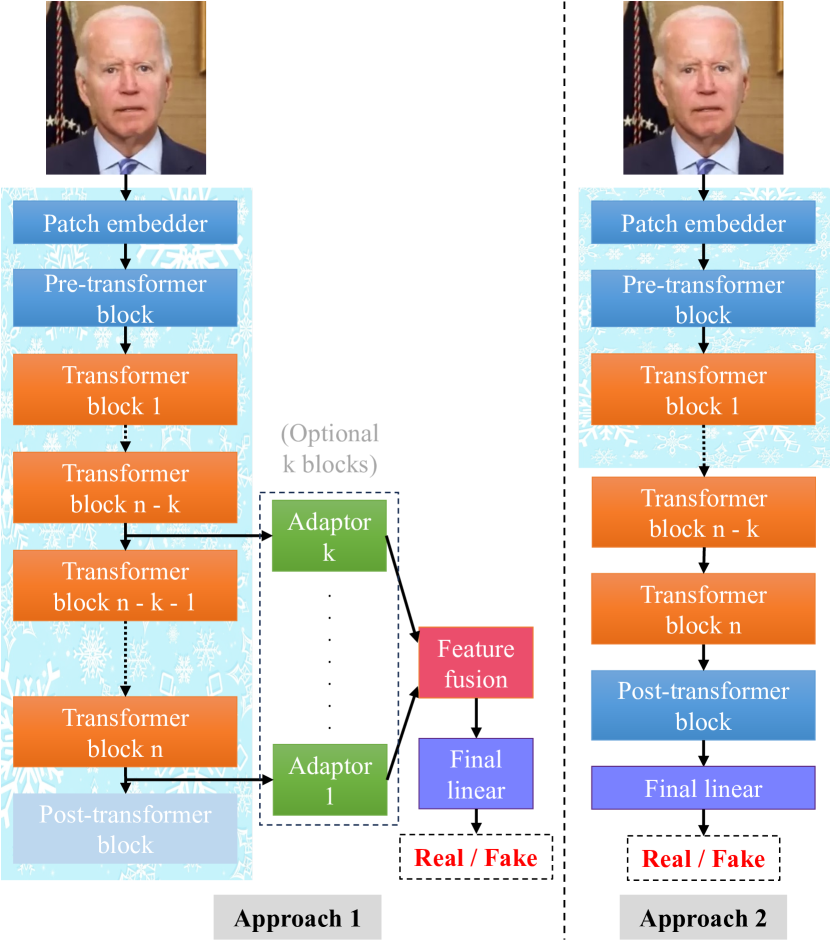
0
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
This paper investigates the effectiveness of self-supervised pre-trained vision transformers (ViTs) compared to supervised pre-trained ViTs and conventional neural networks (ConvNets) for detecting facial deepfake images and videos. It examines their potential for improved generalization and explainability, especially with limited training data. Despite the success of transformer architectures in various tasks, the deepfake detection community is hesitant to use large ViTs as feature extractors due to their perceived need for extensive data and suboptimal generalization with small datasets. This contrasts with ConvNets, which are already established as robust feature extractors. Additionally, training ViTs from scratch requires significant resources, limiting their use to large companies. Recent advancements in self-supervised learning (SSL) for ViTs, like masked autoencoders and DINOs, show adaptability across diverse tasks and semantic segmentation capabilities. By leveraging SSL ViTs for deepfake detection with modest data and partial fine-tuning, we find comparable adaptability to deepfake detection and explainability via the attention mechanism. Moreover, partial fine-tuning of ViTs is a resource-efficient option.
Read more8/12/2024