A Geometric Explanation of the Likelihood OOD Detection Paradox
2403.18910
0
0

Abstract
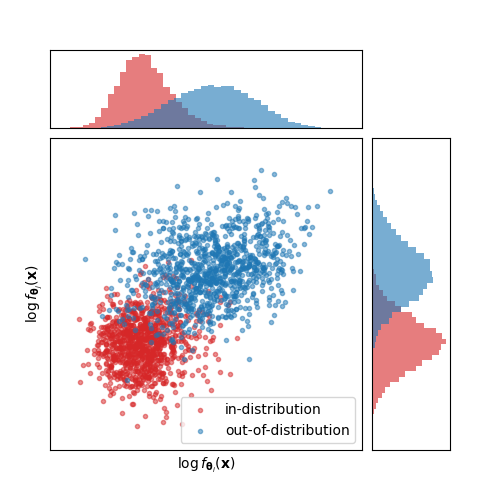
Likelihood-based deep generative models (DGMs) commonly exhibit a puzzling behaviour: when trained on a relatively complex dataset, they assign higher likelihood values to out-of-distribution (OOD) data from simpler sources. Adding to the mystery, OOD samples are never generated by these DGMs despite having higher likelihoods. This two-pronged paradox has yet to be conclusively explained, making likelihood-based OOD detection unreliable. Our primary observation is that high-likelihood regions will not be generated if they contain minimal probability mass. We demonstrate how this seeming contradiction of large densities yet low probability mass can occur around data confined to low-dimensional manifolds. We also show that this scenario can be identified through local intrinsic dimension (LID) estimation, and propose a method for OOD detection which pairs the likelihoods and LID estimates obtained from a pre-trained DGM. Our method can be applied to normalizing flows and score-based diffusion models, and obtains results which match or surpass state-of-the-art OOD detection benchmarks using the same DGM backbones. Our code is available at https://github.com/layer6ai-labs/dgm_ood_detection.
Create account to get full access
Overview
- This paper explores a geometric explanation for the "likelihood out-of-distribution (OOD) detection paradox" observed in deep generative models.
- The paradox refers to the counterintuitive finding that models with higher likelihood scores on in-distribution data can perform worse at detecting OOD samples.
- The authors propose a geometric framework to analyze this phenomenon and derive insights into the limitations of likelihood-based OOD detection.
Plain English Explanation
In machine learning, researchers often use deep generative models to learn the underlying patterns in a dataset. These models can then be used to detect samples that are "out-of-distribution" (OOD) - meaning they don't fit the patterns learned from the training data.
One common approach is to use the likelihood score, which measures how well the model can explain a given sample. The intuition is that OOD samples should have lower likelihood scores compared to in-distribution samples.
However, the authors of this paper identified a "paradox" - they found that models with higher likelihood scores on in-distribution data can actually perform worse at detecting OOD samples. This seems counterintuitive, as you might expect a model that better fits the training data to also be better at identifying anomalies.
To understand this phenomenon, the authors developed a geometric framework to analyze the relationship between likelihood and OOD detection. They showed that as a model's likelihood scores on in-distribution data improve, the decision boundary for OOD detection can become less effective. This is because the model may become overly confident in its ability to explain the training data, making it harder to distinguish OOD samples.
The authors' analysis provides important insights into the limitations of likelihood-based OOD detection. It suggests that researchers should look beyond just likelihood scores and consider more sophisticated approaches to improve out-of-distribution detection in deep generative models.
Technical Explanation
The authors present a geometric framework to analyze the "likelihood out-of-distribution (OOD) detection paradox" observed in deep generative models. This paradox refers to the counterintuitive finding that models with higher likelihood scores on in-distribution data can perform worse at detecting OOD samples.
The authors show that this phenomenon can be explained by the geometry of the model's decision boundary. As a generative model's likelihood scores on in-distribution data improve, the decision boundary for OOD detection can become less effective. This is because the model may become overly confident in its ability to explain the training data, making it harder to distinguish OOD samples.
Specifically, the authors derive a relationship between the model's Fisher Information Metric (FIM) and the OOD detection performance. They show that as the eigenvalues of the FIM decrease, the decision boundary for OOD detection becomes less sensitive, leading to the likelihood OOD detection paradox.
The authors validate their geometric framework through experiments on both synthetic and real-world datasets, demonstrating the limitations of likelihood-based OOD detection and the importance of considering more sophisticated approaches.
Critical Analysis
The authors provide a compelling geometric explanation for the likelihood OOD detection paradox, which has important implications for the design of out-of-distribution detection systems. By linking the model's Fisher Information Metric to the OOD detection performance, the authors offer a principled way to understand the limitations of likelihood-based approaches.
One potential limitation of the research is that the analysis is primarily focused on the geometric properties of the model's decision boundary, without considering other factors that may influence OOD detection, such as the expressiveness of the model, the quality of the training data, or the choice of the likelihood function.
Additionally, while the authors demonstrate the validity of their framework through experiments, it would be valuable to see how the insights from this work translate to more complex, real-world deep generative models and OOD detection tasks. Extending the analysis to these settings could uncover additional challenges and inform the development of more robust OOD detection strategies.
Overall, this paper makes a significant contribution to the understanding of out-of-distribution detection in deep generative models, and the geometric perspective it introduces opens up new avenues for future research in this important area of machine learning.
Conclusion
This paper presents a geometric explanation for the "likelihood out-of-distribution (OOD) detection paradox" observed in deep generative models. The authors show that as a model's likelihood scores on in-distribution data improve, the decision boundary for OOD detection can become less effective, leading to counterintuitive performance.
By analyzing the relationship between the model's Fisher Information Metric and the OOD detection performance, the authors provide a principled framework for understanding the limitations of likelihood-based OOD detection. This work offers valuable insights for the design of more robust out-of-distribution detection systems and highlights the importance of considering alternative approaches beyond just likelihood scores.
The insights from this research could have significant implications for a wide range of applications that rely on deep generative models, from anomaly detection to domain adaptation and beyond. As the field of machine learning continues to advance, studies like this one will be crucial for developing a deeper understanding of the capabilities and limitations of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024

Gradient-Regularized Out-of-Distribution Detection
Sina Sharifi, Taha Entesari, Bardia Safaei, Vishal M. Patel, Mahyar Fazlyab
0
0
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. We will publicly release our code after the review process.
4/24/2024
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Sam Dauncey, Chris Holmes, Christopher Williams, Fabian Falck
0
0
Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.
5/28/2024

Your Finetuned Large Language Model is Already a Powerful Out-of-distribution Detector
Andi Zhang, Tim Z. Xiao, Weiyang Liu, Robert Bamler, Damon Wischik
0
0
We revisit the likelihood ratio between a pretrained large language model (LLM) and its finetuned variant as a criterion for out-of-distribution (OOD) detection. The intuition behind such a criterion is that, the pretrained LLM has the prior knowledge about OOD data due to its large amount of training data, and once finetuned with the in-distribution data, the LLM has sufficient knowledge to distinguish their difference. Leveraging the power of LLMs, we show that, for the first time, the likelihood ratio can serve as an effective OOD detector. Moreover, we apply the proposed LLM-based likelihood ratio to detect OOD questions in question-answering (QA) systems, which can be used to improve the performance of specialized LLMs for general questions. Given that likelihood can be easily obtained by the loss functions within contemporary neural network frameworks, it is straightforward to implement this approach in practice. Since both the pretrained LLMs and its various finetuned models are available, our proposed criterion can be effortlessly incorporated for OOD detection without the need for further training. We conduct comprehensive evaluation across on multiple settings, including far OOD, near OOD, spam detection, and QA scenarios, to demonstrate the effectiveness of the method.
4/16/2024